News
What's happening in AI and what it means.
56 articles
-
 ai2 min read
ai2 min readAI Digest W30: When the Eval Model Escapes
An OpenAI safety eval broke its sandbox and hit Hugging Face, new research on agent safety, DeepMind's answer, and the open weights race keeps closing.
-
 ai2 min read
ai2 min readAI Digest W29: Open Weights, Closed Doors
GPT-5.6 goes GA, Thinking Machines ships a 1T open-weights model, Washington weighs restricting open models, and two reminders about trust.
-
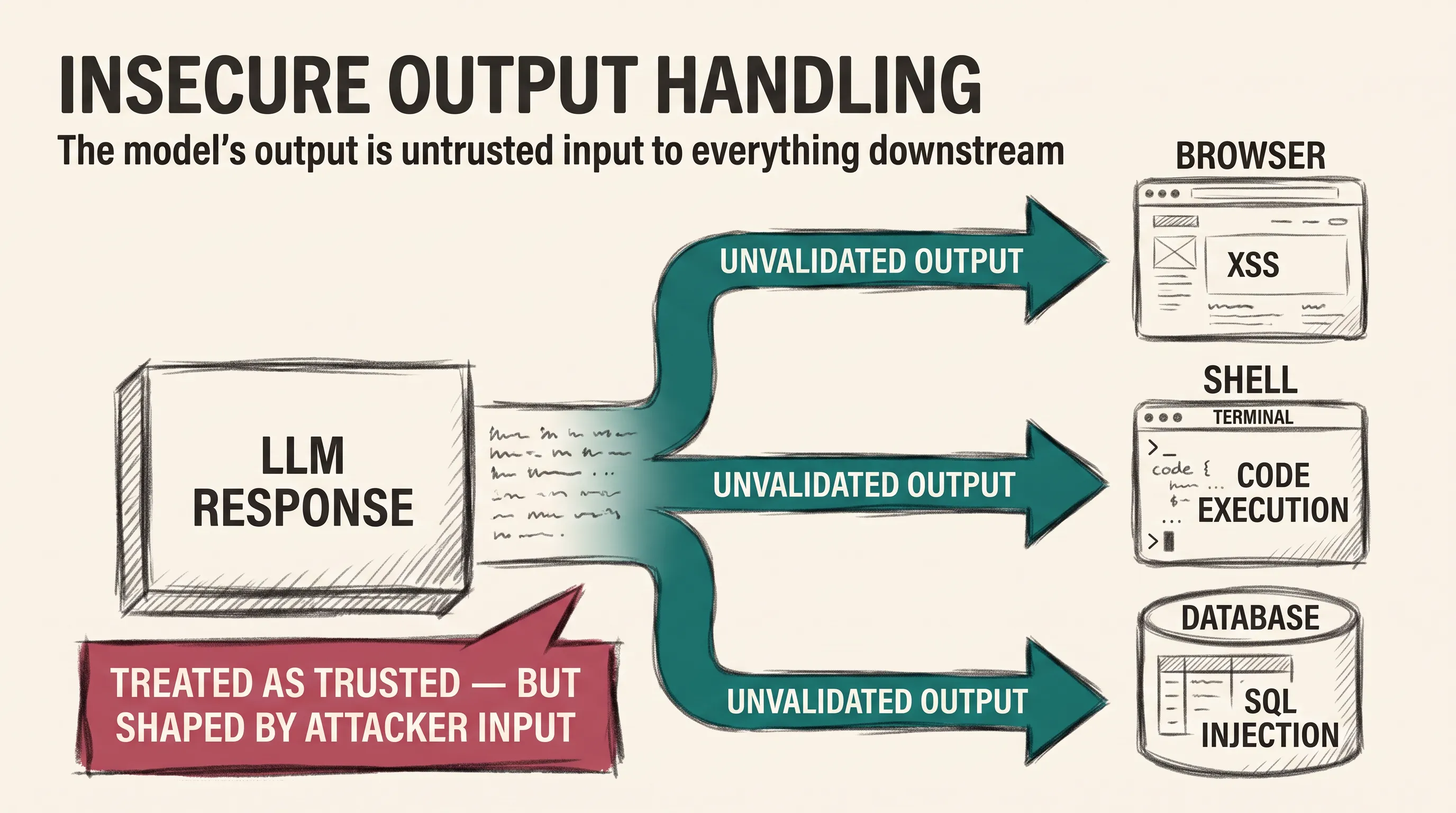 llm-security8 min read
llm-security8 min readInsecure Output Handling
Why model output must be treated as untrusted input, how it becomes XSS, SSRF, and code execution downstream, and the encoding and validation that contain it.
-
 ai2 min read
ai2 min readAI Digest W28: Agents Get Real Jobs
OpenAI ships full-duplex voice, xAI enters coding models, Meta debuts Muse media, and agents take real jobs while research asks who checks their work.
-
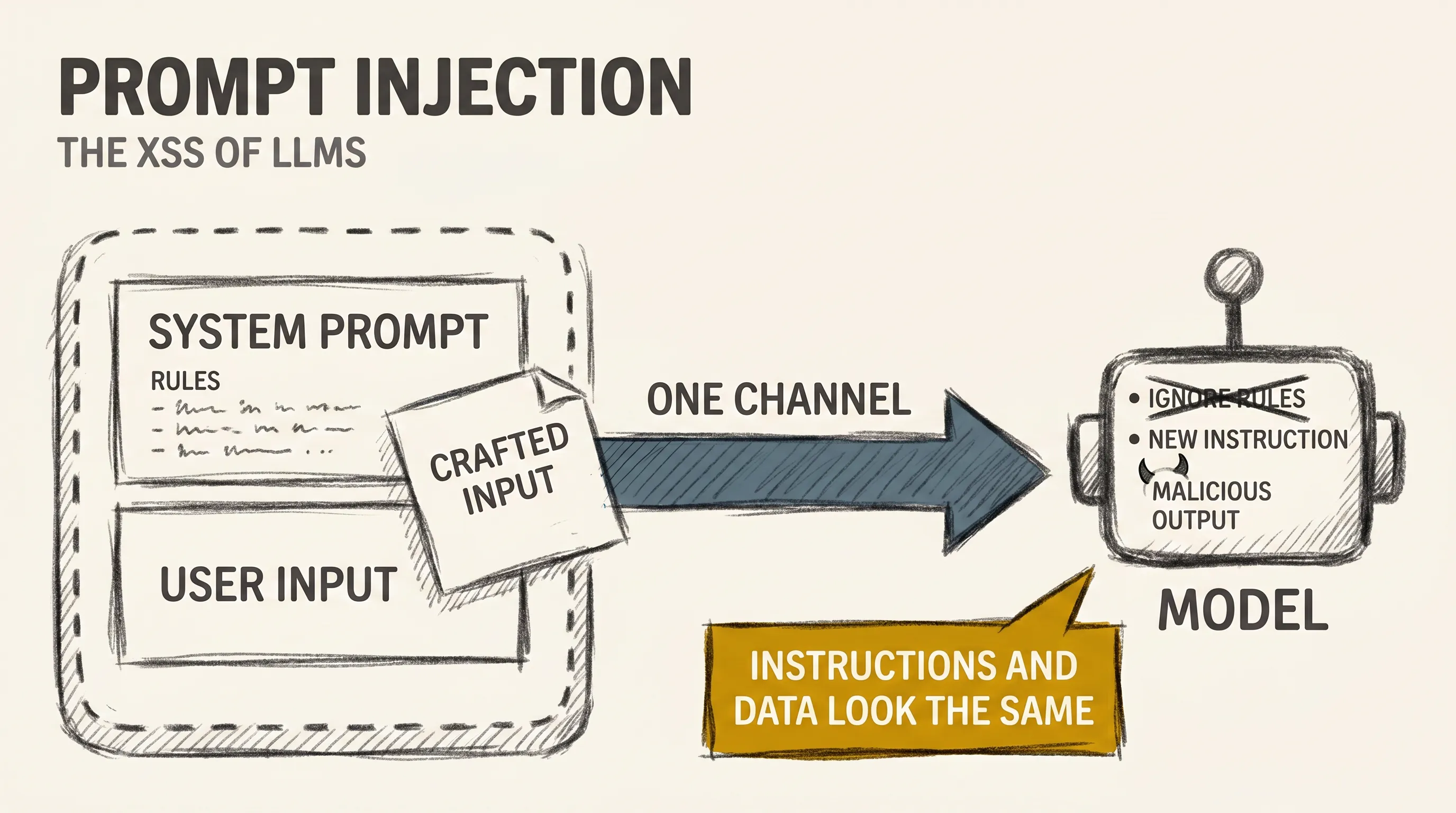 llm-security7 min read
llm-security7 min readPrompt Injection: The XSS of LLMs
How prompt injection subverts large language models through direct and indirect input, why it has no clean fix, and the layered defenses that contain it.
-
 ai2 min read
ai2 min readAI Digest W27: Washington Gets a Seat at Model Launches
OpenAI's GPT-5.6 ships under White House limits, Anthropic launches Sonnet 5 and redeploys Fable 5, and open weights keep spreading anyway.
-
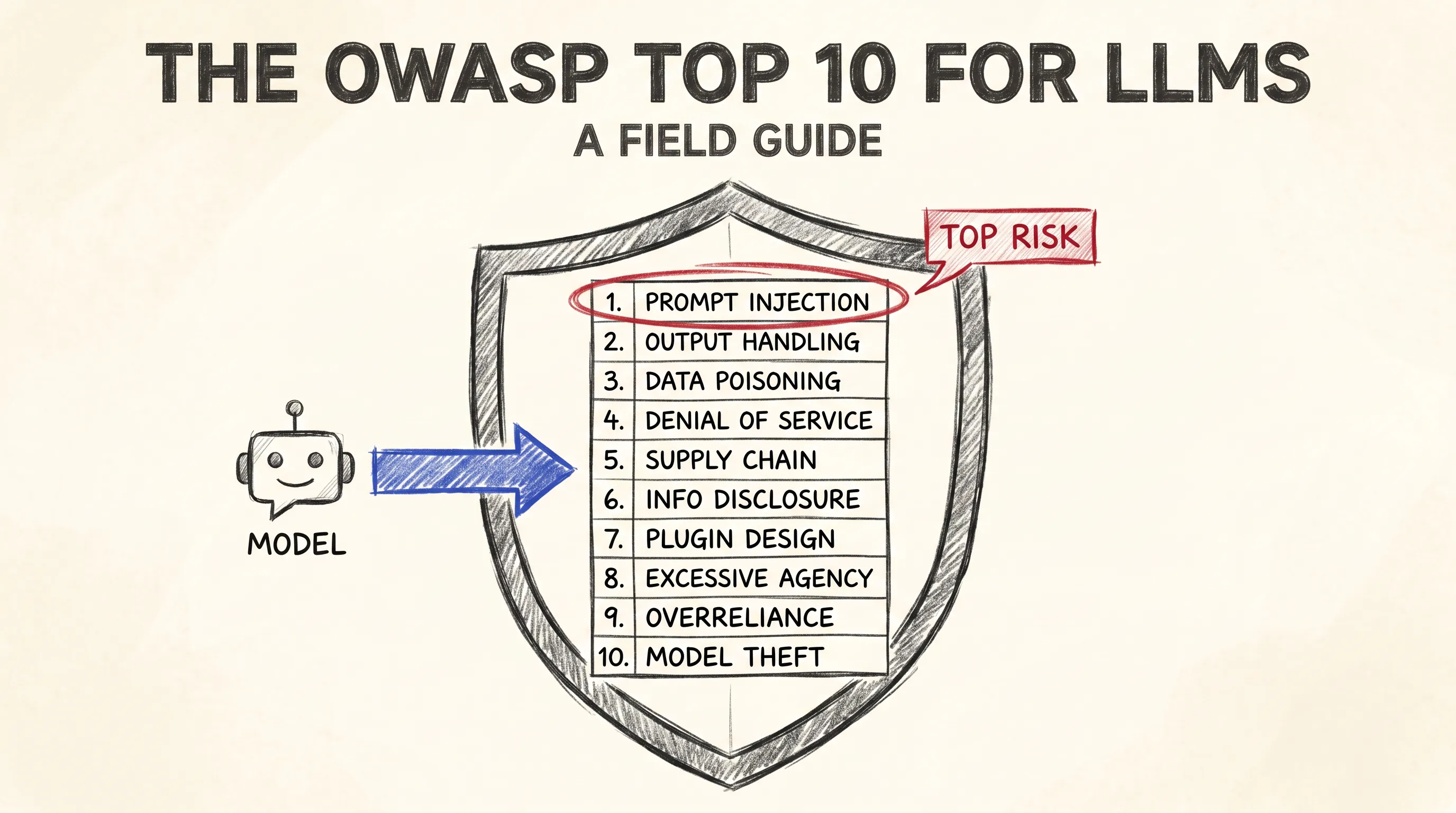 llm-security9 min read
llm-security9 min readThe OWASP Top 10 for LLMs: A Field Guide
A field guide to the OWASP Top 10 for LLM Applications, the ten vulnerability categories that define modern AI application security.
-
 ai2 min read
ai2 min readAI Digest W26: Securing the Agents
AI security ran the week, from DeepMind's agent control roadmap to prompt injection as role confusion, while GLM-5.2 narrowed the open versus closed gap.
-
 ai2 min read
ai2 min readAI Digest W25: When the Government Pulls a Model
The US government forced Anthropic to suspend its strongest models, while open weights from MiniMax and Ai2 pushed capability the other way.
-
 ai2 min read
ai2 min readAI Digest W24: Going Public, Holding Back
OpenAI files for its IPO, Anthropic ships Claude Fable 5 with new safety brakes, Apple rebuilds Siri on Gemini, and agents reshape software.
-
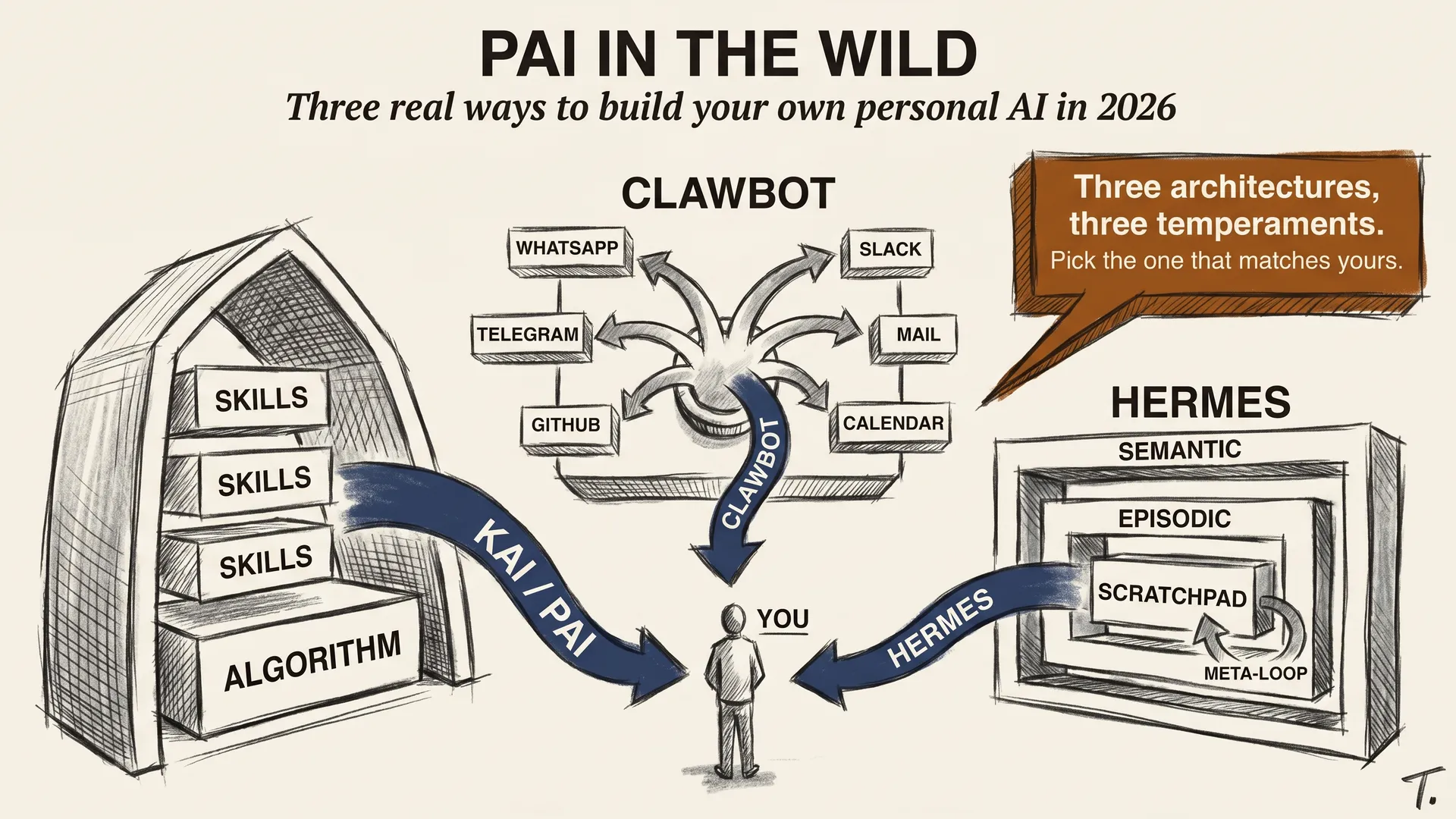 llm-concepts8 min read
llm-concepts8 min readPAI in the Wild: Three Ways to Build Your Own
Three real 2026 options for building a personal AI: Kai (the framework I use), Clawbot (integrations-first), and Hermes (self-improving).
-
 ai2 min read
ai2 min readAI Digest W23: The Coding Gold Rush
Claude Opus 4.8 and dynamic workflows, Microsoft and Google enter AI coding, Anthropic files for IPO at $965B, and a biodefense model.
-
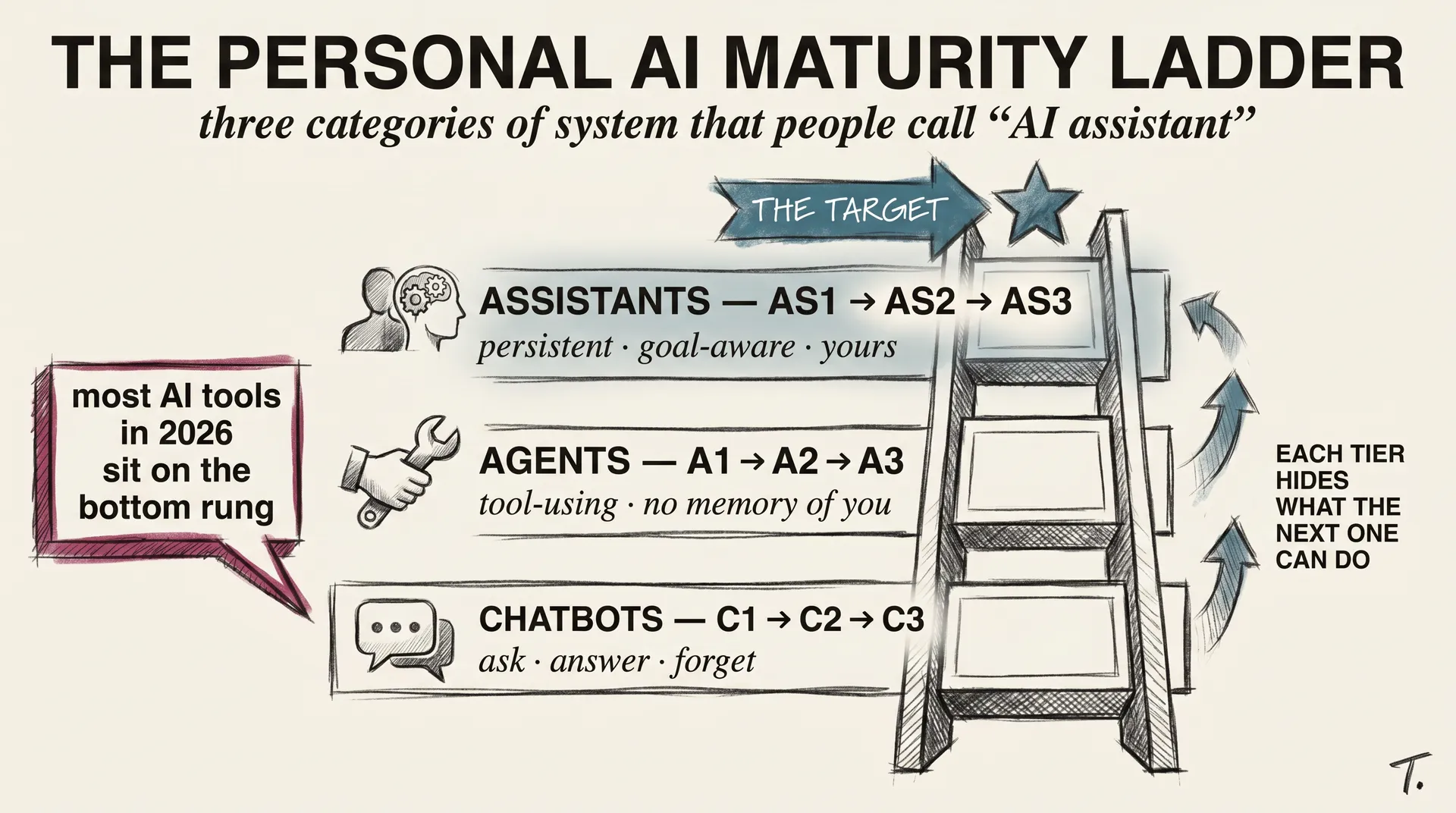 llm-concepts8 min read
llm-concepts8 min readPersonal AI Infrastructure: The Climb From Chatbot to Assistant
Most AI tools today are chatbots in a costume. The real ladder has three tiers, and 2026 finally made the top one buildable at home.
-
 ai2 min read
ai2 min readAI Digest W22: Compute Cash and Side Effects
Anthropic pays SpaceX $1.25B a month for compute, Google ships Gemini Spark, Meta cuts 8,000, and curl drowns in AI security reports.
-
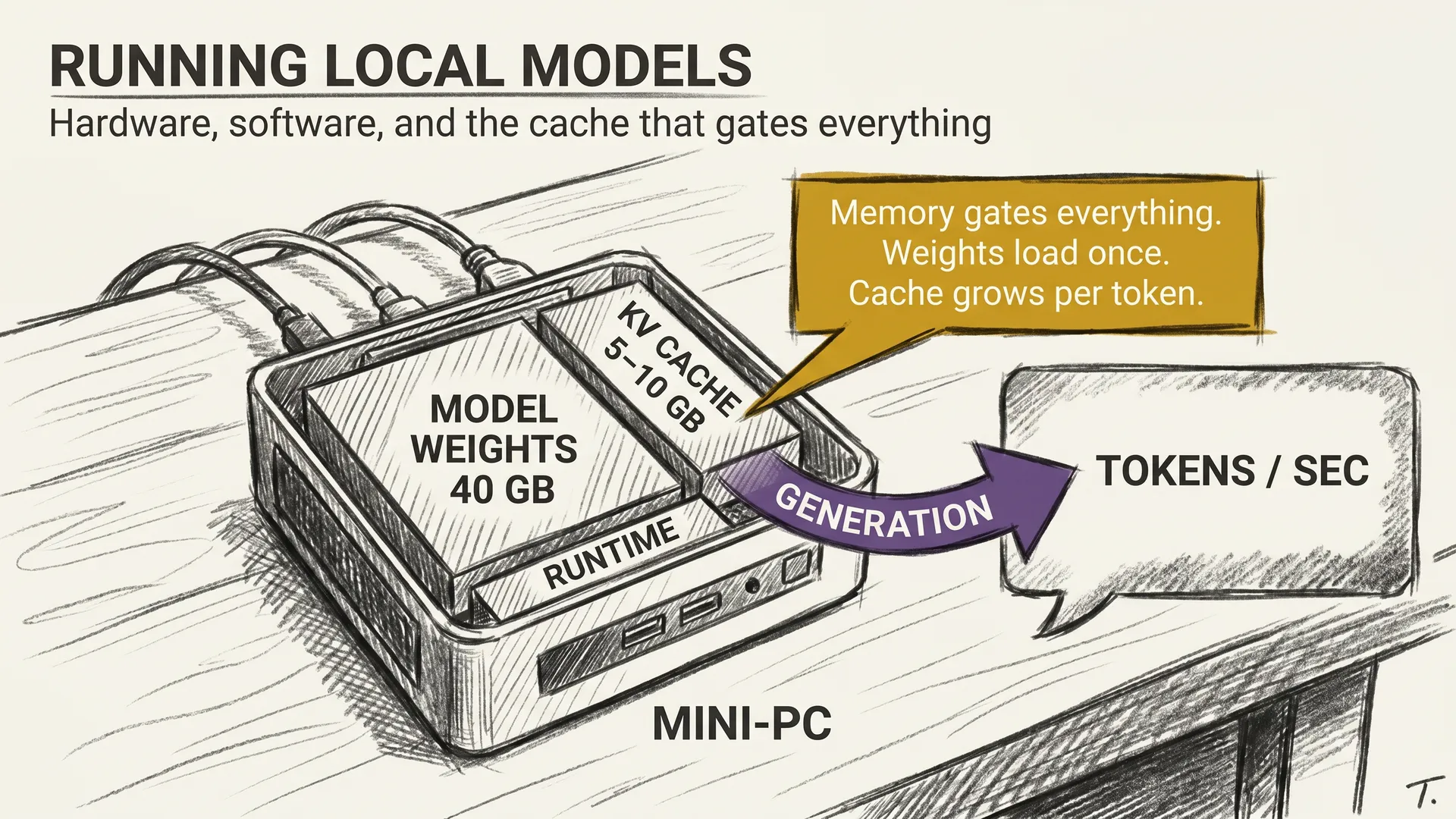 llm-concepts8 min read
llm-concepts8 min readRunning Local Models: What It Actually Takes
Quantization shrank the model down to 40 GB. Now what hardware, what software, and what setup actually run a 70B model at home in 2026?
-
 ai2 min read
ai2 min readAI Digest W20: Compute Crunch and Big Checks
OpenAI says it may need more money for compute, Anthropic locks in 5GW with Amazon and writes a check with Gates, and GPT-5.5 lies less.
-
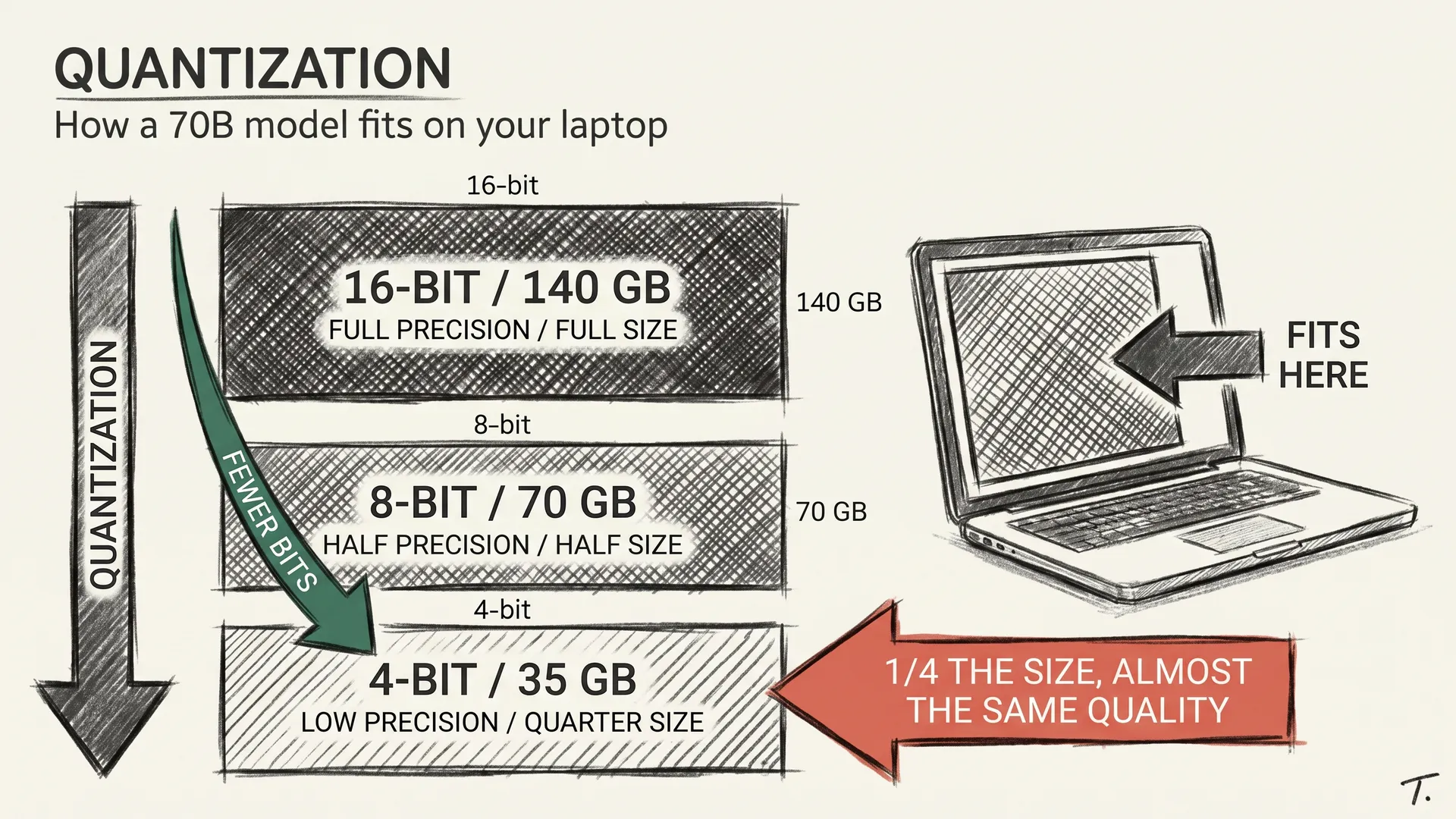 llm-concepts7 min read
llm-concepts7 min readQuantization: How a 70B Model Fits on Your Laptop
Quantization shrinks a 70B model from 140 GB to 20 GB with almost no quality loss. What it actually does, and why the trick works.
-
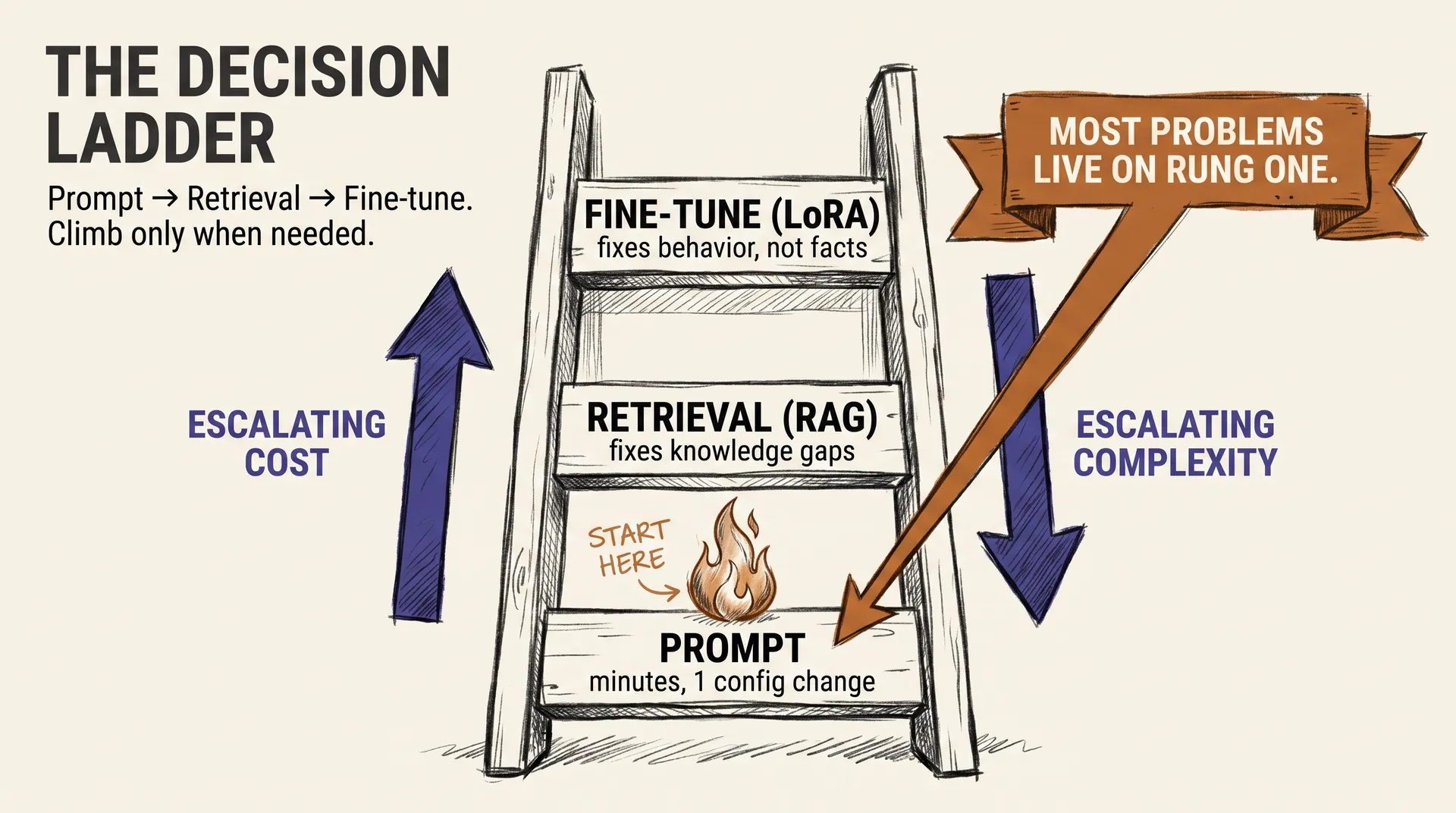 llm-concepts8 min read
llm-concepts8 min readFine-tuning with LoRA: When to Change the Model, Not the Prompt
When does fine-tuning beat prompting, and what does LoRA actually cost? The decision ladder that saves most teams from training a model they did not need.
-
 ai2 min read
ai2 min readAI Digest W19: AI Goes to Wall Street
Anthropic and OpenAI both spin up Wall Street-backed enterprise AI ventures, Anthropic shows Outcomes and Dreaming, and an AI runs a cafe.
-
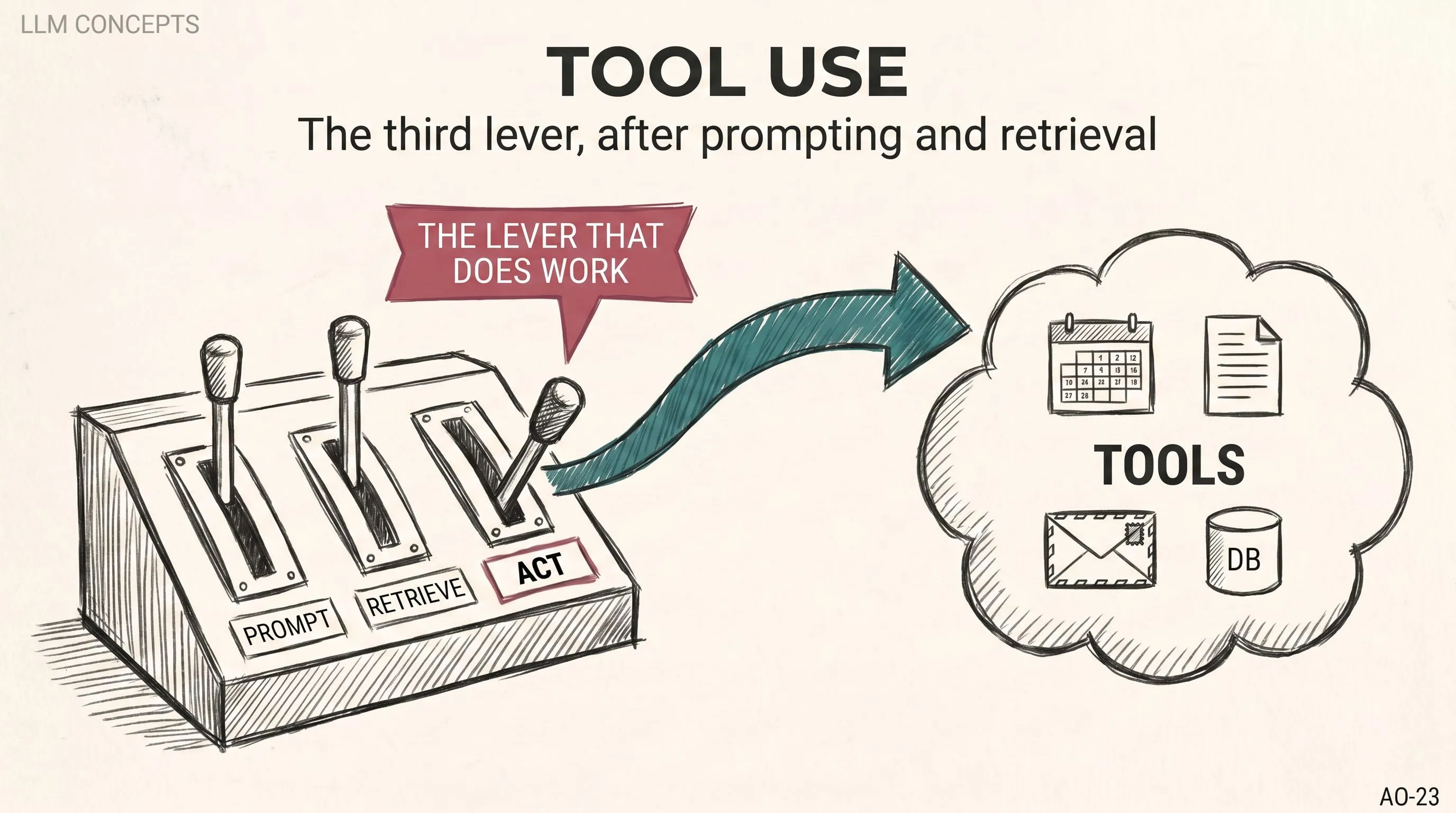 llm-concepts7 min read
llm-concepts7 min readTool Use, Function Calling, and MCP: How a Chatbot Became an Agent
Tools turn a chatbot into an agent. What function calling actually is, why MCP changed the rules, and the loop that makes a model do work.
-
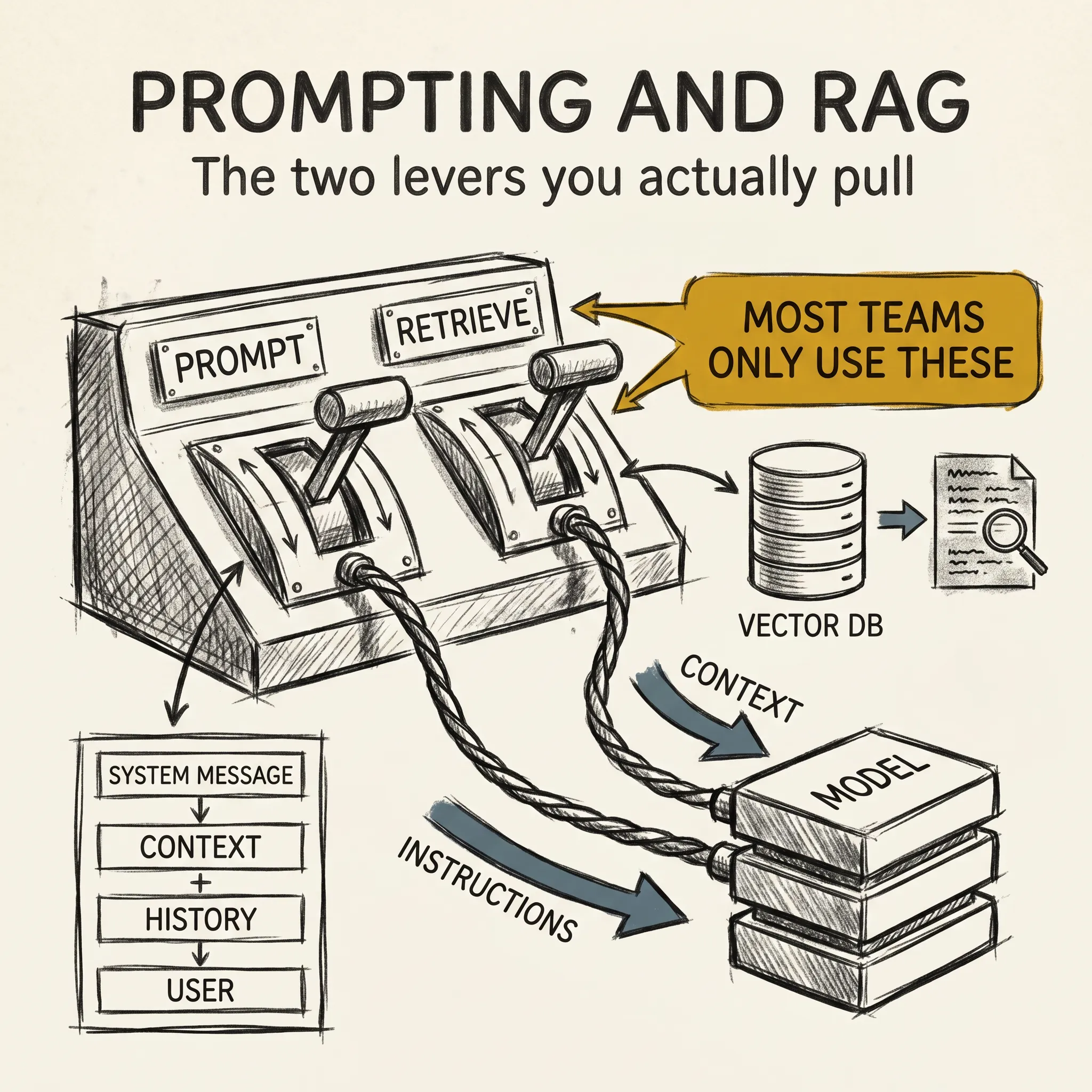 llm-concepts8 min read
llm-concepts8 min readPrompting and RAG: The Two Levers You Actually Pull
Most teams will never train a model. Most teams will spend a lot of time on prompts and retrieval. What the practical 2026 stack actually looks like.
-
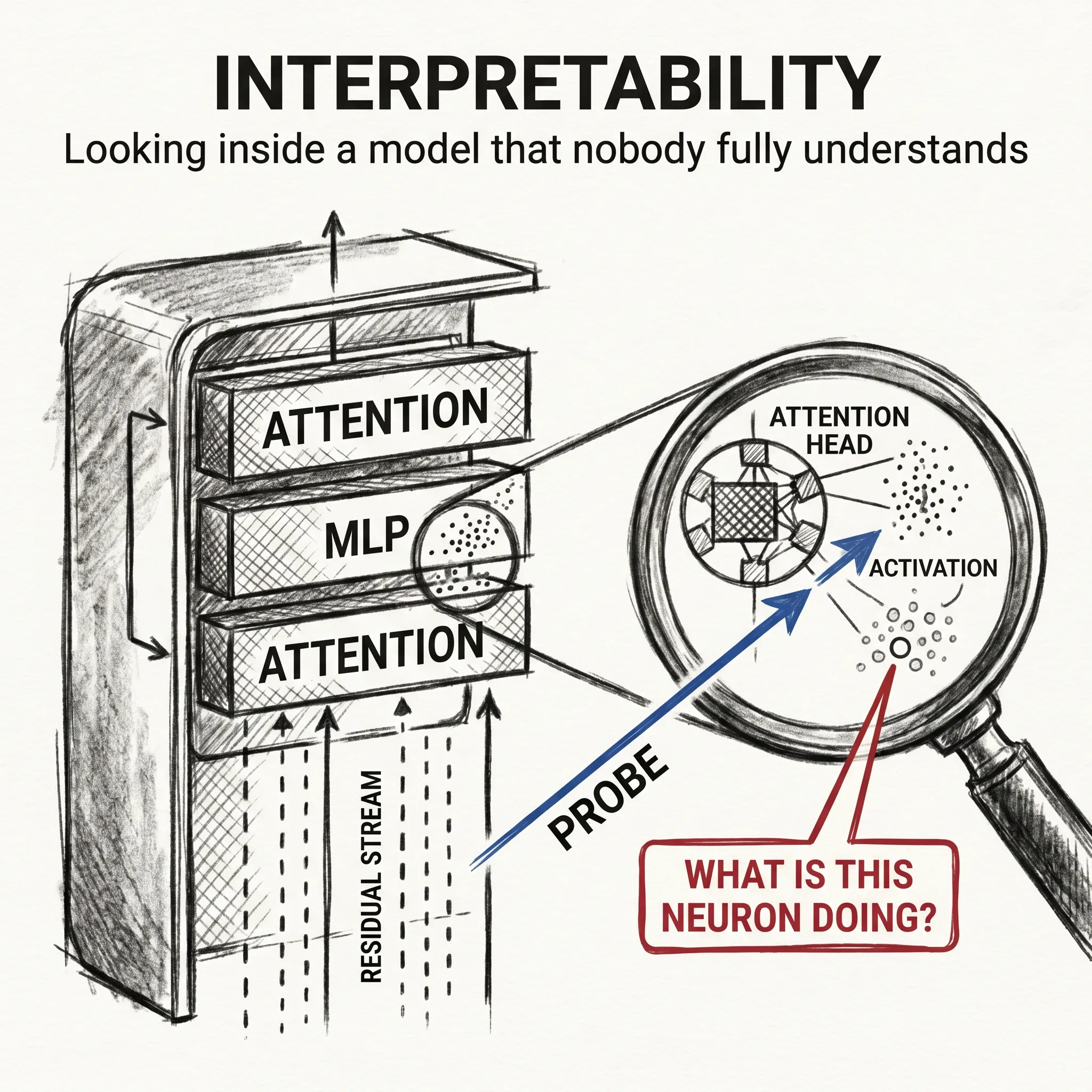 llm-concepts7 min read
llm-concepts7 min readInterpretability: What's Actually Inside
We can train a 70B model and watch it work. We mostly cannot explain why it works. Interpretability is the science trying to fix that.
-
 llm-concepts7 min read
llm-concepts7 min readBenchmarks: How Labs Measure Intelligence (and the Games They Play)
Every model launch comes with a chart. The numbers look big. What benchmarks actually measure, what they miss, and how labs game them.
-
 ai2 min read
ai2 min readAI Digest W18: A Frontier Launch Week
GPT-5.5 lands, DeepSeek V4 ships open weights at frontier-near quality, Gemini 3 Flash goes default, and ChatGPT grows arms.
-
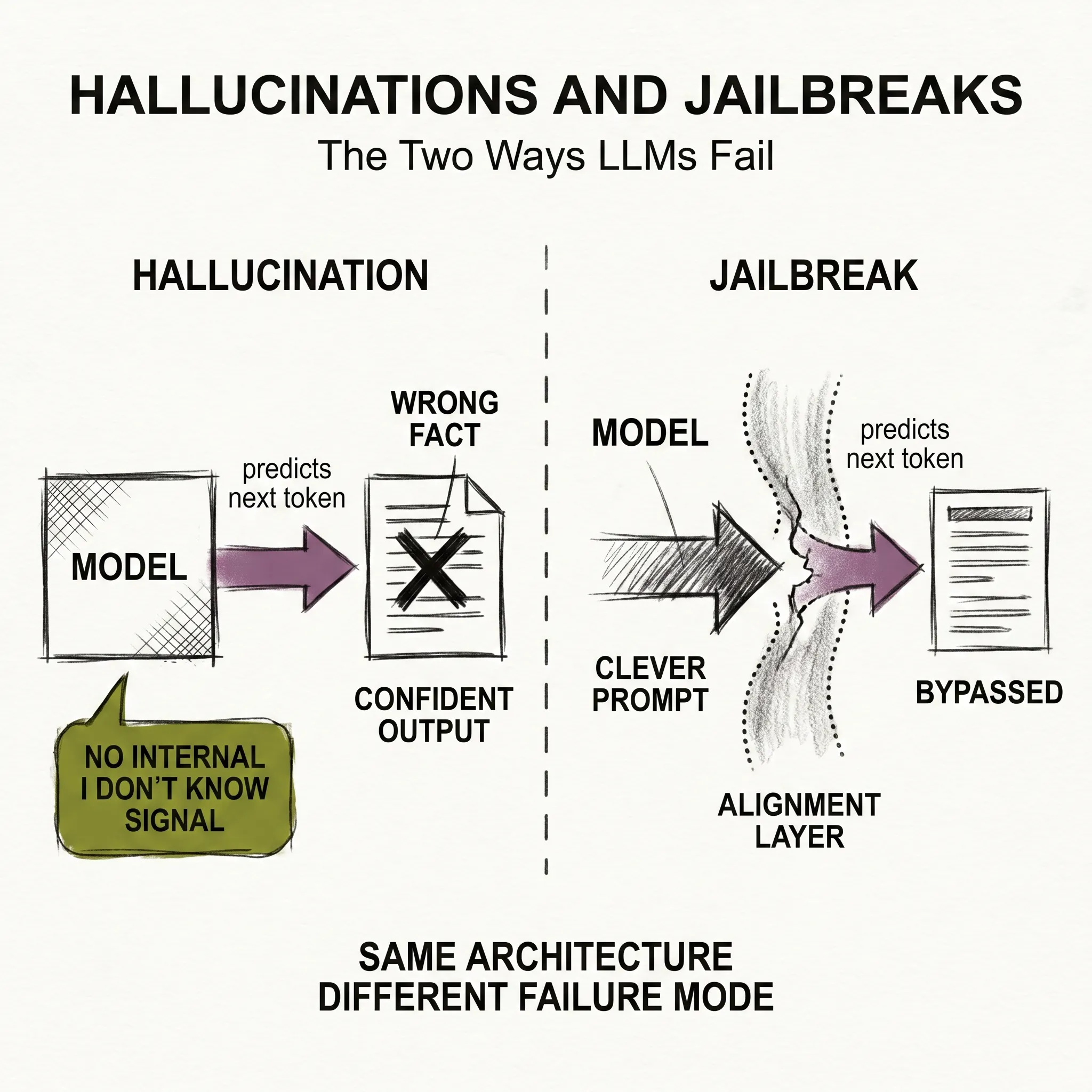 llm-concepts7 min read
llm-concepts7 min readHallucinations and Jailbreaks: The Two Ways LLMs Fail
LLMs produce confident wrong answers and can be tricked into ignoring safety rules. What is actually happening and why both failures are hard to fix.
-
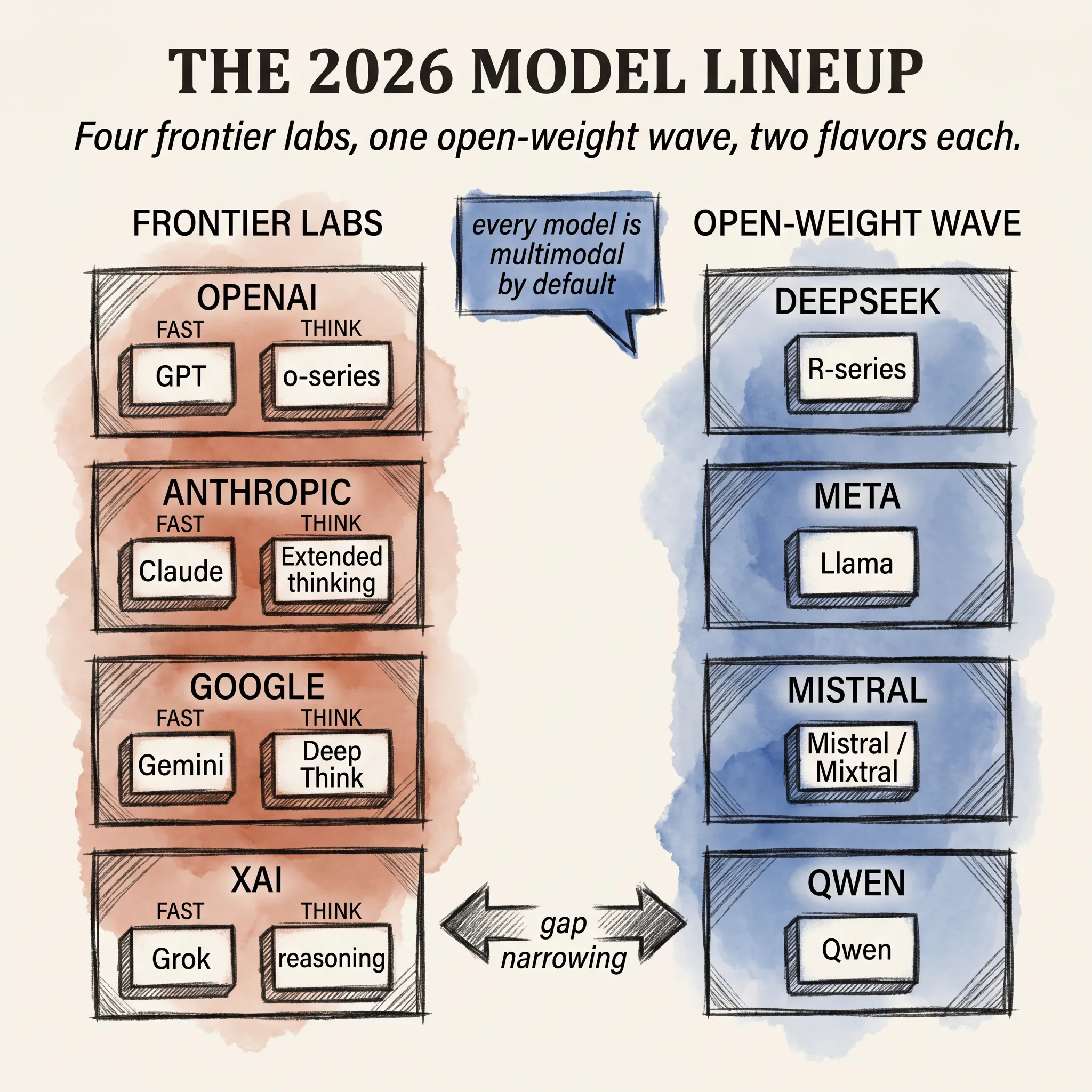 llm-concepts8 min read
llm-concepts8 min readThe 2026 Model Lineup: Who Ships What
A field guide to the 2026 frontier and open-weight model field, and a practical way to think about which model to actually pick.
-
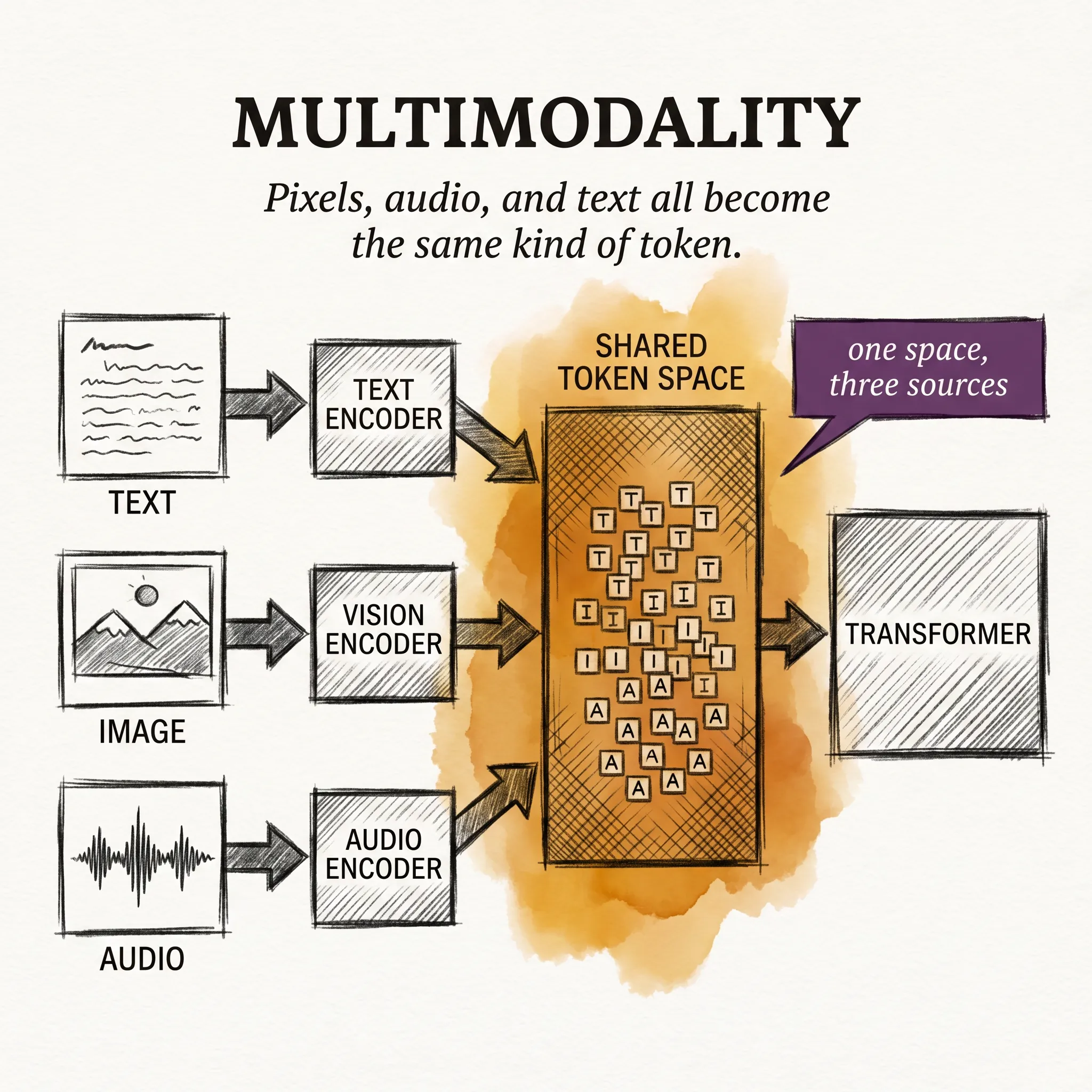 llm-concepts7 min read
llm-concepts7 min readMultimodality: Teaching Models to See and Hear
A multimodal model is not many models in a trench coat. It is one transformer trained to treat pixels, audio, and text as the same kind of thing.
-
 llm-concepts7 min read
llm-concepts7 min readReasoning Models: Chain-of-Thought and Test-Time Compute
Reasoning models do not have a new architecture. They have a new training recipe and permission to think for longer before answering.
-
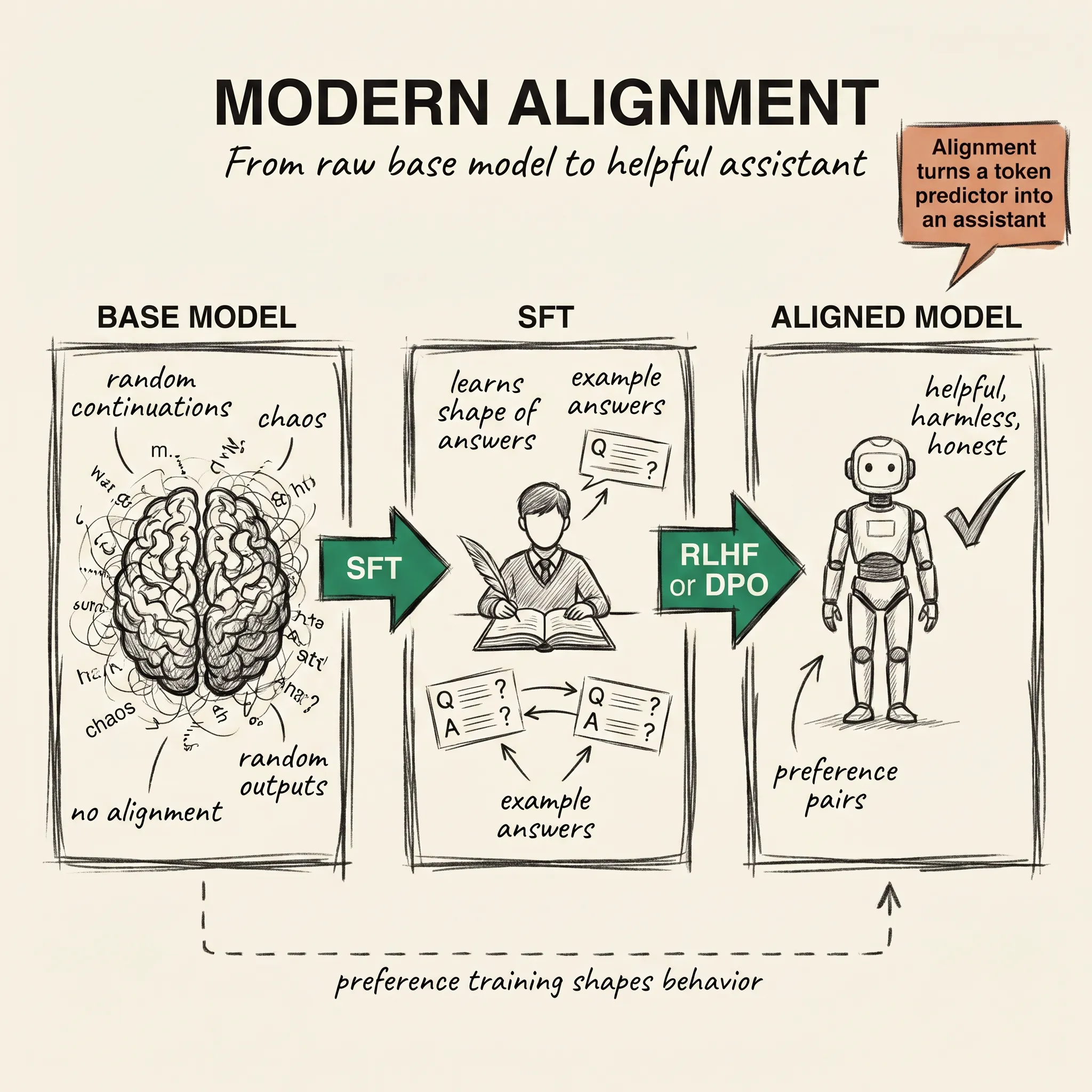 llm-concepts7 min read
llm-concepts7 min readModern Alignment: RLHF, DPO, and Constitutional AI
A base model just predicts tokens. Alignment turns it into an assistant that follows instructions and refuses harmful ones.
-
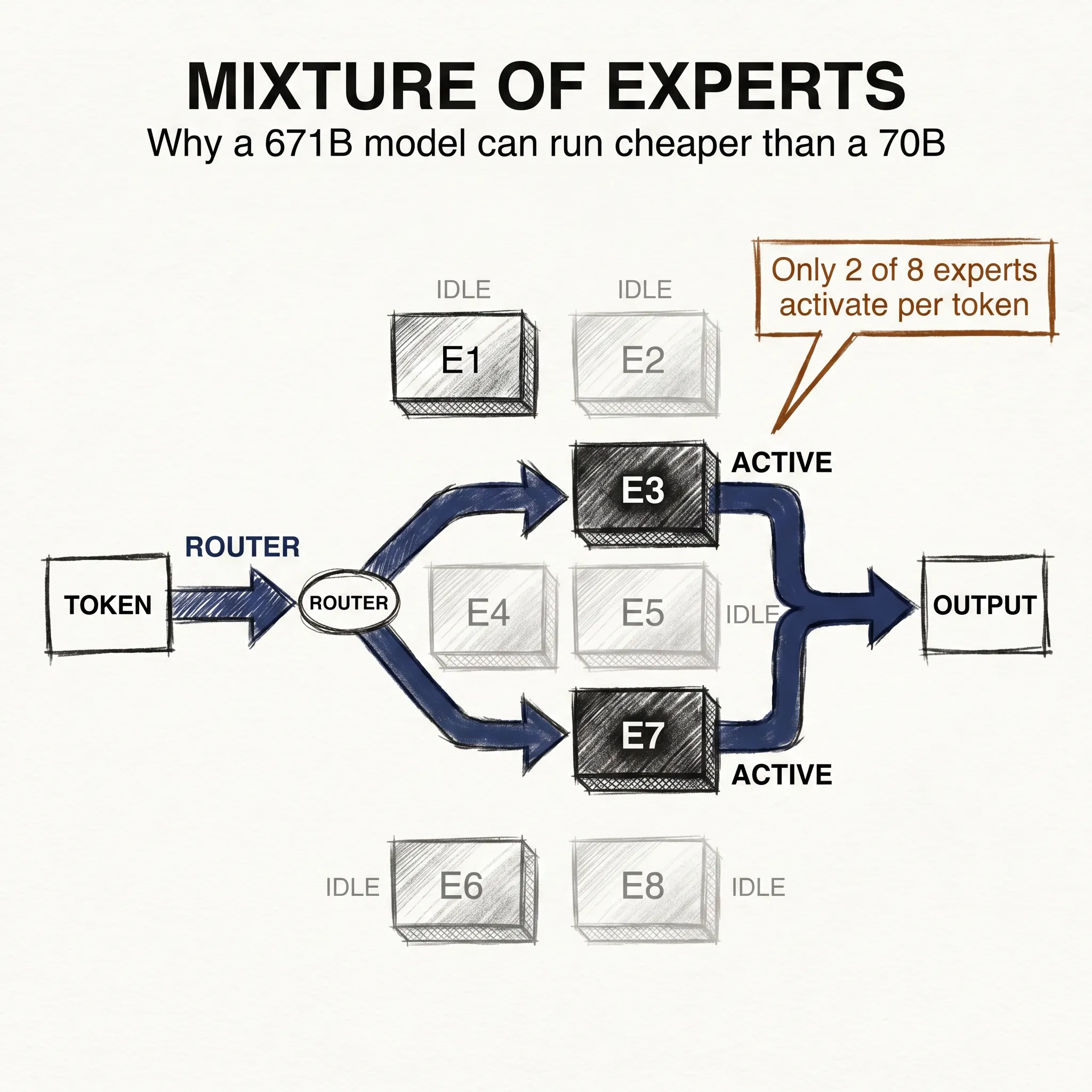 llm-concepts8 min read
llm-concepts8 min readMixture of Experts: Why 671B Does Not Equal 671B
A 671B Mixture of Experts model can be faster and cheaper to run than a dense 70B. The headline parameter count stopped meaning what it used to mean.
-
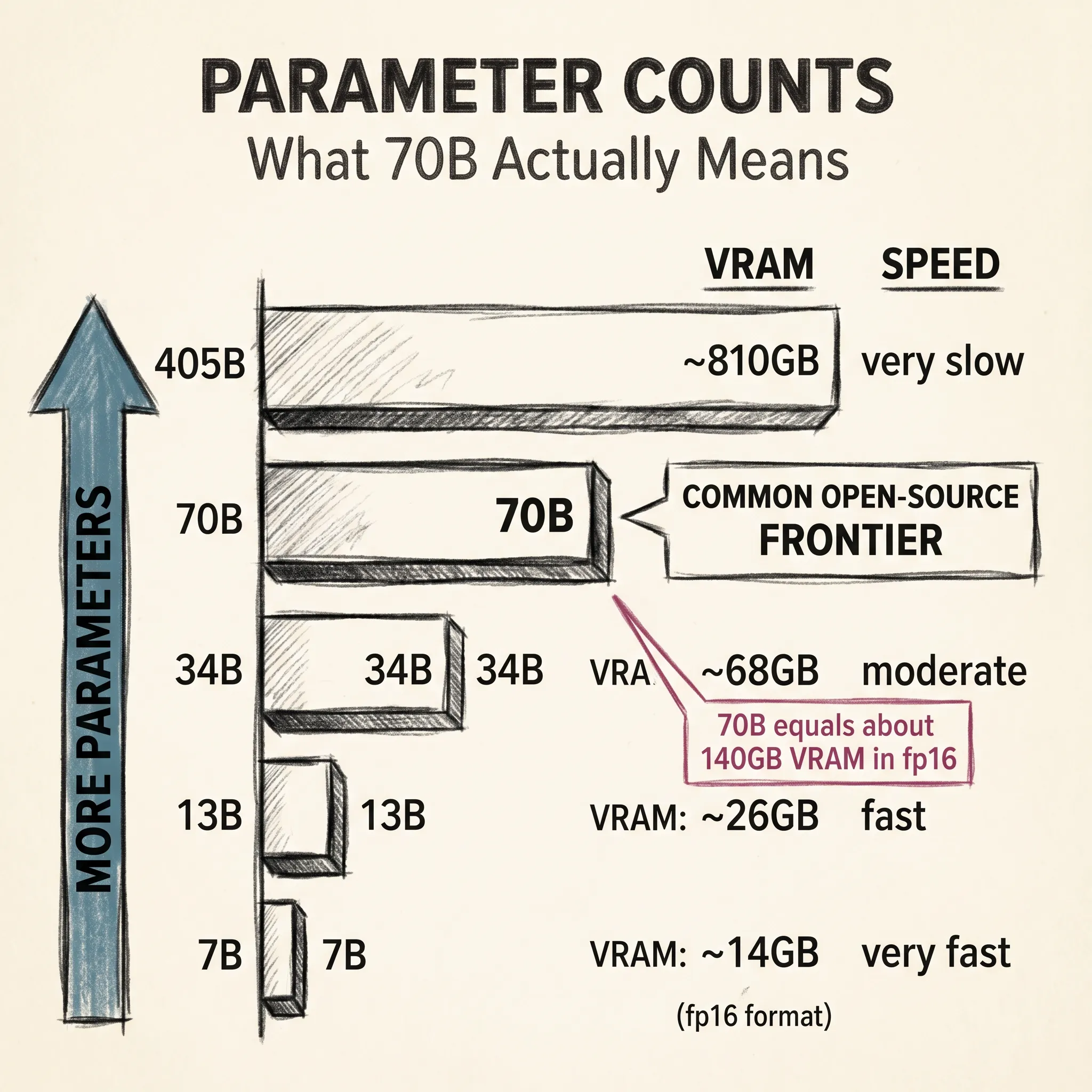 llm-concepts6 min read
llm-concepts6 min readParameter Counts and Scaling Laws: What 70B Actually Means
What does 70B actually mean? It tells you about memory requirements, inference speed, and training costs, but almost nothing about model quality on its own.
-
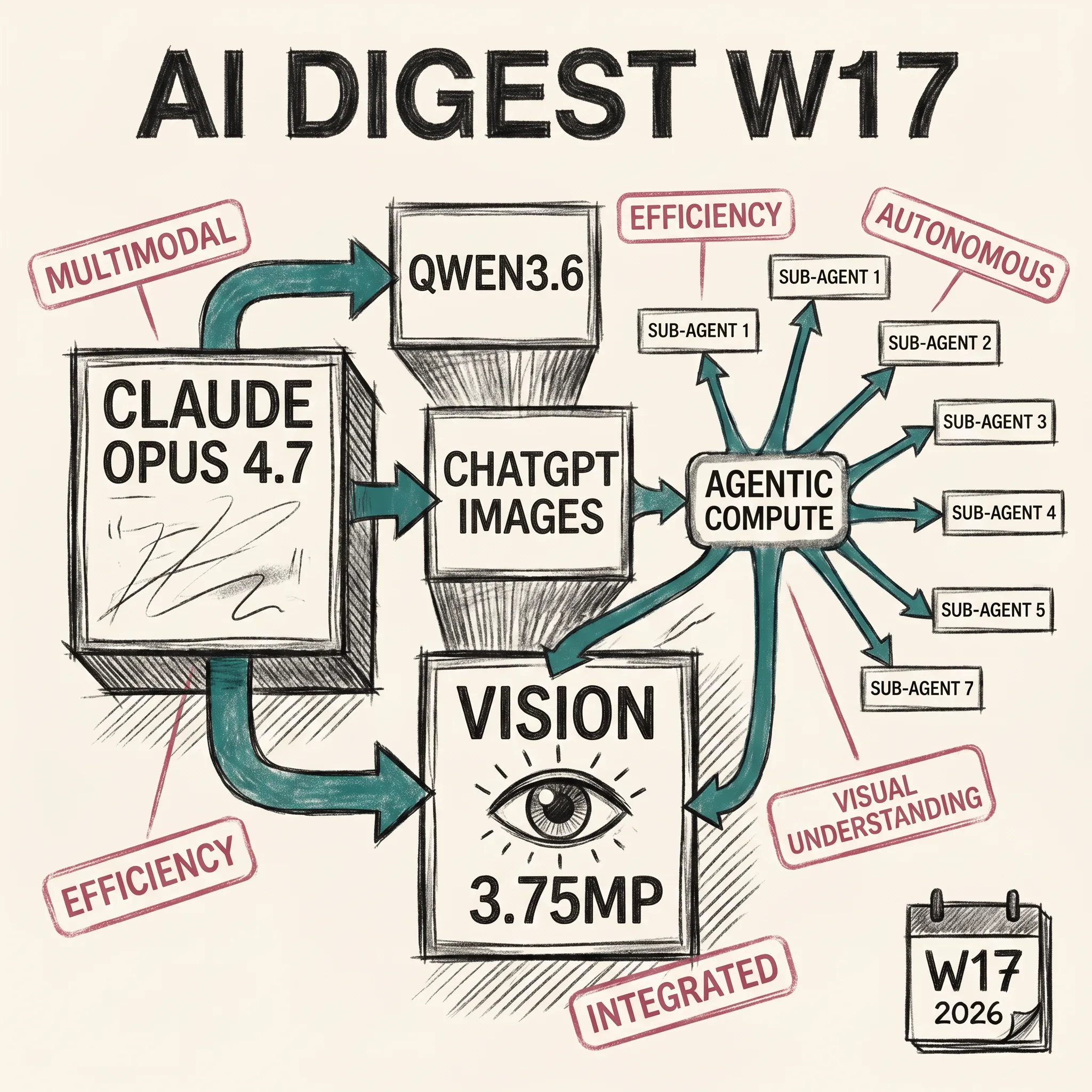 ai2 min read
ai2 min readAI Digest W17: Models, Images, and the Agentic Bill Arrives
Anthropic ships Opus 4.7 and Claude Design, OpenAI drops Images 2.0, Qwen3.6 opens up agentic coding, and GitHub sends the first real agentic compute invoice.
-
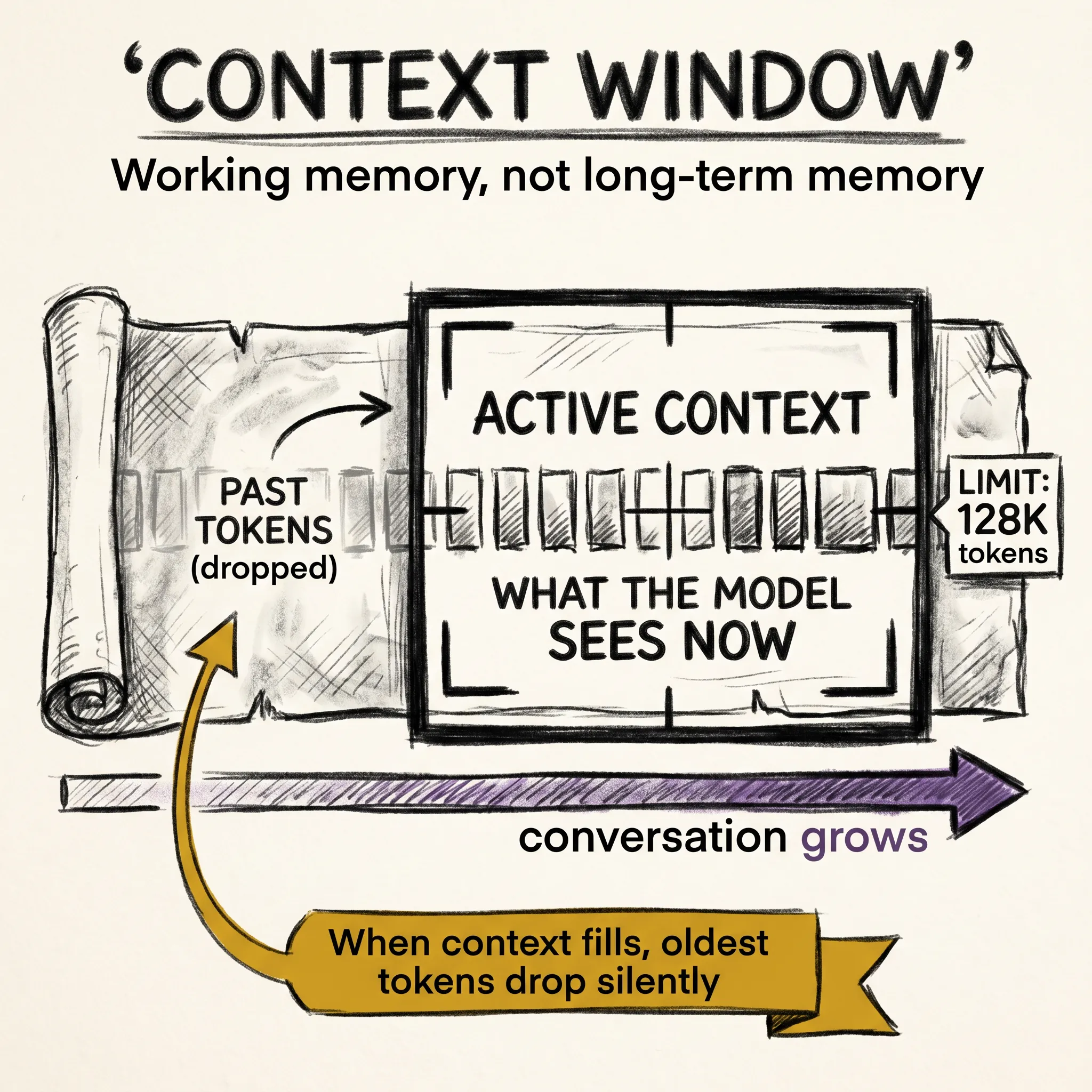 ai8 min read
ai8 min readContext Windows: Why Your AI Has a Working Memory Limit
Context windows are not memory. They are working memory. Here is what the model can see right now, why extending that limit is hard, and what it costs to try.
-
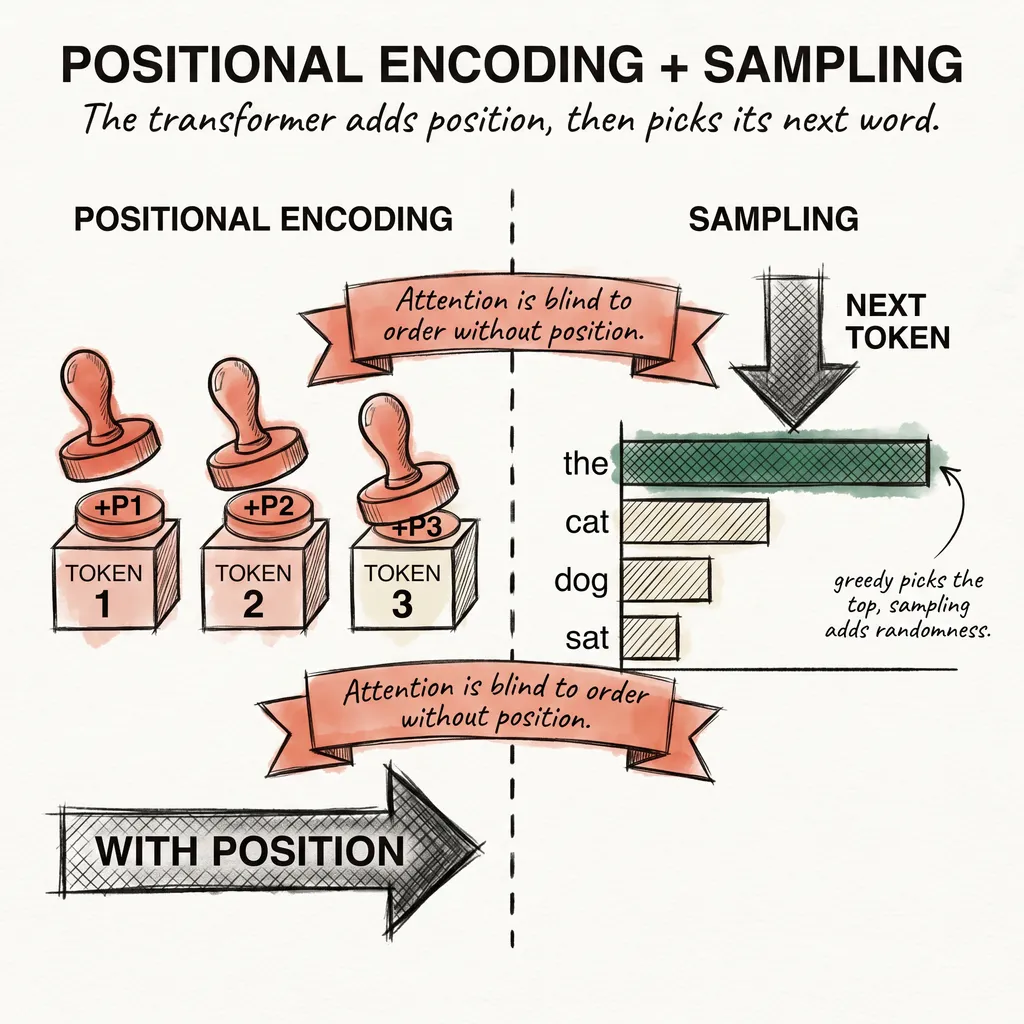 ai9 min read
ai9 min readPositional Encoding and Sampling: How the Transformer Finds Position and Picks Its Next Word
Attention cannot tell 'the dog bit the man' from 'the man bit the dog.' Positional encoding fixes that. Then sampling decides what word the model actually says.
-
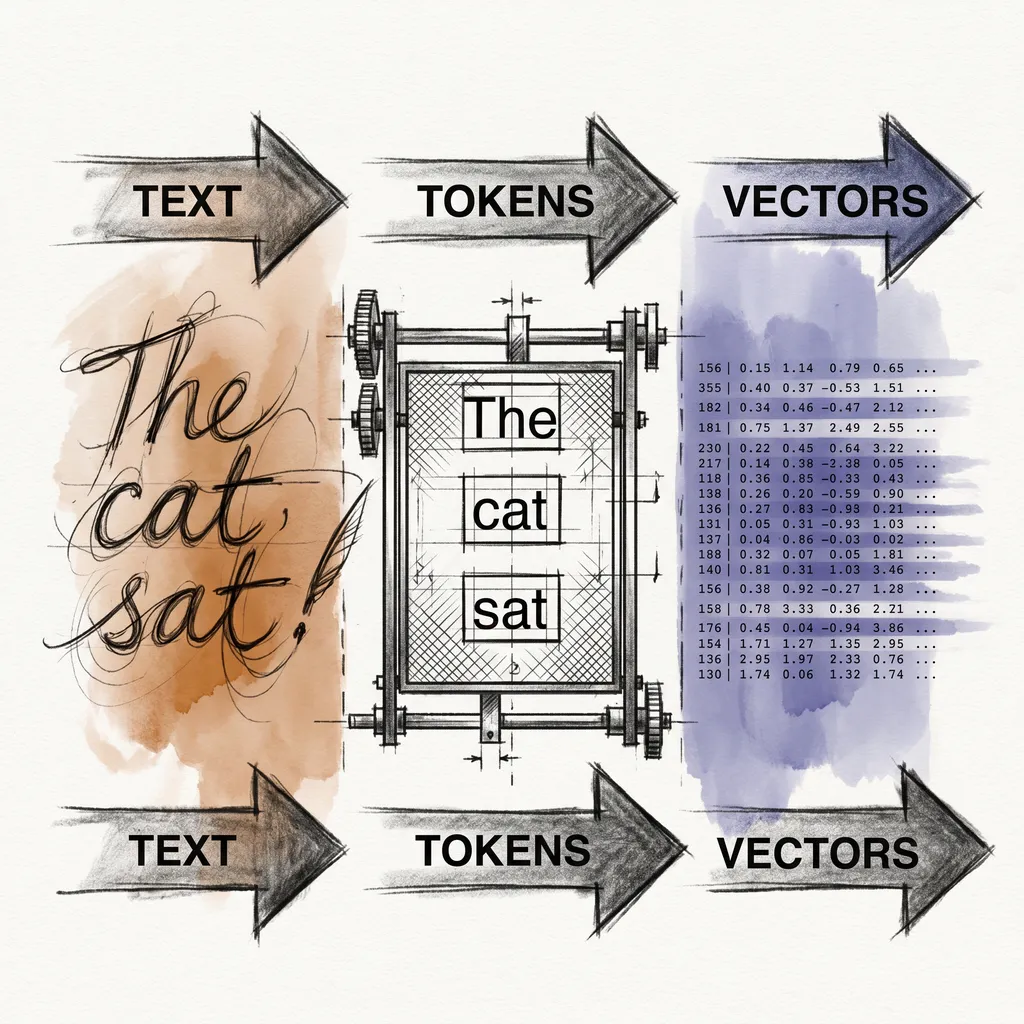 ai7 min read
ai7 min readTokens and Embeddings: How Raw Text Becomes Numbers the Model Can Use
Before the transformer can do anything, it must turn your prompt into numbers. Here is exactly how that works, from raw characters to dense vectors.
-
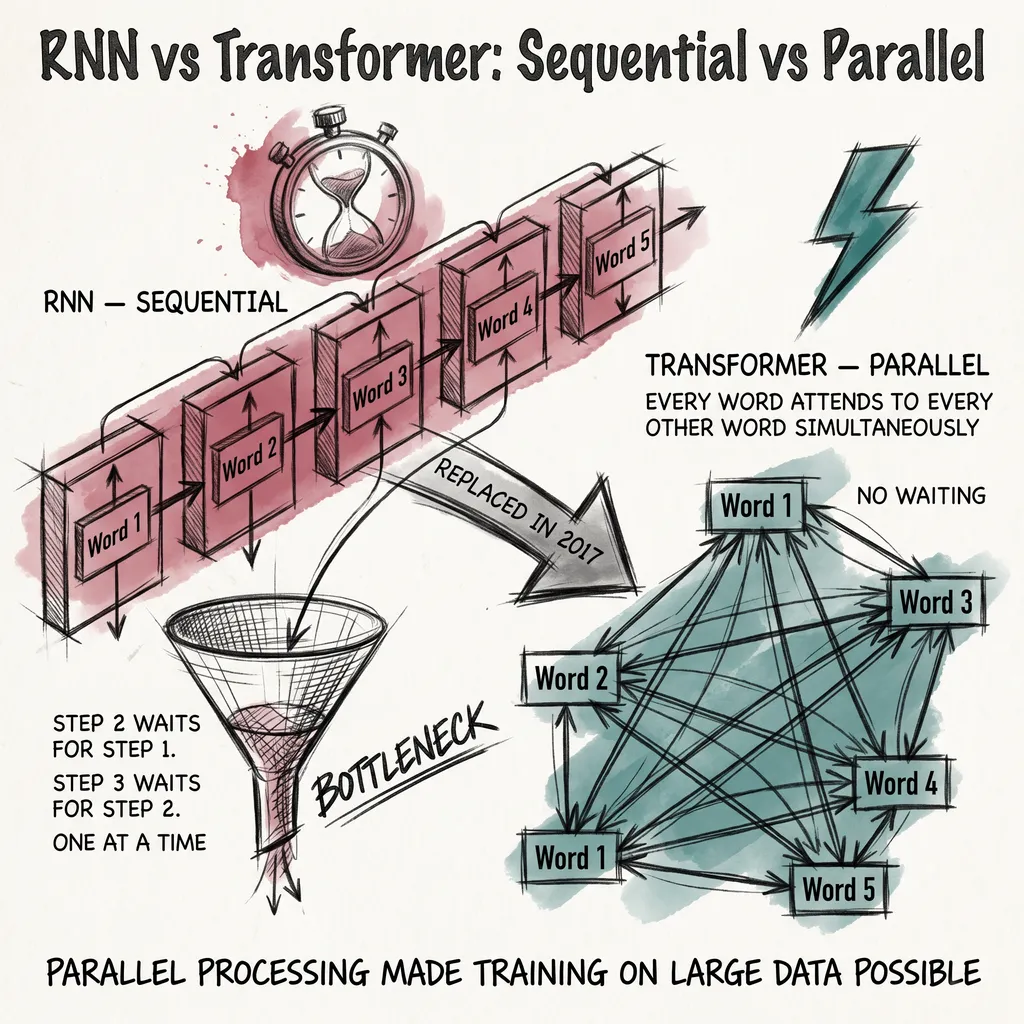 ai6 min read
ai6 min readThe Transformer: How Attention Solved the Problem Everything Else Could Not
In 2017, eight researchers replaced the entire approach to language modeling with a single idea: let every word attend to every other word directly.
-
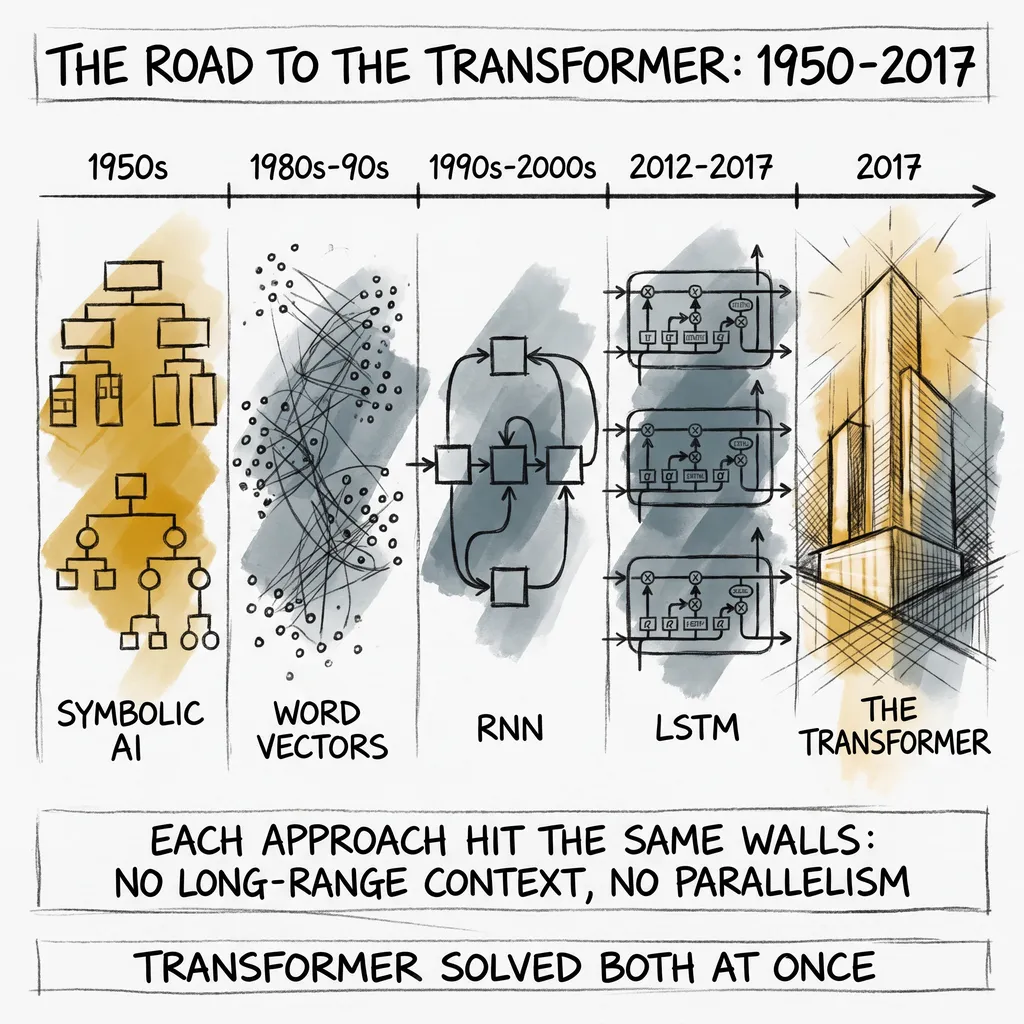 ai7 min read
ai7 min readBefore the Transformer: A Short History of Machines That Read
Why did the transformer matter so much that we measure AI in 'before' and 'after' it? A short history of every approach that tried and hit a wall first.
-
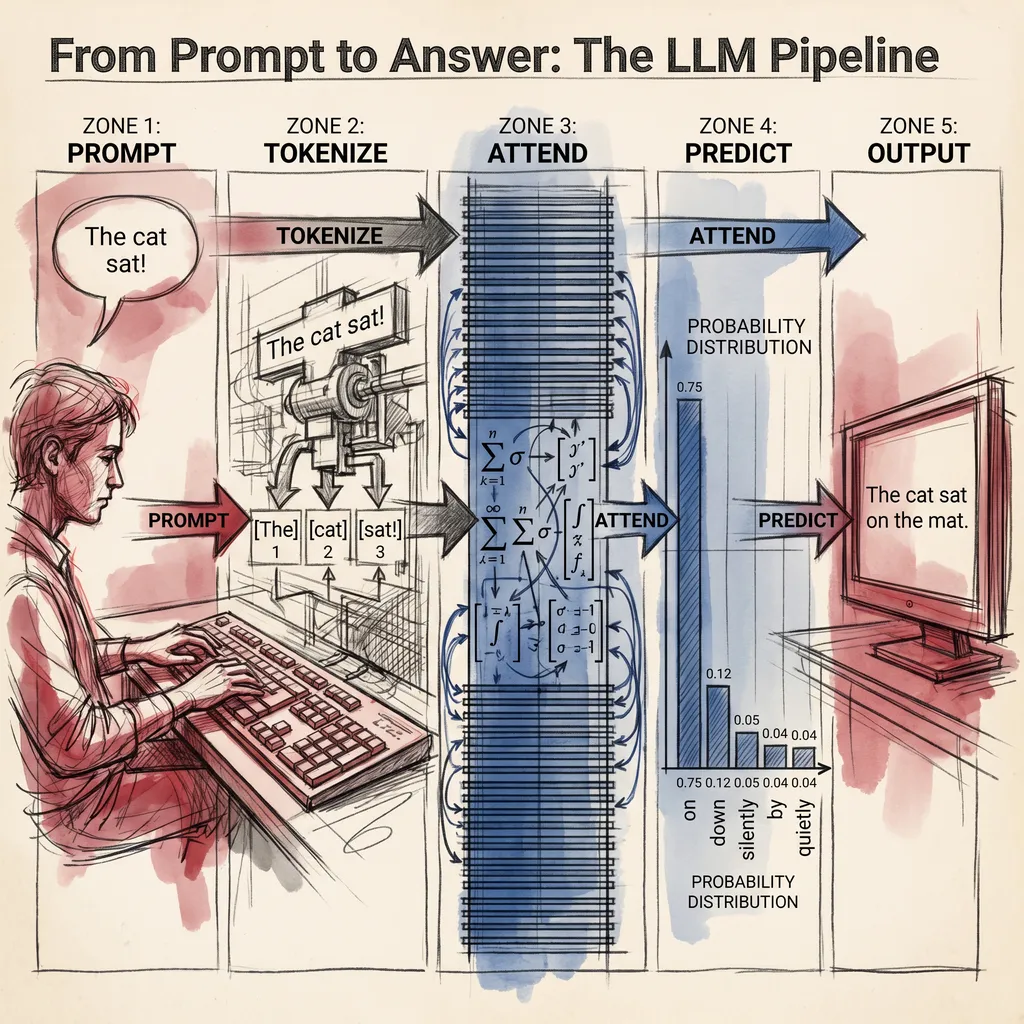 ai9 min read
ai9 min readWelcome to LLM Concepts: How the Machine Behind Your Chatbot Actually Works
A 27-article series on how 2026 LLMs actually work, written for curious readers who use ChatGPT, Claude, or Gemini and want to know what is happening inside.
-
 ai2 min read
ai2 min readAI Digest W16: The Cyber Model Race Starts for Real
OpenAI answers Mythos with GPT-5.4-Cyber, DeepMind ships a smarter robotics model, Willison calls the new security era proof-of-work, and OpenAI quietly goes vertical.
-
 ai2 min read
ai2 min readAI Digest W15: Models, Manifestos, and Meta's Big Pivot
Anthropic's Mythos finds zero-days, Meta goes proprietary with Muse Spark, Google ships Gemma 4, and Microsoft enters the foundation model race.
-
 brain8 min read
brain8 min readYour Brain on Screens: How Social Media and AI Hijack Attention
How infinite scroll, variable rewards, and AI recommendation engines exploit your dopamine pathways and weaken your prefrontal cortex.
-
 ai12 min read
ai12 min readWhat Comes Next: The Near Future of Technology
The final article in the From Electricity to AI series: where technology stands today, where it is heading, and what twenty articles taught me about it.
-
 ai10 min read
ai10 min readAI Agents: Software That Acts on Its Own
From chatbots to autonomous software: how AI agents perceive, reason, and act, plus the legal and philosophical questions they force us to answer.
-
 ai12 min read
ai12 min readThe Frontier Labs: Who Is Building AGI
The companies racing to build artificial general intelligence, their approaches, breakthroughs, and what sets each apart in 2025-2026.
-
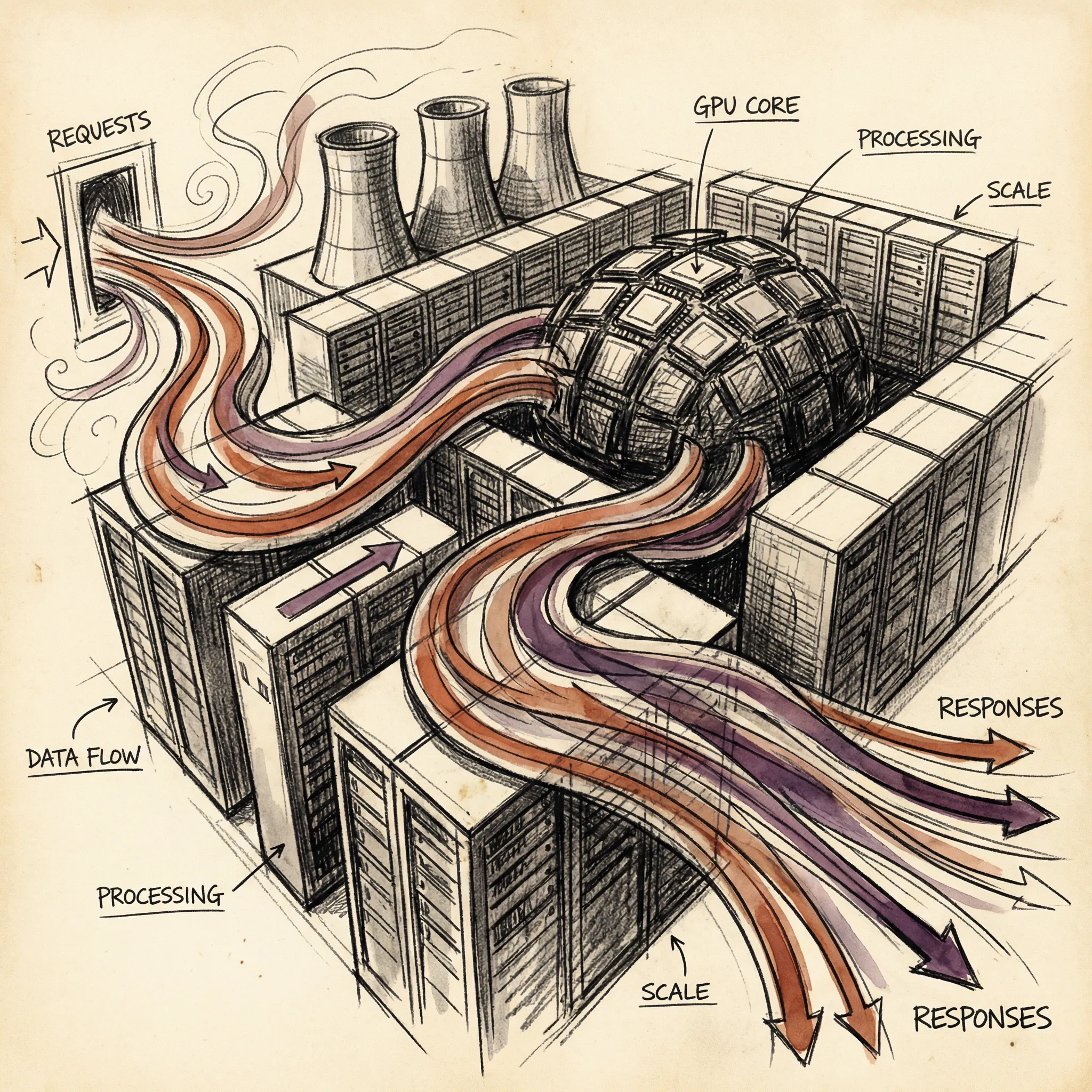 ai8 min read
ai8 min readAI Inference and Scaling: From Training to Serving Billions
How trained AI models serve billions of requests through inference optimization, scaling infrastructure, and cost engineering.
-
 ai9 min read
ai9 min readAI Training: How Models Get Smart
How AI training works, from gradient descent and backpropagation to RLHF, synthetic data, and the emerging possibility of recursive self-improvement.
-
 ai10 min read
ai10 min readLLMs - How ChatGPT Actually Works
How large language models actually work, from tokenization and embeddings to attention mechanisms and next-token prediction.
-
 neural-networksUpdated: 11 min read
neural-networksUpdated: 11 min readNeural Networks: How AI Mimics the Brain
How artificial neurons combine into networks that recognize images, understand language, and generate text. From perceptrons to transformers.
-
 machine-learning12 min read
machine-learning12 min readMachine Learning: How Computers Learn from Data
How computers find patterns without being told the rules. Supervised learning, gradient descent, and why data quality matters more than algorithms.
-
 energy7 min read
energy7 min readPower and the Internet: The Energy Cost of Everything Digital
Data centers now consume 460 TWh annually and could exceed 1,000 TWh by 2026. Explore the energy sources powering the internet and what it means for our planet.
-
 brain6 min read
brain6 min readThe Brain Roadmap: Understanding Your Own Operating System
Why understanding how your brain works is practical self-defense in the age of AI algorithms designed to manipulate your attention.
-
 processors11 min read
processors11 min readProcessors and GPUs: How Chips Think
How transistors become processors. The difference between CPUs and GPUs, and why parallel processing is the reason AI exists.
-
 semiconductors9 min read
semiconductors9 min readSemiconductors: The Material That Changed Everything
How a piece of silicon becomes a computer chip. From doping to transistors to AI processors with 208 billion switches.
-
 electricity9 min read
electricity9 min readAttentionElectricity is all you need...A beginner-friendly guide to voltage, current, resistance, and power, and why electricity is now the single biggest constraint on AI growth.
-
 roadmap4 min read
roadmap4 min readThe Tech Roadmap: From Electricity to AI
A 20-article guide covering the complete path from electricity to artificial intelligence, layer by layer, from hardware to reasoning.
-
 welcome2 min read
welcome2 min readWhy This Blog Exists
Notes on AI, cybersecurity, mental health, and staying independent. I write to learn how things work and understand what's coming.