Tag: llm-concepts
All the articles with the tag "llm-concepts".
-
 llm-concepts8 min read
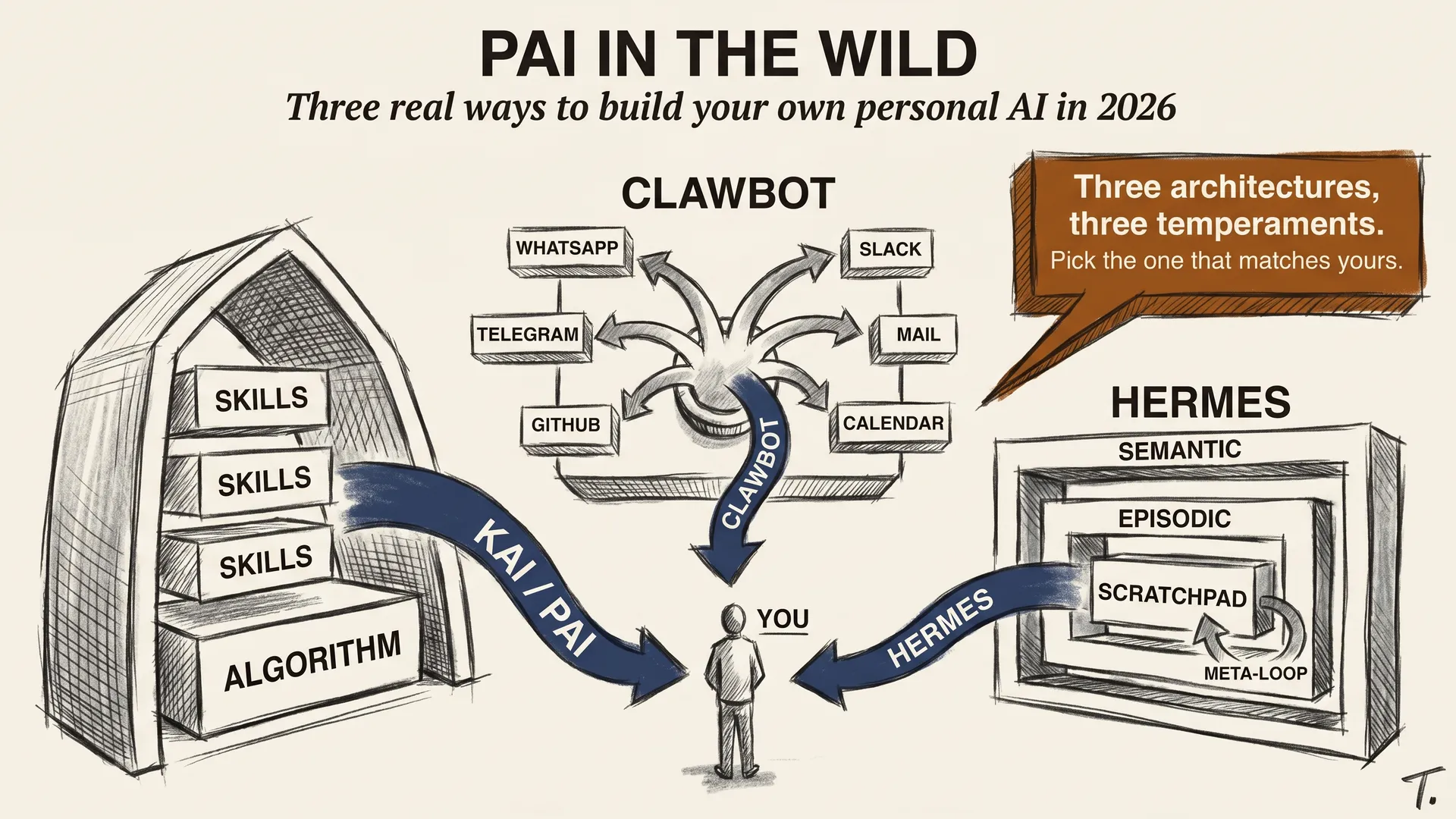
llm-concepts8 min readPAI in the Wild: Three Ways to Build Your Own
Three real 2026 options for building a personal AI: Kai (the framework I use), Clawbot (integrations-first), and Hermes (self-improving).
-
 llm-concepts8 min read
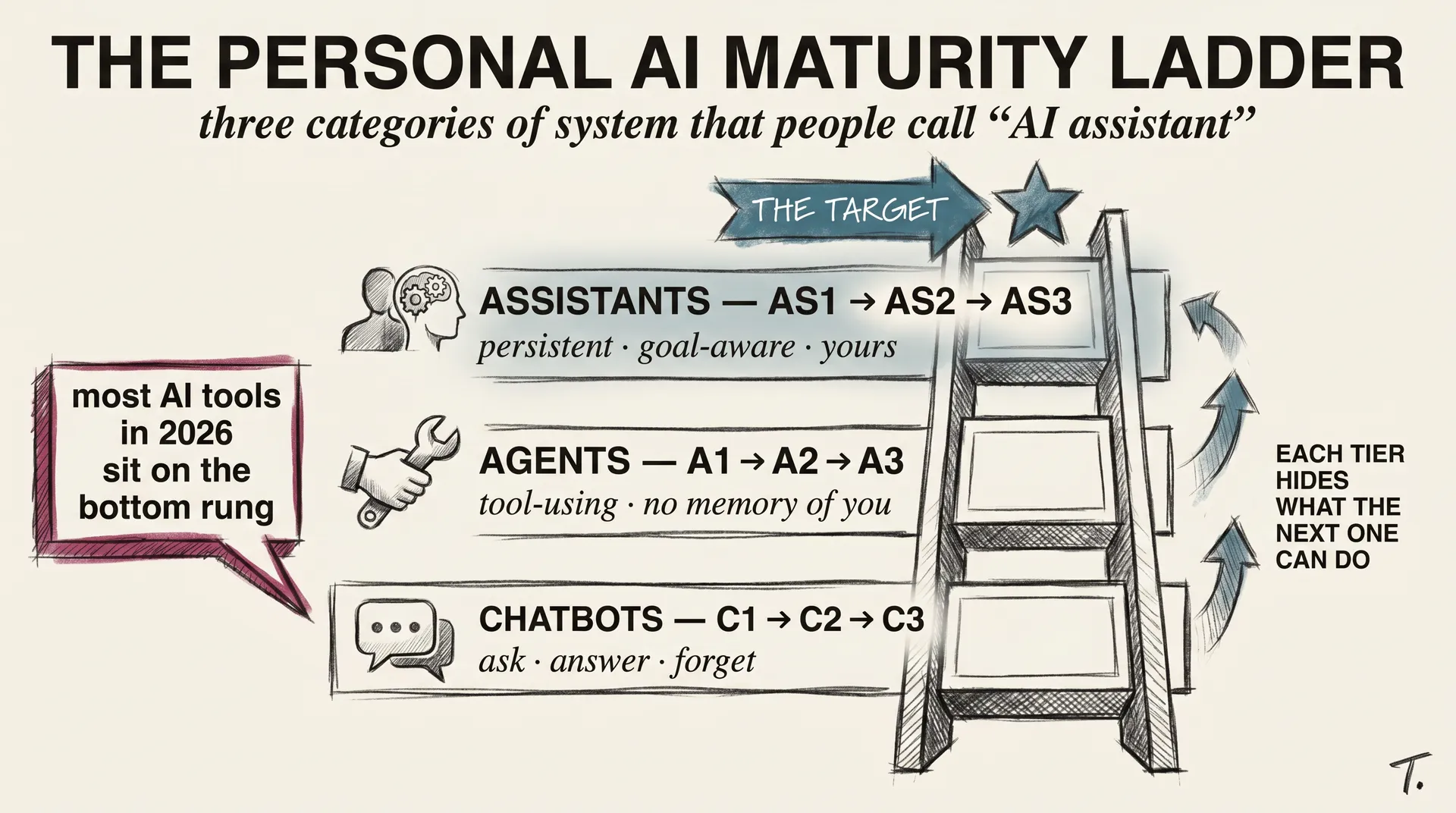
llm-concepts8 min readPersonal AI Infrastructure: The Climb From Chatbot to Assistant
Most AI tools today are chatbots in a costume. The real ladder has three tiers, and 2026 finally made the top one buildable at home.
-
 llm-concepts8 min read
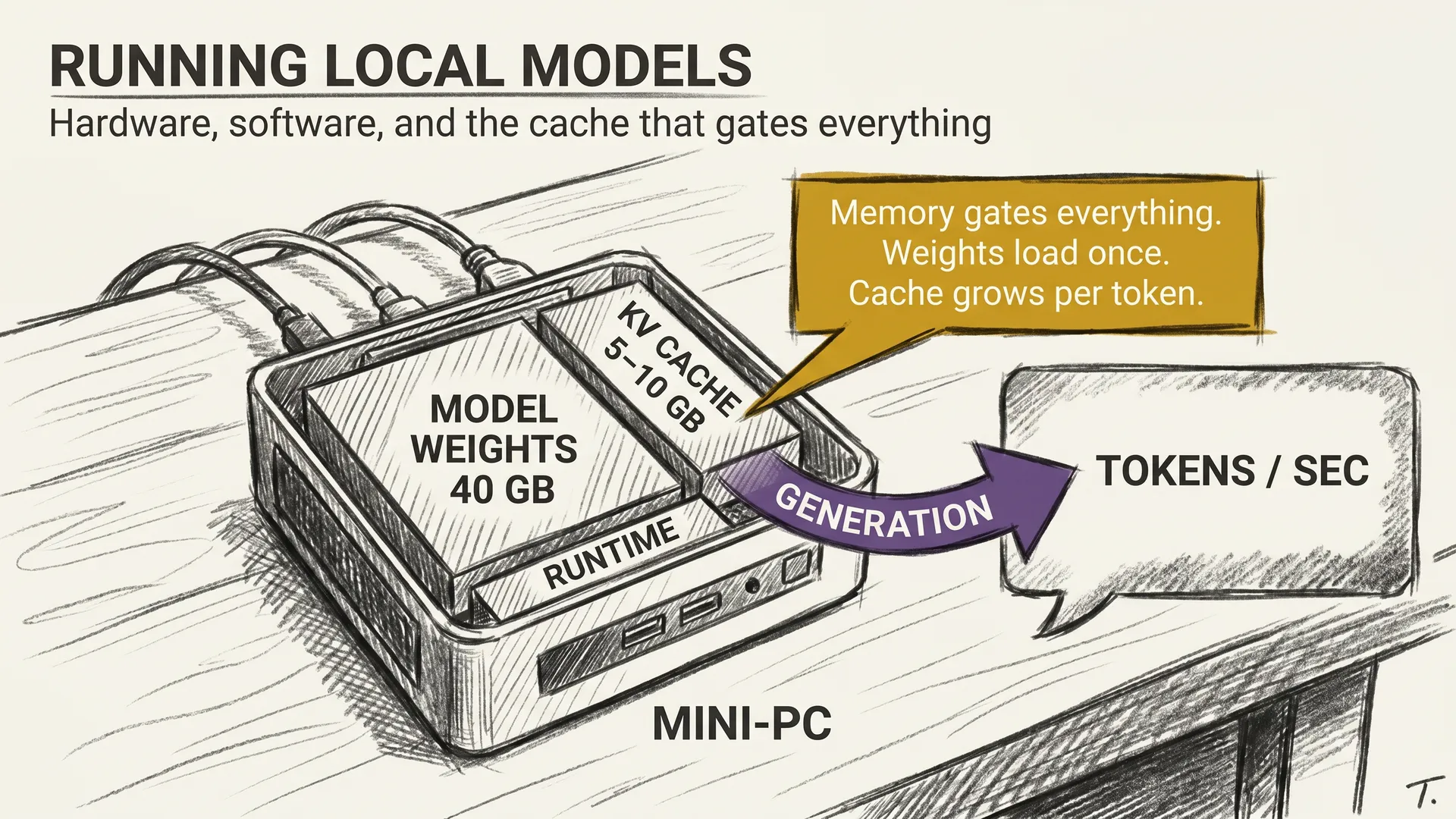
llm-concepts8 min readRunning Local Models: What It Actually Takes
Quantization shrank the model down to 40 GB. Now what hardware, what software, and what setup actually run a 70B model at home in 2026?
-
 llm-concepts7 min read
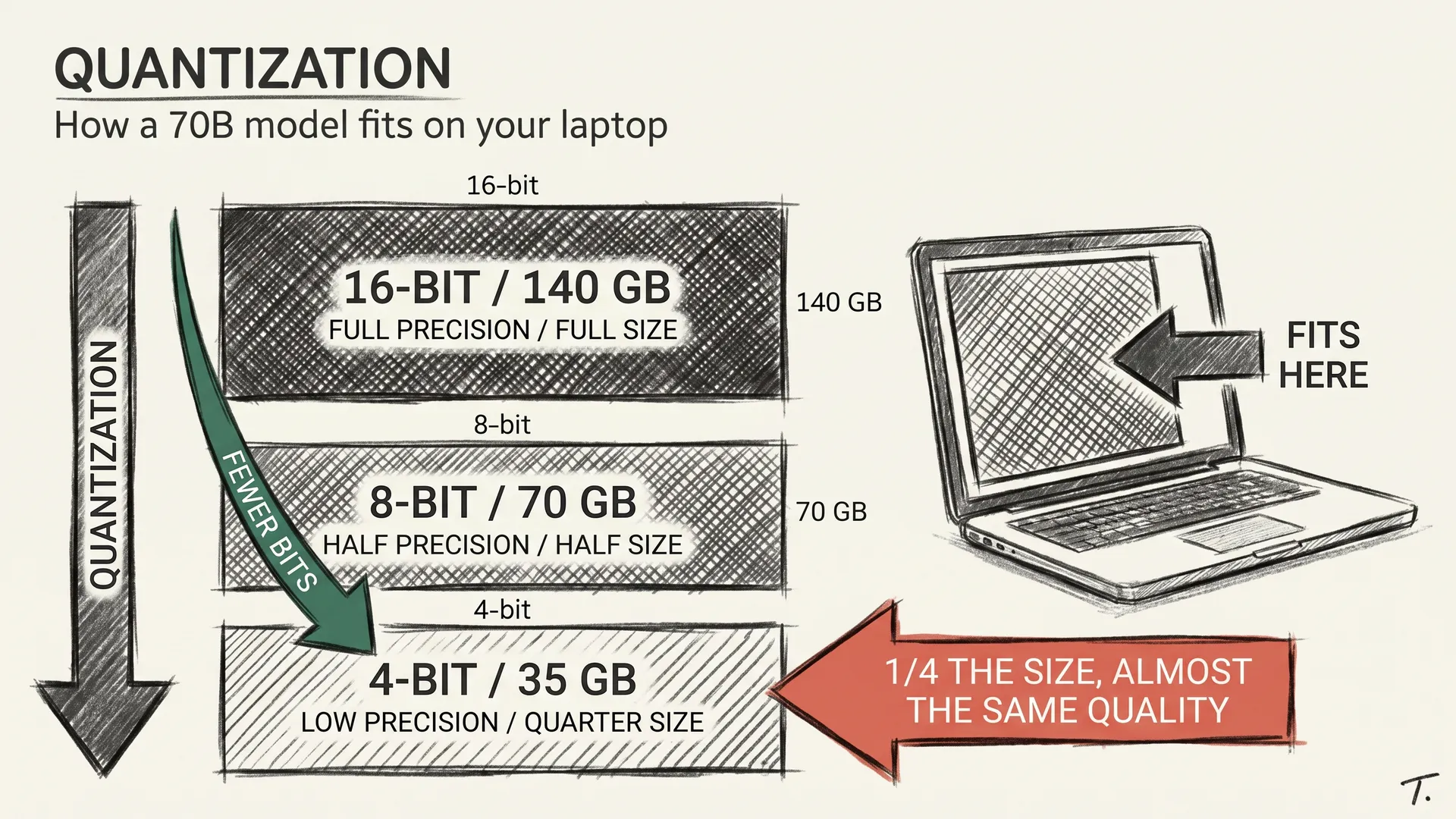
llm-concepts7 min readQuantization: How a 70B Model Fits on Your Laptop
Quantization shrinks a 70B model from 140 GB to 20 GB with almost no quality loss. What it actually does, and why the trick works.
-
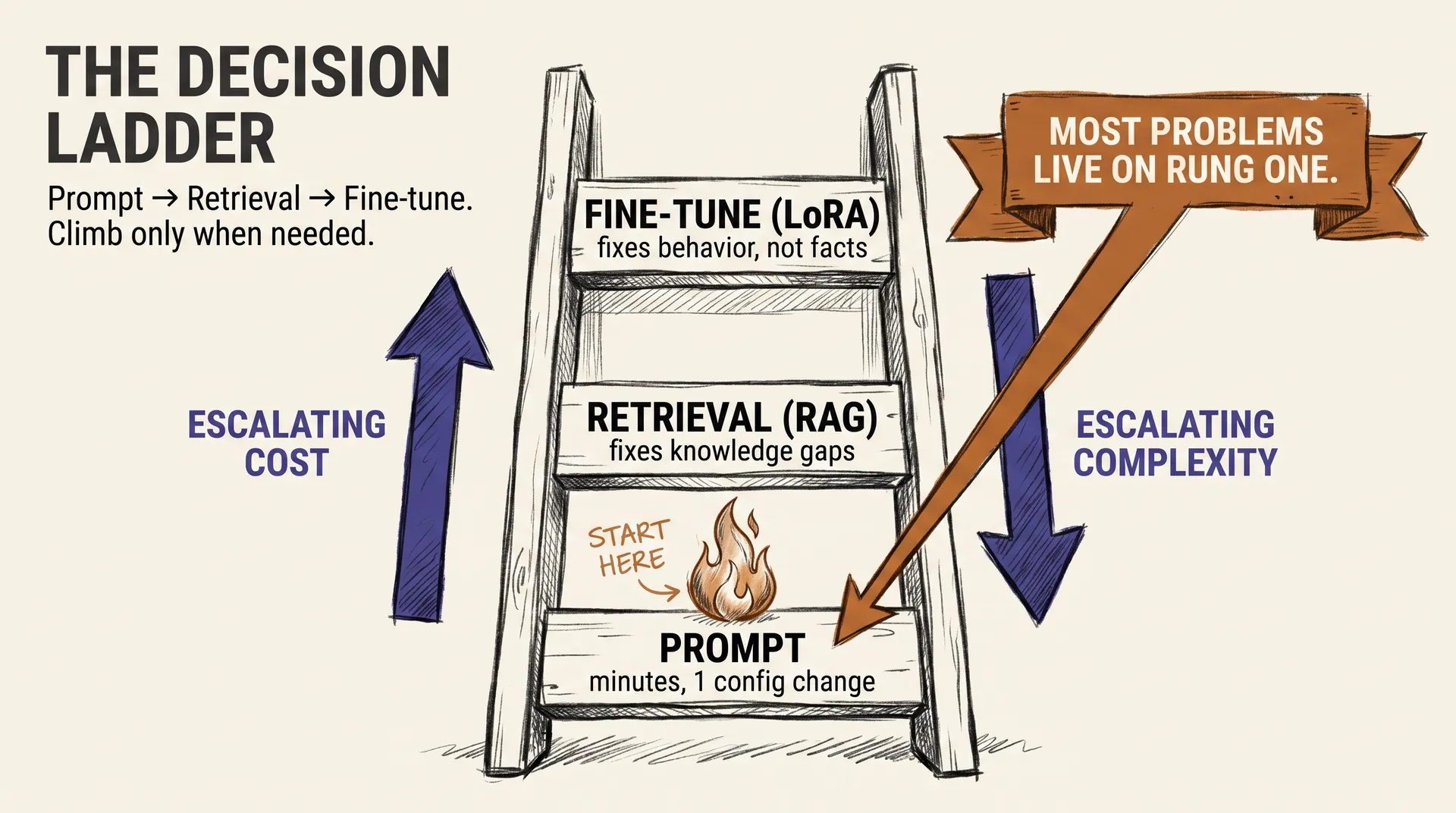 llm-concepts8 min read
llm-concepts8 min readFine-tuning with LoRA: When to Change the Model, Not the Prompt
When does fine-tuning beat prompting, and what does LoRA actually cost? The decision ladder that saves most teams from training a model they did not need.
-
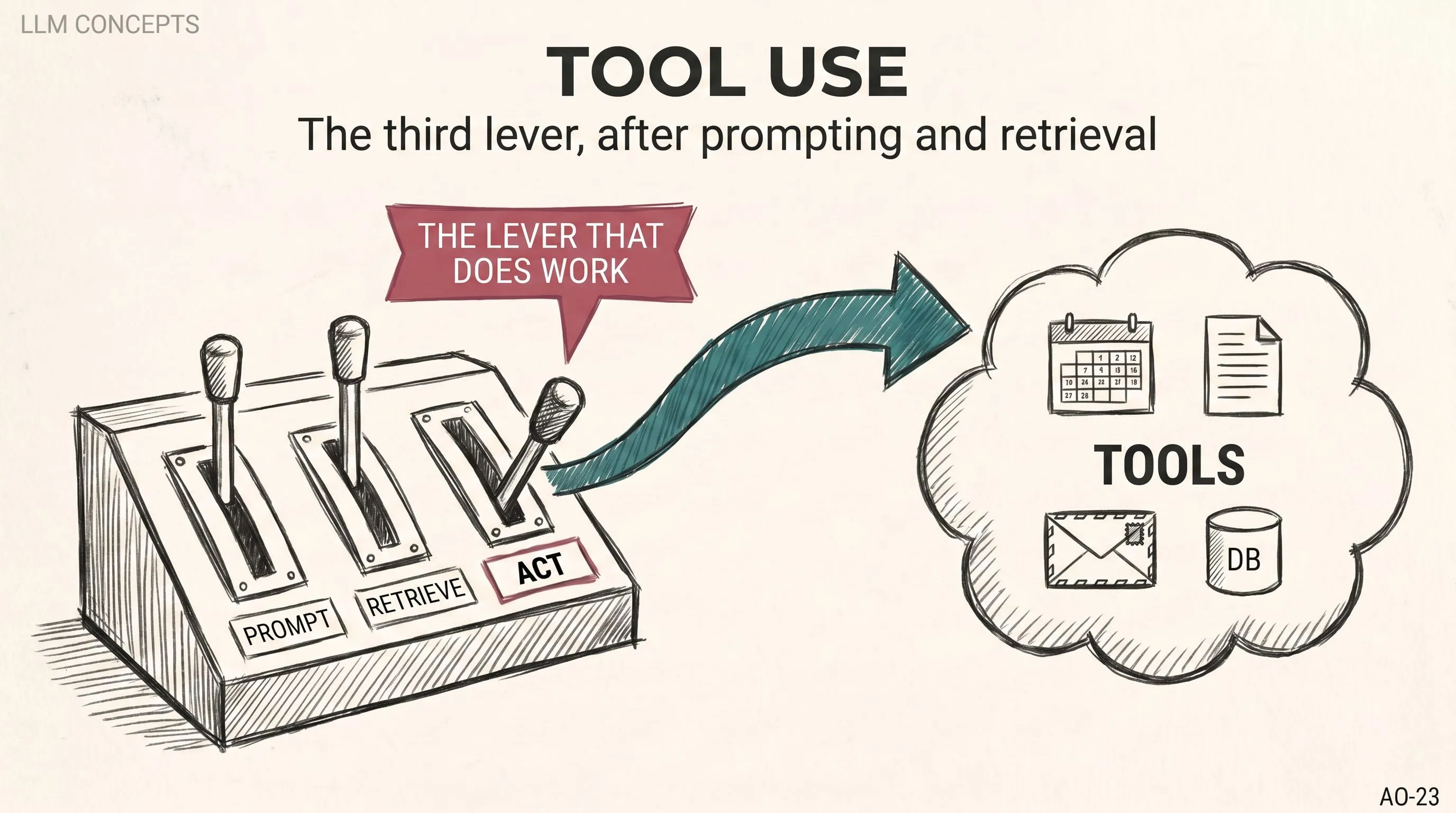 llm-concepts7 min read
llm-concepts7 min readTool Use, Function Calling, and MCP: How a Chatbot Became an Agent
Tools turn a chatbot into an agent. What function calling actually is, why MCP changed the rules, and the loop that makes a model do work.
-
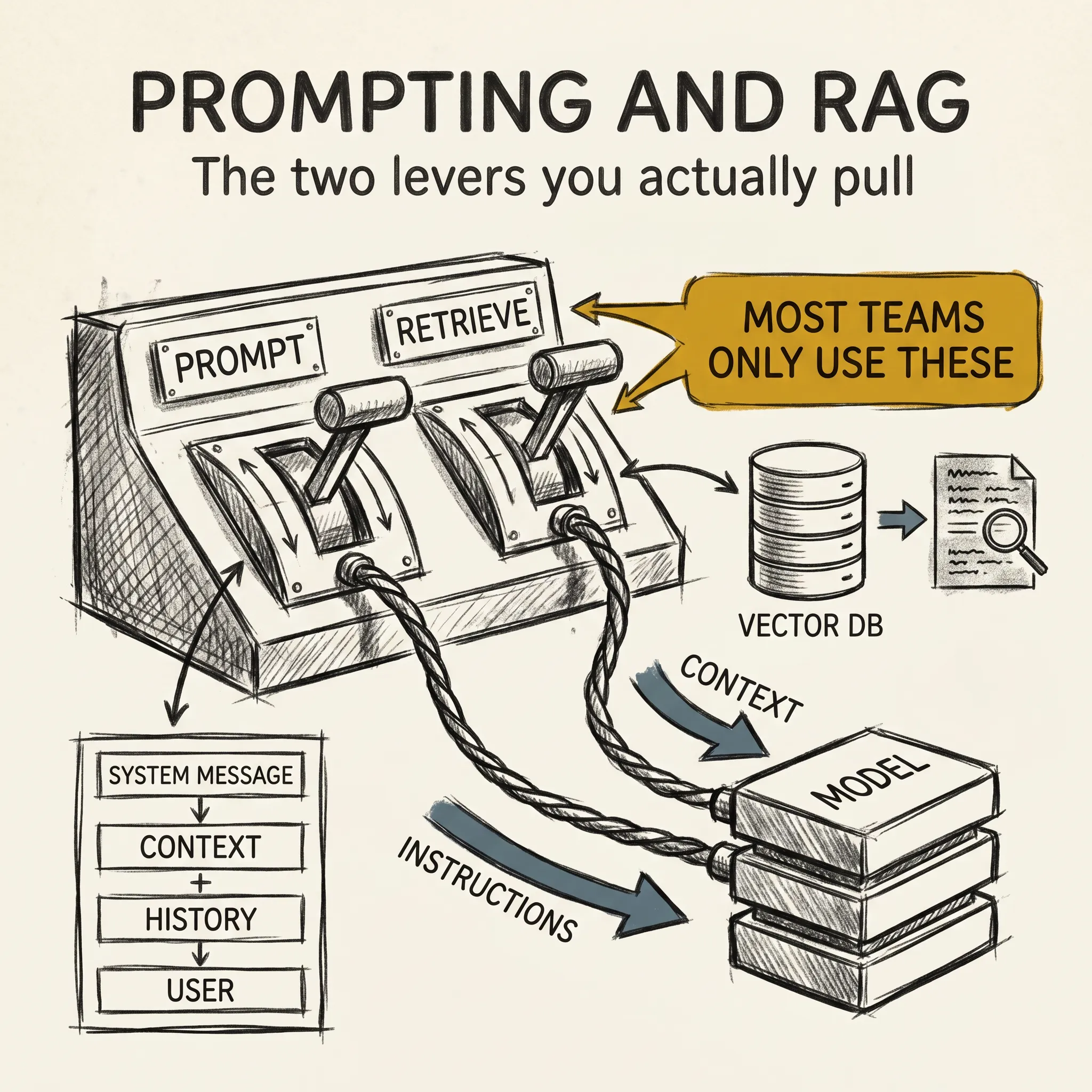 llm-concepts8 min read
llm-concepts8 min readPrompting and RAG: The Two Levers You Actually Pull
Most teams will never train a model. Most teams will spend a lot of time on prompts and retrieval. What the practical 2026 stack actually looks like.
-
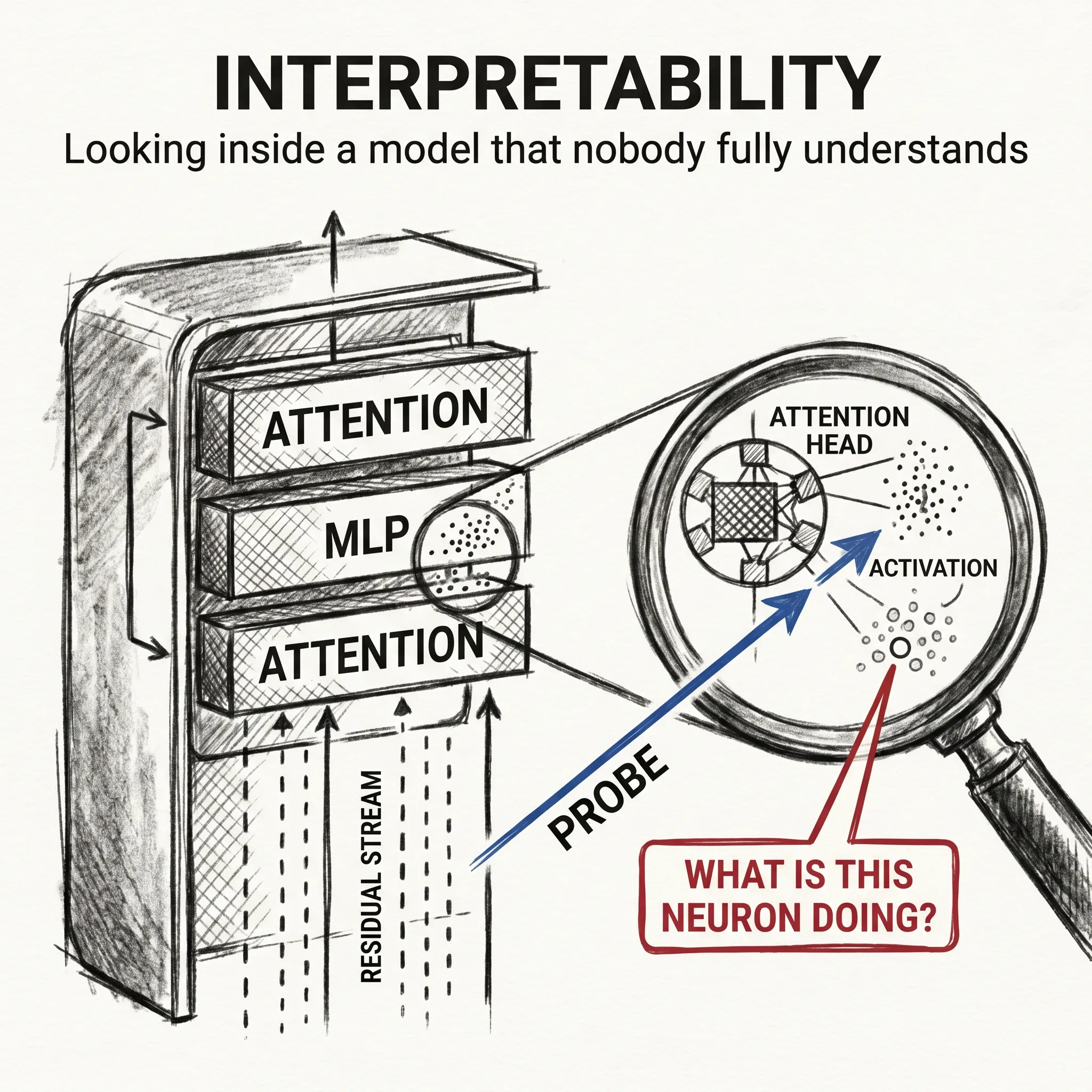 llm-concepts7 min read
llm-concepts7 min readInterpretability: What's Actually Inside
We can train a 70B model and watch it work. We mostly cannot explain why it works. Interpretability is the science trying to fix that.
-
 llm-concepts7 min read
llm-concepts7 min readBenchmarks: How Labs Measure Intelligence (and the Games They Play)
Every model launch comes with a chart. The numbers look big. What benchmarks actually measure, what they miss, and how labs game them.