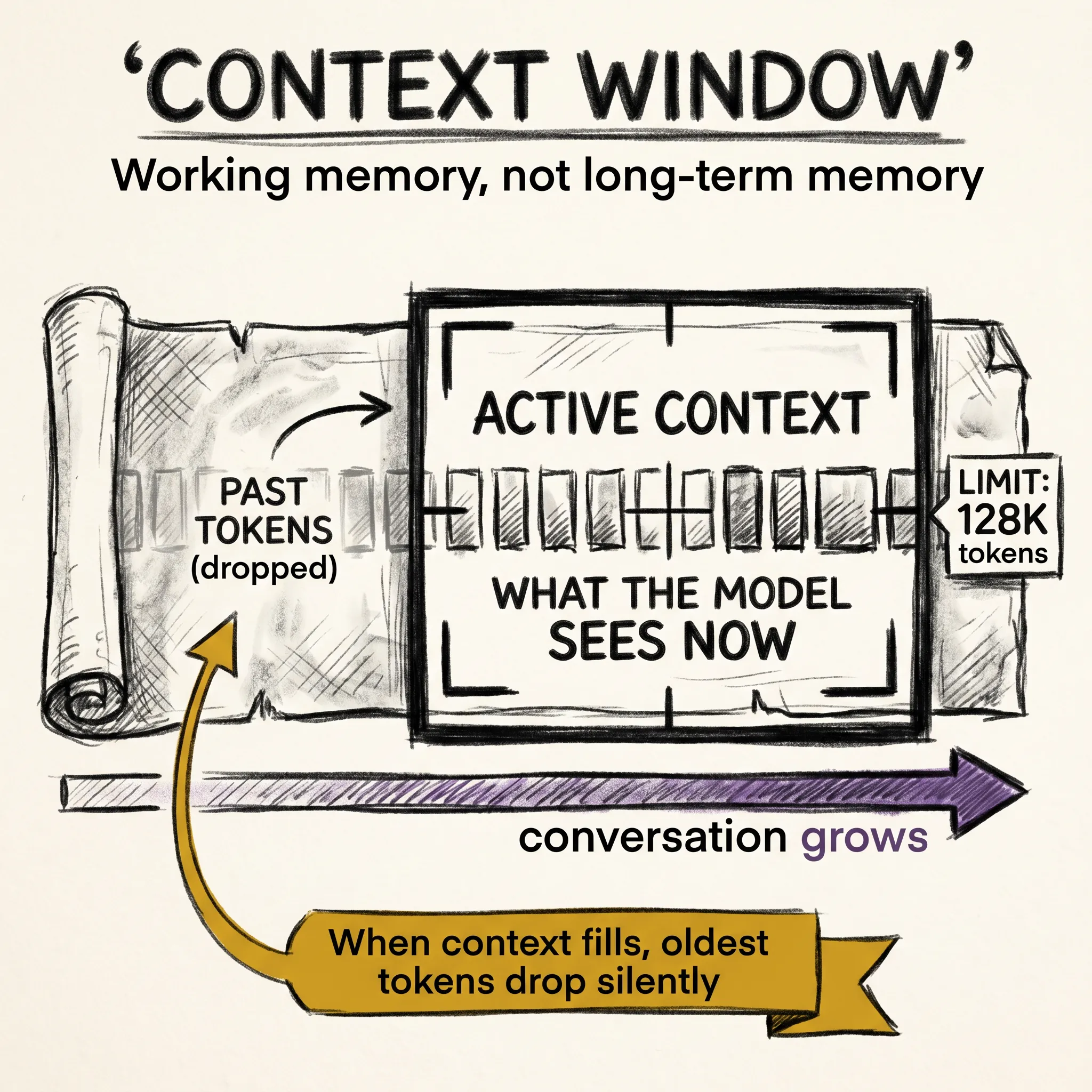
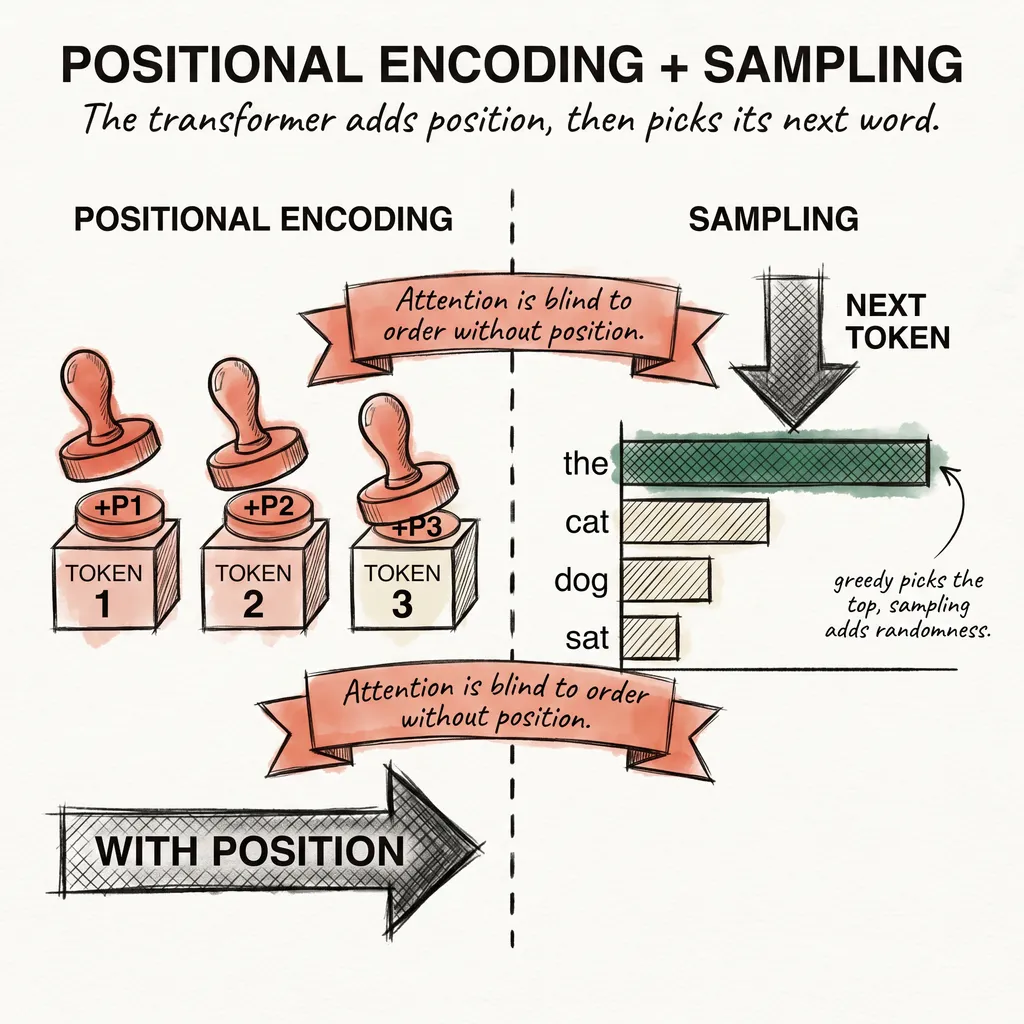
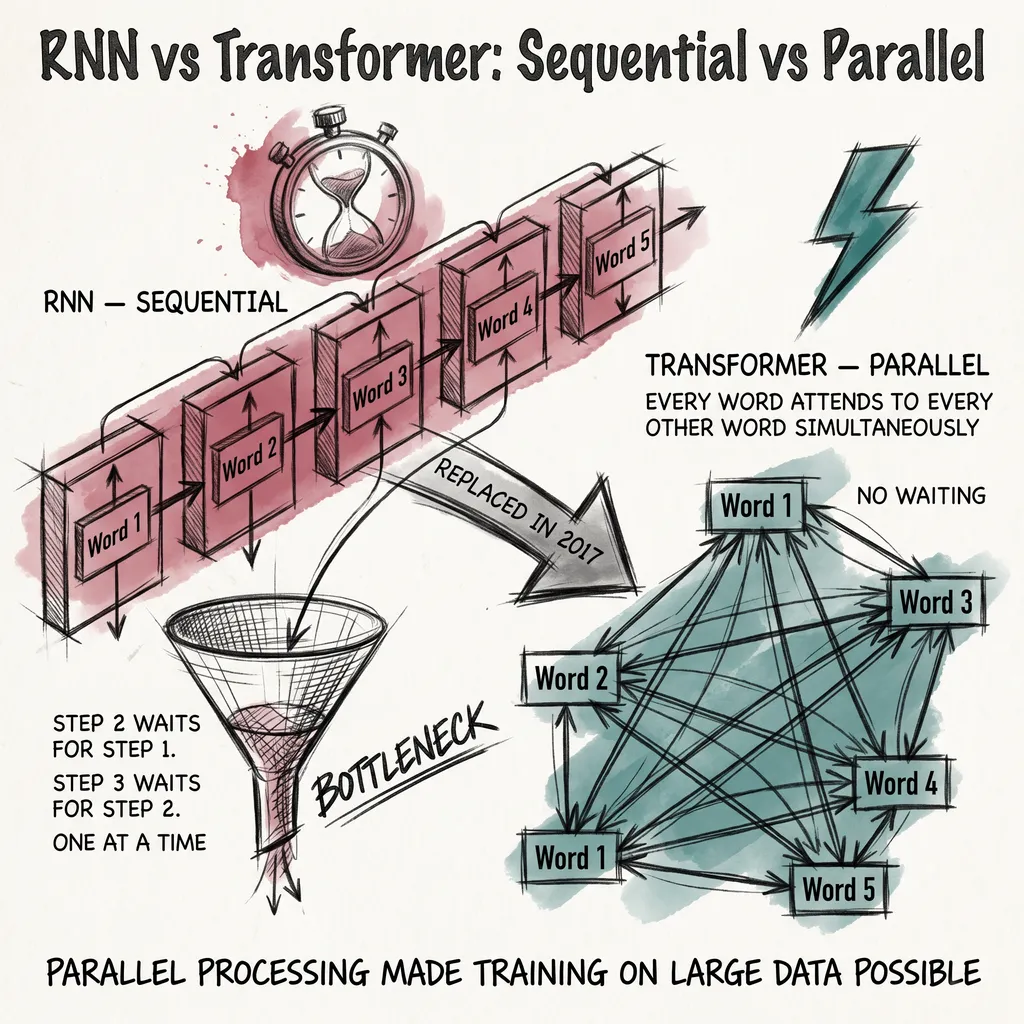
In 1950, Alan Turing published a paper asking whether machines could think. He proposed a test: if a machine could hold a conversation and you could not tell it was a machine, it passed.
It took 65 years to build something that could pass that test. And when we finally did it, the machine did not think the way Turing imagined.
It predicted the next word, very well, at enormous scale.
To understand why that works, you need to see the things that did not work first.
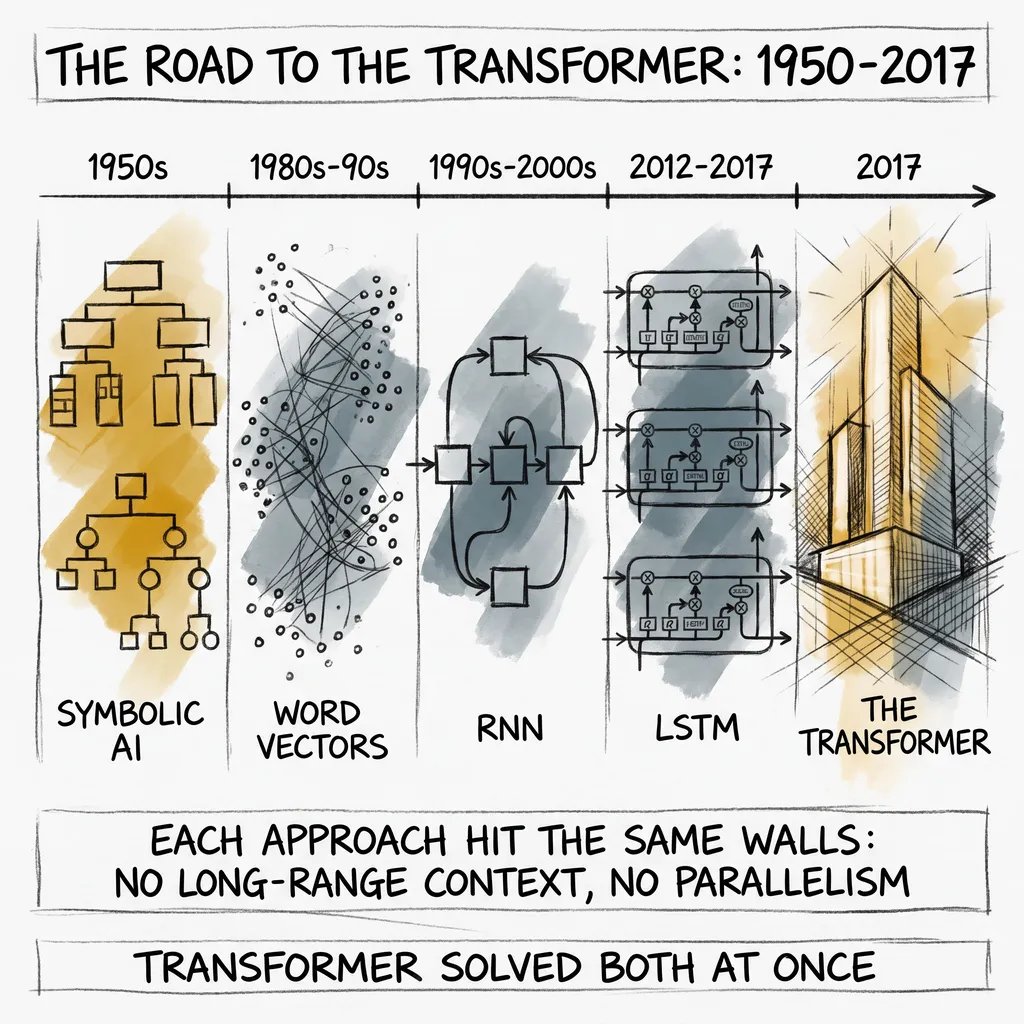
THE FIRST ATTEMPTS: RULES AND SYMBOLS
The field started with a reasonable assumption. Intelligence, researchers thought, was about rules. If you could write down enough rules about language, a machine could follow them and produce something intelligent.
Researchers called this approach symbolic AI. You define symbols, give them meanings, and write rules for how they combine.
It worked well for narrow problems. Chess is a rule-based system, and computers played it well for decades. But language is not chess.
Natural language has ambiguity at every level. The sentence I saw a man with a telescope means two different things depending on context. The word bank means a financial institution or a riverbank depending on what came before it.
Writing rules to handle every case was like trying to map every possible conversation. For every rule you added, a new edge case appeared that broke it.
By the 1970s, progress stalled. It stalled again in the late 1980s. Funding dried up. The field entered what researchers called AI winters, periods where the gap between ambition and results became impossible to ignore.
Not failure exactly. More like an honest recognition that the approach had hit its ceiling.
THE EMBEDDING BREAKTHROUGH: WORD2VEC
The real change came from a different idea. Instead of programming rules, what if you fed a machine enough text and let it figure out the patterns?
In 2013, a team at Google Brain led by Tomas Mikolov published word2vec. The idea was straightforward. Words that appear in similar contexts probably mean similar things. Train a shallow neural network to predict a word from its neighbors, and the internal representations it builds will reflect that.
The result surprised people. Take the vector for king, subtract man, add woman, and you get a vector close to queen.
Nobody programmed that analogy in. The model discovered it from patterns in text.
Words stopped being arbitrary symbols and became points in a high-dimensional space where distance meant something. Related concepts clustered together. Opposites sat far apart. You could do arithmetic on meaning.
Word2vec was not a language model. It could not generate text or answer questions.
But it proved something important: meaning could be encoded mathematically, and that encoding could be learned from data rather than written by hand. That idea is still at the core of every LLM running today. The details changed enormously. The principle held.
RNNS AND THE SEQUENCE PROBLEM
Word2vec solved the representation problem for individual words. The next problem was sequences. Language is not a bag of unrelated words. Order matters.
Dog bites man and man bites dog use the same three words and describe completely different situations.
Recurrent neural networks, or RNNs, were the tool researchers reached for. An RNN processes text one word at a time, maintaining a hidden state that summarizes everything it has seen so far. Each new word updates that state. By the end of a sentence, the hidden state holds a compressed memory of the whole thing.
Think of it like reading with a piece of paper covering all but one word, moving right as you go. You have to carry everything in your head. The hidden state is that mental note.
RNNs worked for short sequences. For long ones, they struggled badly.
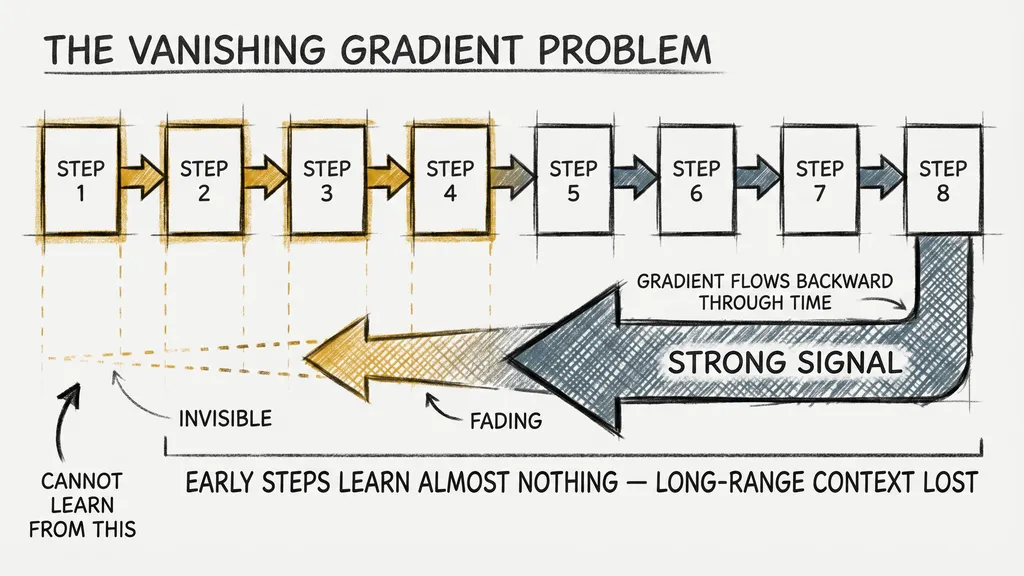
The mathematical signal used to train the network had to travel backward through every word to adjust the early parts. Over a long sequence, that signal either exploded or vanished to near zero.
Researchers named it the vanishing gradient problem, and it was a genuine wall, not a tuning issue. You could not design your way around it with a better RNN. The architecture itself was the constraint.
LSTMS: A BETTER MEMORY
In 1997, Sepp Hochreiter and Jürgen Schmidhuber published a paper introducing Long Short-Term Memory networks, or LSTMs. The core innovation was a dedicated memory cell with explicit gates: one controlling what new information to let in, one controlling what old information to forget, and one controlling what to output.
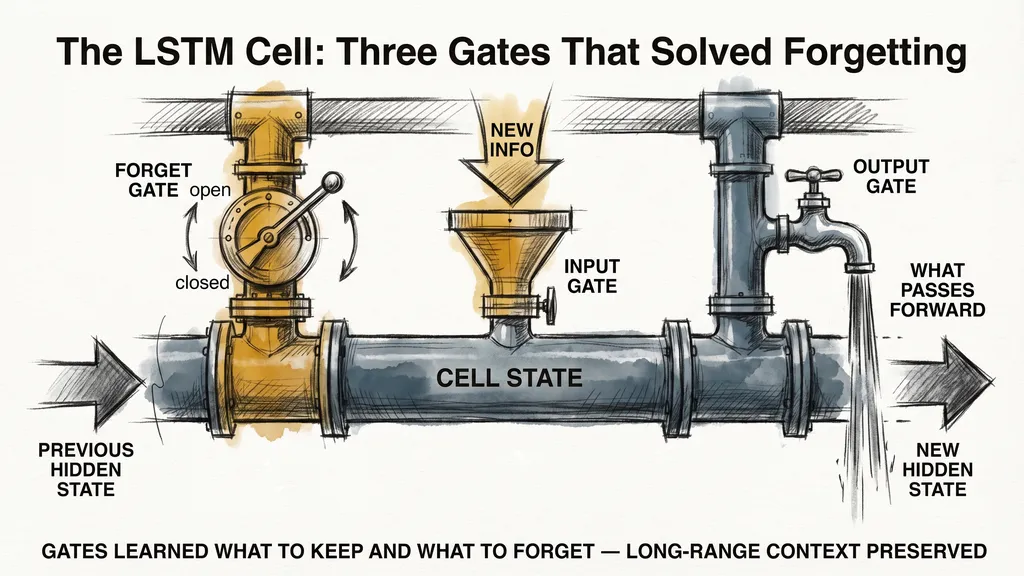
LSTMs gave the network a way to hold onto important information over many steps without letting it degrade. They were significantly better than plain RNNs on longer sequences, and they became the dominant architecture in NLP for most of the 2010s.
In 2014, Ilya Sutskever and his collaborators at Google showed that two LSTMs chained together could translate between languages well enough to be useful. One network encoded the source sentence into a fixed-length vector. A second decoded that vector into the target language word by word. They called it a sequence-to-sequence model.
For a few years, seq2seq with LSTMs was state of the art. Products got built on it. It was good. It was not good enough.
THE WALLS THEY HIT
LSTMs were better than everything before them. They still carried two problems that tuning alone could not fix.
The first was the sequential bottleneck. To process a sentence of 100 words, an RNN processes word 1, then word 2, then word 3, one at a time, in order. You cannot run steps in parallel. Training on large datasets was slow in a way that faster hardware did not fully solve, because the computation itself was serial.
The second was long-range dependencies. Even LSTMs lost track over long passages. A pronoun near the end of a paragraph might refer to a noun from the beginning. Getting that information to survive dozens of intermediate steps, without being overwritten by everything in between, was unreliable.
A line in the 2017 transformer paper captures the situation honestly. The authors wrote that the dominant sequence transduction models relied on complex recurrent or convolutional neural networks.
The word dominant is doing heavy work there. These were the best approaches anyone had. The paper then proposes to replace them entirely.
WHY THIS HISTORY MATTERS
Every approach described here, from symbolic rules to word2vec to RNNs to LSTMs, was trying to answer the same question. How does a machine hold context? How does it connect a word near the end of a sentence to what came before it? How does it track meaning across a paragraph?
Each approach got closer. Each hit a wall.
Symbolic AI could not handle ambiguity. Word2vec could represent meaning but not sequences. RNNs could handle sequences but forgot over distance. LSTMs remembered better but still processed one word at a time.
The transformer answered the question differently. Instead of processing words in order and maintaining a running memory, it looked at all words at once and computed direct relationships between every pair. No sequential bottleneck. No information decaying over distance.
That is why we measure AI history in before and after the transformer. Not because it was clever. Because it solved the one problem that every previous approach could not.
The transformer itself, and what it actually proposes, is the next article.
T.
References
- Computing Machinery and Intelligence (Turing, 1950) - The paper that introduced the Turing test and framed the question this history circles back to.
- Efficient Estimation of Word Representations in Vector Space (Mikolov et al., 2013) - The word2vec paper that introduced learned word embeddings at scale.
- Long Short-Term Memory (Hochreiter & Schmidhuber, 1997) - The LSTM paper that made recurrent networks practical for longer sequences.
- Sequence to Sequence Learning with Neural Networks (Sutskever et al., 2014) - The seq2seq paper showing two LSTMs could translate between languages.
- Attention Is All You Need (Vaswani et al., 2017) - The transformer paper that replaced everything described in this article.
- Machine Learning: How Computers Learn - The From Electricity to AI foundation article on how neural networks learn from data.