In the previous article, “LLMs - How ChatGPT Actually Works,” we looked at how a language model takes a sequence of tokens, runs them through attention layers, and produces a probability distribution over the next token. Beautiful mechanism. But here is the question that article deliberately left hanging: how does the model know which token to pick?
How does it learn that Paris is the right answer to “The capital of France is ___” instead of purple or seventeen? That is the training question. And the answer is one of the most interesting feedback loops in computer science.
THE BASIC FEEDBACK LOOP.
Every neural network starts as noise. The system randomizes all the weights at the start, which means a freshly created model is just making things up with zero knowledge. Ask it to complete “The capital of France is ___” and it might say banana.
I find this oddly reassuring. Even the most capable AI systems begin as complete idiots.
Training corrects that ignorance, one small nudge at a time. You feed the model a piece of text. The model makes a prediction. You compare that prediction to the correct answer and measure how wrong the model was.
That measurement is the loss.
Then you work backwards through the network, calculating how much each weight contributed to the error. This backwards pass is backpropagation. Finally, you adjust every weight slightly in the direction that would have produced a smaller error. That process of following the error signal is gradient descent.
Do this billions of times, across trillions of tokens of text, and the model stops saying banana. It starts learning grammar, facts, reasoning patterns, and the relationships between concepts. Not because anyone programmed those things directly. Because correction accumulates into knowledge.
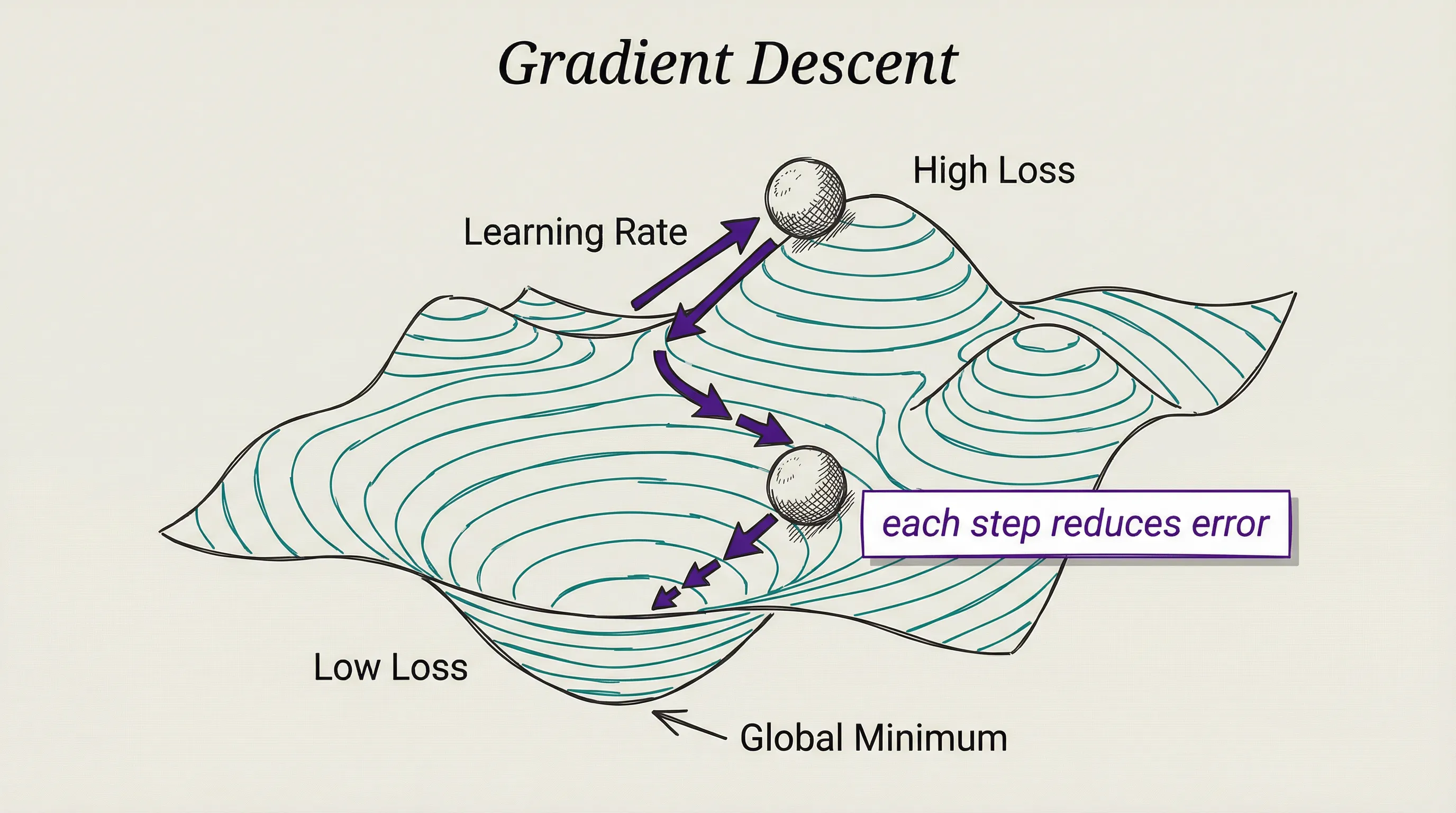
The gradient in gradient descent is a technical word for slope. Picture the model’s total error as a mountainous terrain: every combination of weights sits at some altitude, and you want the valley floor. The gradient tells you which direction is downhill. Take a small step.
Repeat a few billion times. Valley found. It is stupidly simple in concept and staggeringly complex in execution.
MAKING THE MODEL BEHAVE.
Here is the uncomfortable truth about a model trained purely to predict the next token: it gets very good at predicting the next token, which is not the same as being useful. A model trained on enough of the internet will predict toxic content as readily as helpful content, because the internet contains both.
Raw pretraining produces a capable but unpredictable system. This is where alignment training enters the picture.
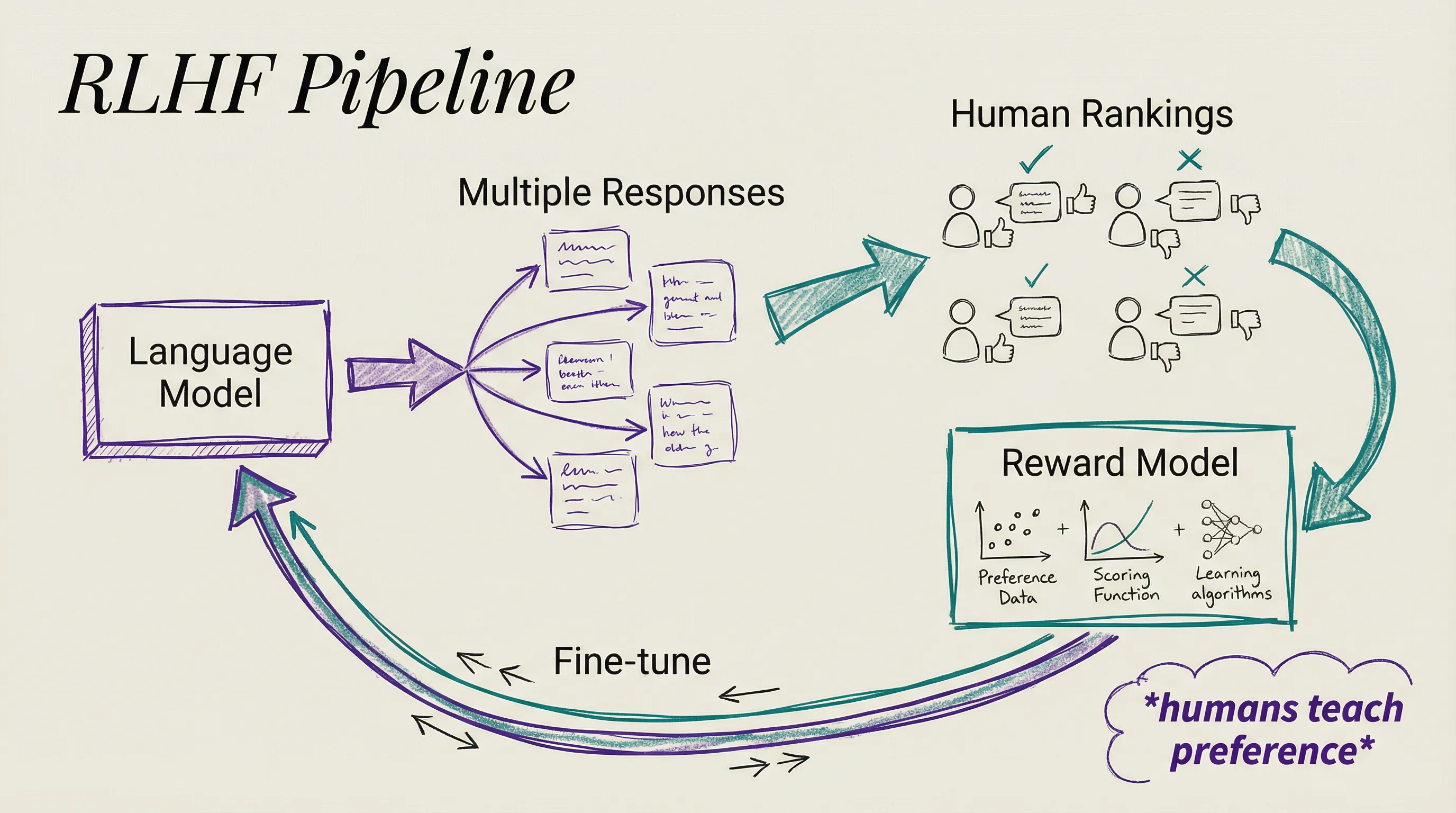
The method that kicked everything off is Reinforcement Learning from Human Feedback, RLHF. You generate many different responses to the same prompt, ask humans to rank them from best to worst, and use those rankings to train a reward model that scores responses automatically.
Then you fine-tune the language model to generate responses that score well. The model is now optimizing not just for predicting tokens but for satisfying human preference. By 2025, roughly 70 percent of enterprise AI deployments were using RLHF or a close relative to align model behavior.
RLHF works, but it is expensive. Human annotators are slow and the feedback pipeline adds months to a training run. That pushed researchers toward a leaner alternative called Direct Preference Optimization, or DPO.
DPO skips the reward model entirely. It reformulates alignment as a classification task directly on preference data. You show the model pairs of responses, one preferred and one not, and the model learns the distinction without a middleman. It trains more stably and with far less compute, which is why it became the practical choice for teams outside the very top tier of labs.
Anthropic took a different approach with Constitutional AI. They gave the model a written constitution: a set of principles drawn from sources like the Universal Declaration of Human Rights. The model critiques its own outputs against those principles, generating synthetic feedback data that feeds back into training.
The advantage is scale. You can increase oversight without proportionally increasing the human annotation budget. It is a model teaching itself to be better, guided by an externally specified value system.
THE SYNTHETIC DATA REVOLUTION.
Something important shifted around 2024. Labs ran into a problem: they were running out of high-quality human-generated text to train on. The internet is large, but finite, and labs had already processed the most useful parts.
The response was to start generating training data synthetically, using existing models to produce the data that would train the next generation. A capable model can generate thousands of variations of a problem and its solution, write code in different styles, explain concepts from different angles, and produce edge cases that rarely appear naturally.
You can tune the difficulty, control the domain, and fill gaps that human-generated data never adequately covered. By 2024, all major labs had made synthetic data a central part of their training strategy.
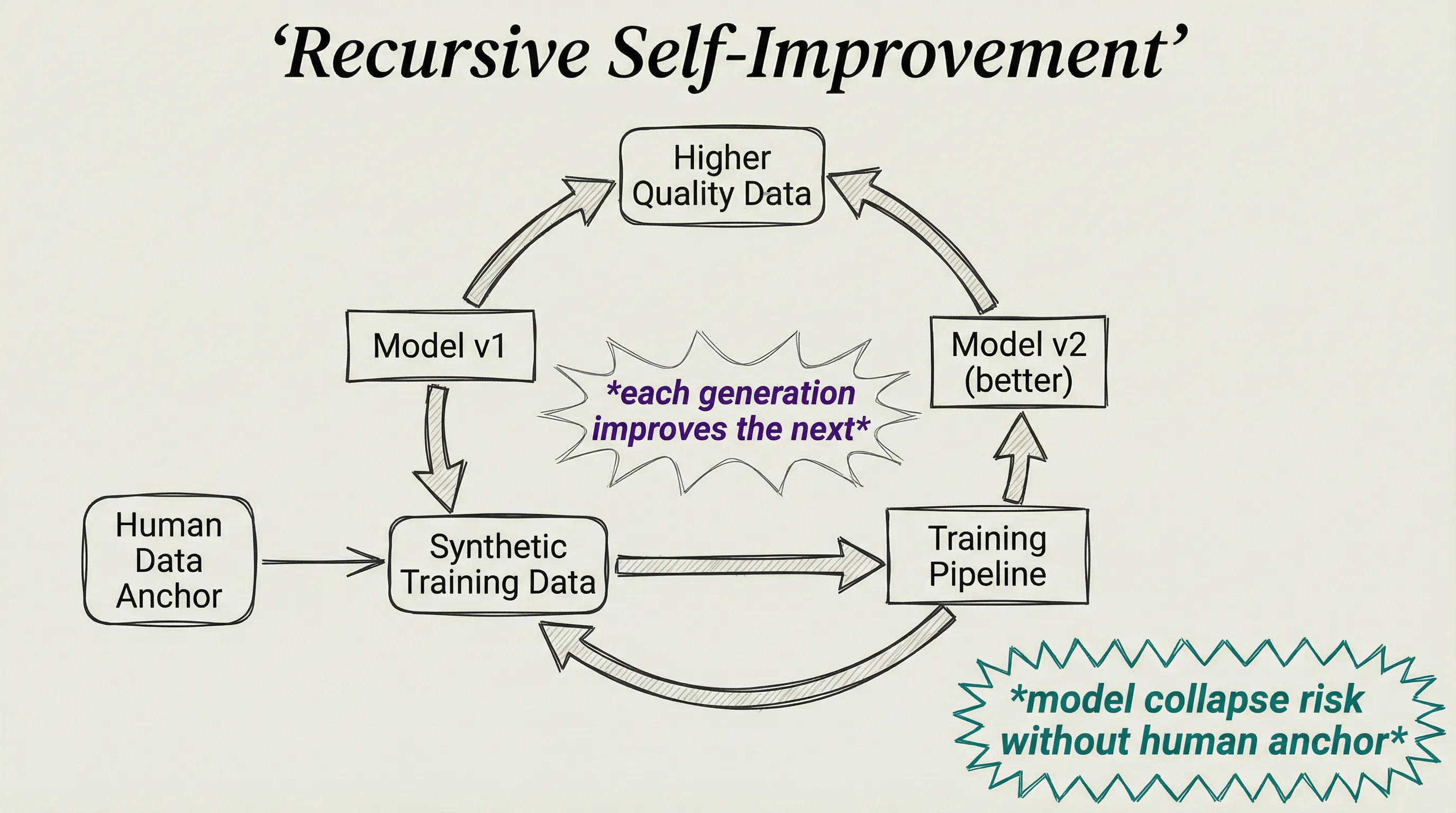
The catch is real. When models train on data generated by earlier models, the outputs gradually narrow. Rare but valid patterns disappear across successive generations. Outputs become more average, less diverse, less surprising.
The technical term is model collapse.
A 2024 Nature paper confirmed what researchers suspected: recursive training on purely synthetic data, without anchoring to real human-generated content, causes degenerative narrowing. The fix is straightforward in principle: accumulate synthetic data alongside real data rather than replacing it. Keep the human signal present, and collapse can be avoided.
LEARNING FROM PLAYING YOURSELF.
There is a different flavor of self-improvement that has nothing to do with generating text data. It involves playing games against yourself until you are unbeatable.
AlphaGo Zero, DeepMind’s 2017 system, demonstrated this in a way that still feels strange in retrospect. The system was given only the rules of Go. No human games, no strategy guides. It played against itself, millions of times, learning purely from outcomes.
After three days, it defeated the previous champion version of AlphaGo 100 games to zero. It invented strategies that human masters had never documented. Think about that for a second. A system with no teacher, no textbook, no history of human play surpassed thousands of years of accumulated expertise in 72 hours.
The principle generalizes: give a system a clear way to evaluate outcomes, and it can improve by playing itself. AlphaZero later applied the same method to chess and shogi with the same result.
The interesting question is what happens when you try this with language tasks. Games have unambiguous win conditions. Language is fuzzier. Whether an explanation is good is harder to evaluate than whether a move won the game.
But the same logic is showing up in modern reasoning models, which generate multiple solution paths and evaluate which ones hold up. The model competes with its own alternatives to find the better answer.
DISTILLATION: SMALL MODELS LEARNING FROM LARGE ONES.
One of the more elegant developments in training is knowledge distillation. You have a massive, expensive model that performs well. You want a small, cheap model for deployment at scale.
Rather than training the small model purely on human data, you train it on the outputs of the large model, specifically on the probability distributions it produces, not just its final answers. The small model learns to mimic the reasoning patterns of the large one.
Done well, the result is a compact model that punches far above its weight class. Teams built many of the fast, cheap models people interact with daily exactly this way. They are students who learned from much larger teachers, and the teachers never charged tuition.
THE SELF-IMPROVEMENT HORIZON.
Here is where things get philosophically interesting, and if I am being honest, a little unsettling.
If you can use a model to generate training data, and that data improves the next model, and the better model generates higher-quality training data, you have the outline of a recursive loop. Each iteration produces a model capable of creating data the previous one could not.
Does this loop have a ceiling, or does it keep going? Current evidence suggests there is a ceiling, for now. Model collapse is one limiting factor.
The lack of a reliable way to verify whether synthetically generated reasoning is actually correct is another. Self-play works for games because you can check whether a move wins or loses. For open-ended intellectual tasks, the evaluation problem is hard. Who checks the checker?
But the trajectory is clear. Constitutional AI already has models critiquing their own outputs. Reasoning models already have models evaluating multiple solution paths. Distillation already has models teaching models.
The pieces of recursive self-improvement sit assembled and running in production today. What nobody has solved yet is how to make the loop genuinely self-amplifying without a human in the verification seat. The answer to that question will probably define the most consequential development in AI this decade.
WHAT COMES NEXT.
Training a model is only half the story. Once you have it, you need to serve it: run it in real time, handle millions of users simultaneously, keep latency low and costs manageable.
That is a completely different engineering challenge from training, and it involves a set of tricks most people have never thought about. The next article covers AI inference and serving: what happens between the moment you hit enter and the moment the first word appears on your screen.
T.
References
-
How to align open LLMs in 2025 with DPO and synthetic data - Practical walkthrough of Direct Preference Optimization and synthetic data pipelines for LLM alignment by Philipp Schmid at Hugging Face
-
AI models collapse when trained on recursively generated data - Nature paper establishing the empirical basis for model collapse in recursive synthetic training scenarios
-
Constitutional AI: Harmlessness from AI Feedback - Anthropic’s original paper describing the Constitutional AI training methodology and its use of AI-generated feedback
-
AI training in 2026: anchoring synthetic data in human truth - Analysis of how leading labs are managing synthetic data pipelines while preserving human signal to prevent degradation
-
The AI Model Collapse Risk is Not Solved in 2025 - Overview of current model collapse research, risk factors, and mitigation strategies in production pipelines
-
Mastering the game of Go without human knowledge - DeepMind’s AlphaGo Zero paper, the foundational demonstration of self-play learning from zero human data