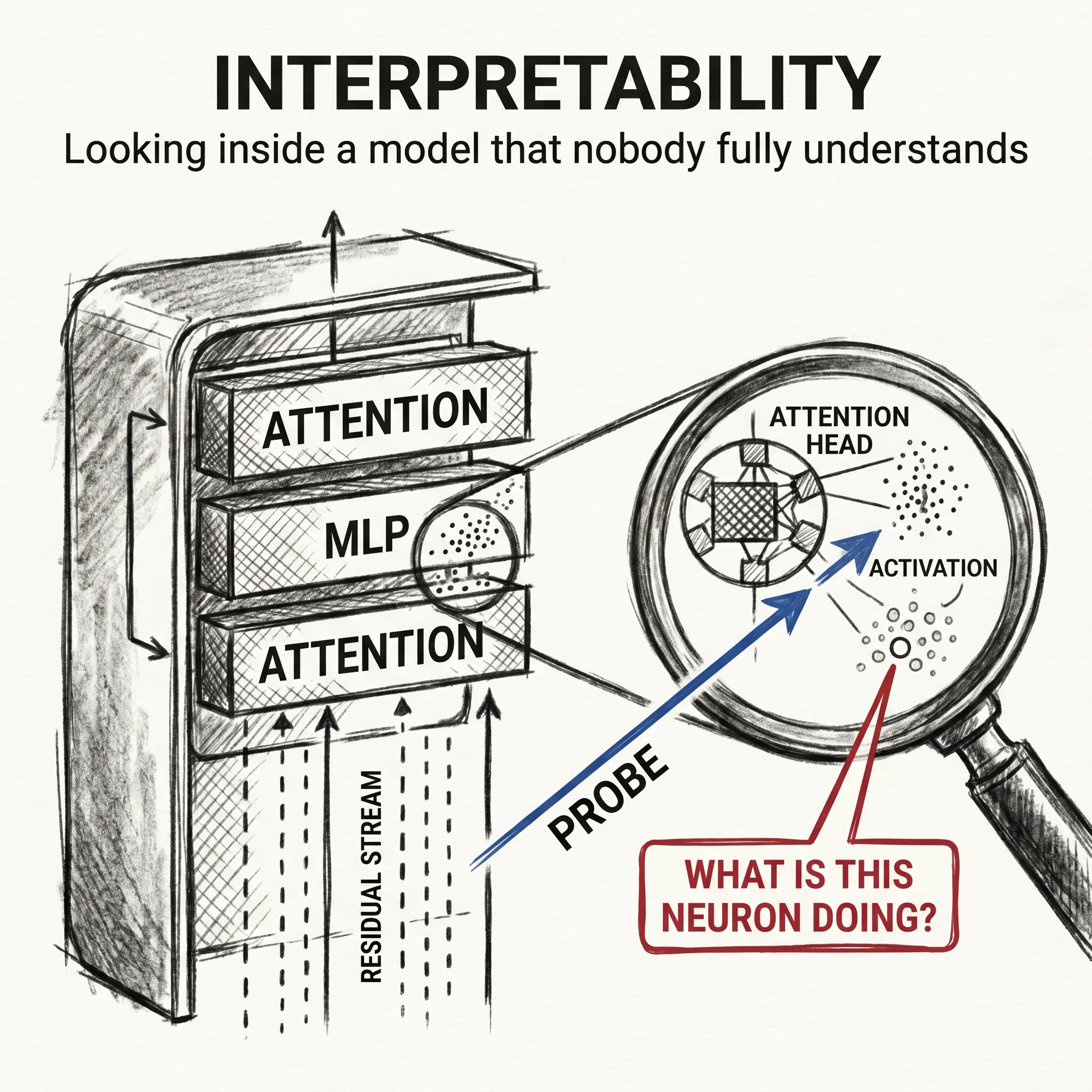
A modern language model is a stack of matrices with hundreds of billions of parameters. We trained it, we run it, we measure it on benchmarks. Ask any researcher how a specific answer comes out of that stack and the honest reply is some version of “we are working on it.”
That is a strange place to be. We have built the most capable software systems in history, and we cannot read them. Imagine shipping a Boeing 787 where the avionics work fine on every test flight, but no engineer in the building can draw the wiring diagram. Interpretability, the field that tries to read them, has finally entered a phase that feels like real progress instead of polite hope.
WHY THIS MATTERS AT ALL
The case for interpretability is not academic curiosity. It is closer to the case for crash investigation in aviation.
When a model behaves well, you can ship it and pretend the inside does not matter. When it behaves badly, hallucinates, is jailbroken, refuses for the wrong reason, or quietly gets something subtly wrong, the question “why did it do that” stops being optional. Without interpretability, the answer is always a shrug and a fine-tune. With interpretability, eventually, the answer is a pointer to the specific circuit that misfired.
There is also a safety argument that gets stronger as models get more capable. If a future model has goals that diverge from ours, behavioral testing alone may not catch it, since a sufficiently smart system can pass tests it has reason to pass. Reading internals is the only check that does not require trusting the very thing under review, and that is the alignment community’s bet. Ever interviewed a charming candidate who told you exactly what you wanted to hear?
THE OLD TOOLBOX
Interpretability is not new. The tools just used to be much weaker.
The first generation was saliency maps: highlight which input tokens the model looked at when producing an output. These are easy to make and easy to misread. A saliency map tells you correlation, not mechanism, the way a thermal camera tells you a person is warm without telling you what they are doing.
The second generation was probing. Train a tiny linear classifier on a model’s internal activations to see whether some concept lives there, like grammatical gender, or sentiment, or country of origin. Probes proved that representations exist for surprising things, but they did not show how the model puts those representations to work downstream. Finding a fact somewhere in the activations is not the same as knowing how the model uses it to answer a question.
Both tools are still useful. They are also nowhere near enough for a 70B parameter model with hundreds of attention heads per layer.
THE MECHANISTIC TURN
Around 2021 a different approach started to work. Instead of probing what a model knows, mechanistic interpretability asks what algorithm a model is running.
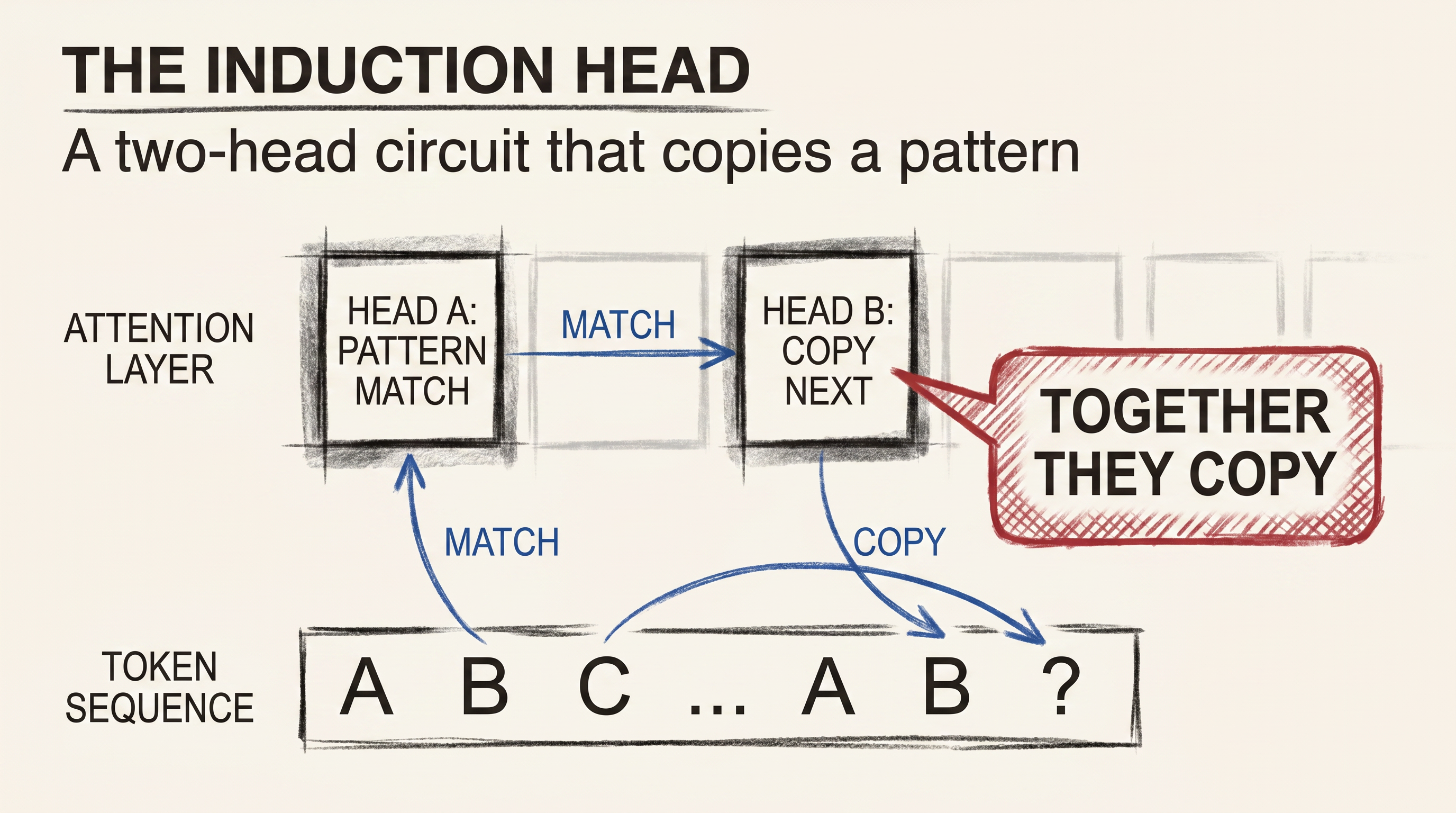
The unit of analysis stops being the input or the layer and becomes the circuit: a small subgraph of attention heads and MLP neurons that together implement a specific computation. The classic early result was the induction head, a two-head circuit that lets a transformer copy a pattern it has seen earlier in the context. The discovery was not that copying happens, anyone could see that. The discovery was that you could point at the exact two heads doing it and break the behavior by ablating them.
That is a different kind of explanation. It is the difference between saying “the engine makes the car go” and saying “this specific gear, meshed with that specific shaft, transmits torque to the rear axle.” Once you can do that, you can reason about what changes when you swap a part.
SUPERPOSITION AND SPARSE AUTOENCODERS
Then came the wall. When researchers tried to find clean circuits in larger models, the neurons stopped being clean.
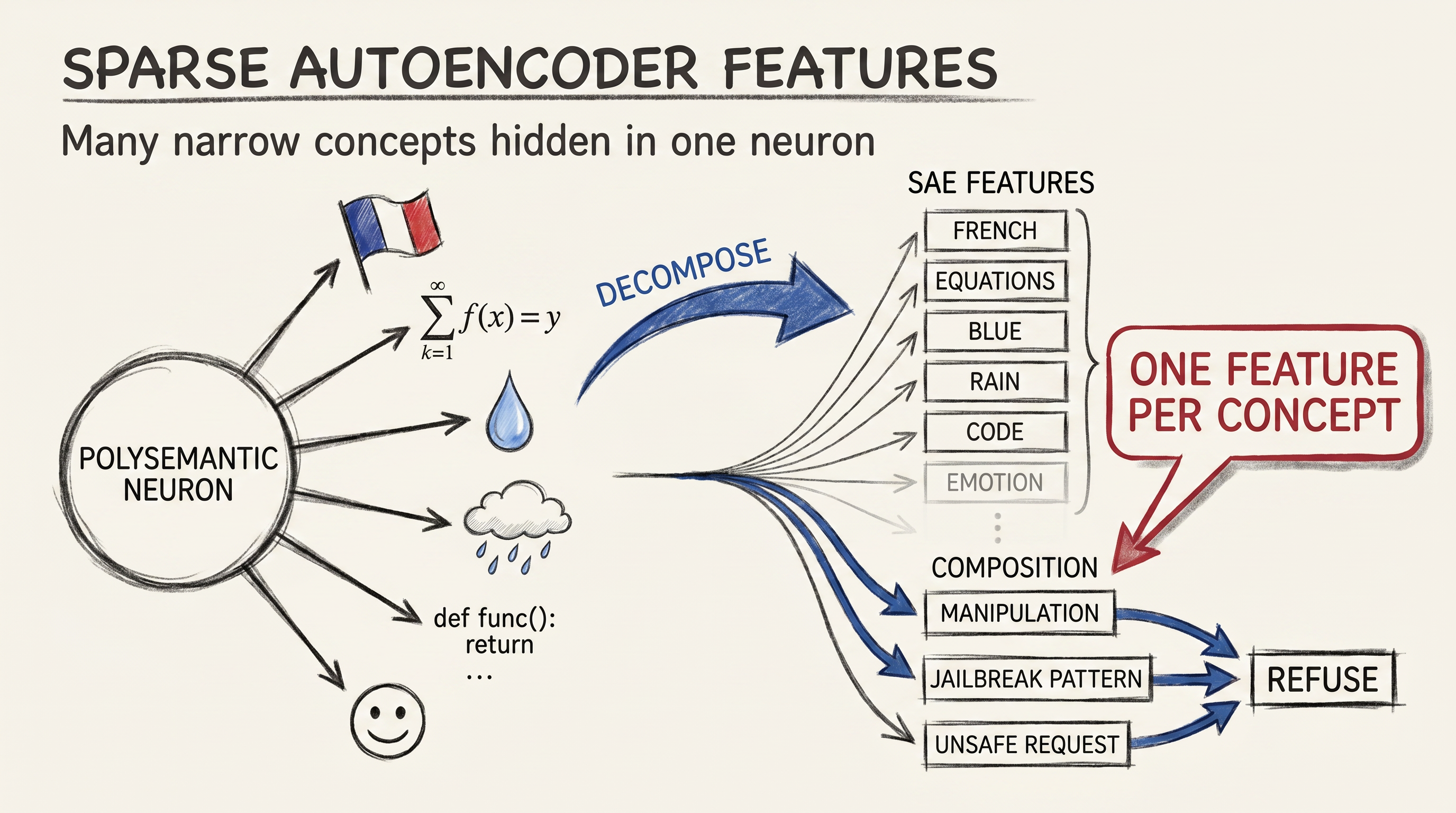
A given neuron would respond to a dozen unrelated concepts: French text, scientific notation, the color blue, the smell of rain in writing. This is superposition, the idea that models pack many more features into their hidden dimensions than they have neurons by overlapping them in clever ways. Picture a small office cramming six startups into one open-plan floor, each one ignoring the others when they happen to be in at the same time. Models are bandwidth-limited and features are sparse, so jamming several rarely co-occurring features into one direction is efficient.
The breakthrough of 2023 to 2025 was the sparse autoencoder, or SAE. It is a small auxiliary network trained to reconstruct a model’s activations using a much wider but mostly off basis. Most of the SAE’s neurons stay silent, and the few that fire correspond to interpretable features. Suddenly, instead of polysemantic neurons that meant six things at once, you had millions of monosemantic features, each one a coherent concept.
Anthropic’s Golden Gate Claude was the demo that made this concrete. They found a feature that activated on the Golden Gate Bridge, clamped it to high values, and the model started believing it was the bridge in every conversation. That is not a parlour trick. It is direct evidence that a specific direction in activation space corresponds to a specific concept, and that you can intervene on it surgically.
WHAT WE HAVE ACTUALLY FOUND
The features are stranger and more specific than anyone expected.
Researchers have catalogued features for code bugs, for sycophancy, for refusing requests, for unsafe instructions, for deception, and for very narrow things like a function call with the wrong number of arguments. Not all of these generalize on closer inspection. Quite a few do.
The interesting wrinkle is that features compose. A refuse this request feature may sit downstream of a this looks like a jailbreak attempt feature, which sits downstream of features tracking specific manipulation tactics.
When you map the chain, you stop describing behavior and start describing a small program the model is running. Two years ago, the very idea of drawing a circuit diagram of a refusal would have been a joke. Have you ever seen one before now?
THE HONEST LIMITS
This is the part the launch posts skip.
We have interpretability results for medium-sized models and partial results for frontier ones. SAE quality drops as you scale, training one on a 400B parameter model is expensive and the features get fuzzier. We can read individual circuits but not whole behaviors, and the leap from “we found a deception feature” to “we can certify this model is not deceptive” is enormous.
There is also a measurement problem. A feature that activates on deception in evaluation may not be the only deception circuit, may not fire on the deception that matters in deployment, and may correlate with deception without causing it. Interpretability researchers are well aware of this, which is why the field obsesses over causal interventions like activation patching and feature ablation. Behavioral evidence alone is not enough, and they know it.
The realistic 2026 status is this. We have moved from “the model is a black box” to “the model is a translucent box with a lot of fingerprints on the glass.” That is real progress. It is also very far from the kind of understanding that would let us trust a powerful model the way we trust a verified piece of software.
The next article changes scale. Interpretability is what is going on inside the model, prompting and retrieval-augmented generation are what you can do from the outside, and most of the practical use in 2026 still lives there.
T.
References
- A Mathematical Framework for Transformer Circuits (Elhage et al., 2021) - The Anthropic paper that named circuits and induction heads, foundational to modern mechanistic interpretability.
- Toy Models of Superposition (Elhage et al., 2022) - The clearest explanation of why neurons in real models are polysemantic and what superposition is actually doing.
- Towards Monosemanticity: Decomposing Language Models With Dictionary Learning (Bricken et al., 2023) - The breakthrough sparse autoencoder paper that turned superposition from a wall into a tractable problem.
- Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024) - The Golden Gate Claude work, showing SAE features at frontier-model scale and surgical activation steering.
- Locating and Editing Factual Associations in GPT (Meng et al., 2022) - The ROME paper, demonstrating that specific factual associations live in identifiable MLP layers and can be edited directly.