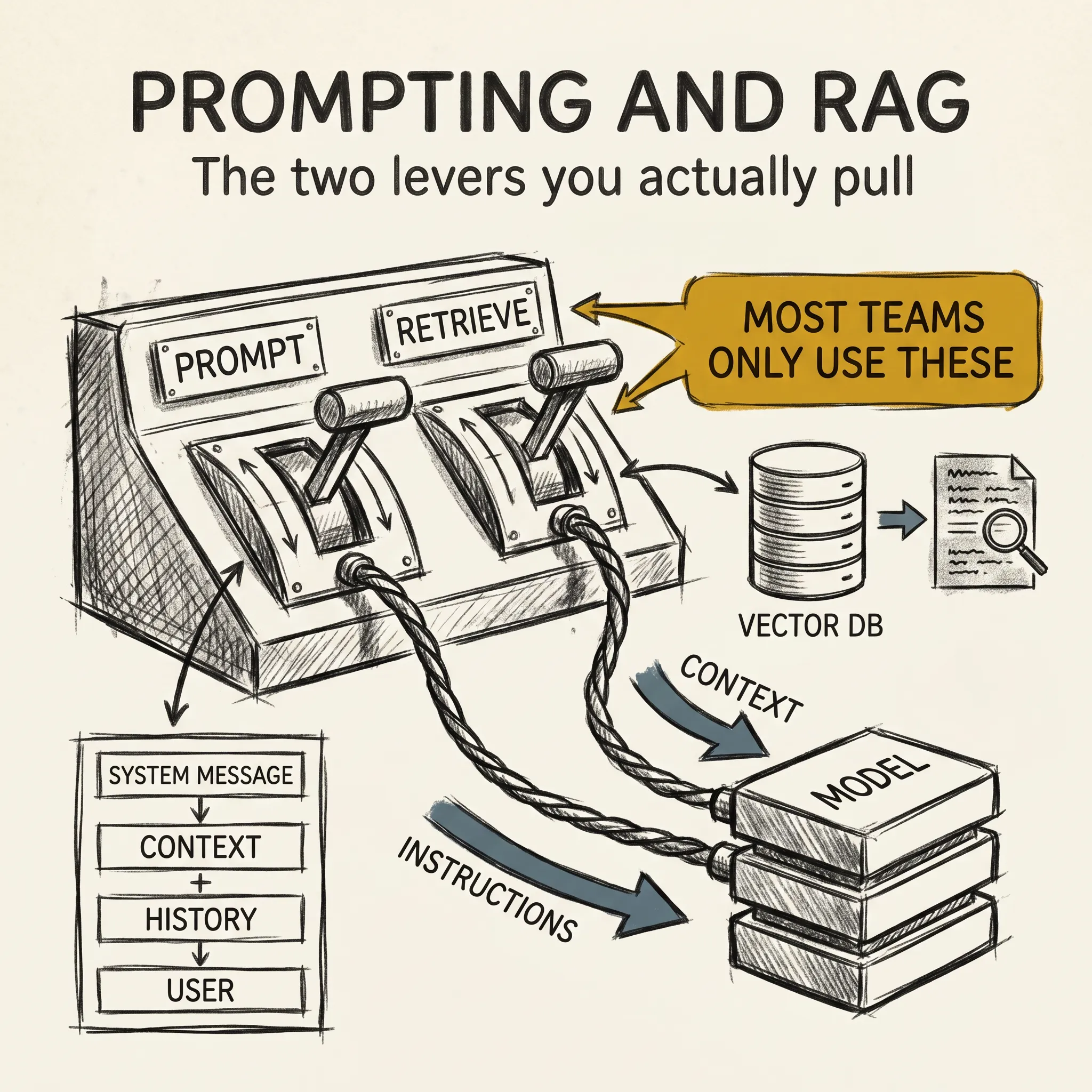
A lot of the content on the AI internet pretends every problem ends in a fine-tune. The reality, even in 2026, is that almost nobody trains a model. The two levers most teams actually pull are prompting and retrieval, and the gap in quality between teams who use them well and teams who do not is enormous.
This article is about those two levers. What they are, what they buy you, where they break, and the small set of choices that decide whether an LLM application feels magical or like a slow chatbot with the wrong answers.
WHY PROMPTING IS NOT JUST TYPING
A prompt is the entire input the model sees, not only the latest user message. That distinction matters more than people think.
In a real application the prompt is a stack: a system message that sets role and rules, retrieved context, conversation history, the current user turn, and sometimes tool definitions. The model has no memory of anything outside this stack. Whatever you forget to include, the model does not know. A new engineer’s first encounter with this fact is usually a bug, the kind where the system prompt forgets to tell the model what year it is and the answers come back vaguely circa 2023.
Good prompting means treating the prompt like an API contract. The instructions are precise, the format is explicit, the examples show the actual output you want, and you address the edge cases before the user finds them. (Spoiler alert: they always do.) The same way a lawyer drafts a contract anticipating how it will land in court, you write the prompt for how the model will parse it when something weird happens.
THE PROMPT TOOLBOX
A few patterns do most of the heavy lifting.
Instruction prompting is the basic form: tell the model what to do in plain language. Modern instruction-tuned models follow direct instructions reliably for most tasks, and the failure mode is usually that the instructions were vague, not that the model could not understand them.
Few-shot prompting adds examples of input and desired output. It works because the model treats the pattern as a continuation of what it has already seen, the way a musician asked to improvise in a key responds better when given a few bars first. Two or three good examples often beat a paragraph of instructions, especially for structured output.
Chain-of-thought prompting asks the model to show reasoning before the answer. We covered this in the reasoning models article, so a short version here. For older models, think step by step was a prompt trick. For 2026 reasoning models, the model does it automatically, and you mostly stay out of the way.
Output structuring is the unsung hero. Asking for JSON with a schema, or a specific tag layout, dramatically reduces parsing pain on the application side. The newer models accept a JSON schema directly and stick to it, which is the difference between a clean integration and a regex graveyard.
WHERE PROMPTING RUNS OUT
Even the best prompt cannot put information into a model that the model does not have.
If your private knowledge base, your customer’s contract, or last week’s incident report is not in the prompt, the model is guessing. Three things bound what prompting alone can do. The context window is finite, training data has a cutoff date, and the model has no privileged access to your private data.
You can stuff a lot of context into a 200K token window, and the new million-token models stretch this further, but stuffing has its own failure mode. Long-context models often perform worse in the middle of very long inputs, the so-called lost in the middle problem. They are also expensive to run at full window length, and they still have a cutoff. Yesterday’s news is not in there.
This is the gap that retrieval-augmented generation fills. Instead of asking the model to know everything, you give it the right small piece of knowledge at the right moment.
RAG IN ONE BREATH
Retrieval-augmented generation is, at its core, a two-step pattern. First you retrieve, then you read.
When a user asks a question, you do not send the question straight to the model. You first look it up against a corpus of your own documents, pull the most relevant snippets, and paste them into the prompt as context. The model then answers using those snippets. In effect, you turned your private corpus into something the model can read at request time, like an open-book exam where the student finds the right page before answering.
The whole pattern lives or dies on the retrieval. A good retriever surfaces the right chunks; a bad one buries the model in noise. The model is only as smart as the context you put in front of it.
THE PARTS OF A RAG SYSTEM
A working RAG pipeline has more moving parts than the marketing makes it sound.
Documents get split into chunks, usually a few hundred tokens each, with a small overlap. An embedding model turns each chunk into a vector, and the vectors live in a vector database like pgvector, Pinecone, or LanceDB. At query time, the database embeds the user’s question the same way and returns the closest chunks, which is a proxy for semantic similarity.
Then comes the part most tutorials skip. The top similarity matches are not always the right answer, so a reranker, a smaller model that scores query-chunk pairs more carefully, reorders the results before they reach the prompt. The reranked top chunks become context. The model reads them and answers.
The whole loop runs in under a second on a tuned setup. The user sees a chat reply that magically references their internal documents. Behind the curtain, three different models and a database collaborated to produce it.
WHERE RAG GOES WRONG
The interesting failures are not the obvious ones.
Bad chunking is the silent killer. Split a long policy document mid-sentence, and the model sees half a clause and confidently answers wrong, like a witness who only heard part of the question. Chunk too large and the retriever cannot tell what is actually relevant. Chunk too small and you lose the surrounding context that makes a passage meaningful.
Skipping the reranker is the second mistake. Pure vector similarity gets you most of the way, but the top match is often plausibly relevant rather than actually correct. A reranker turns vague similarity into actual relevance, and the quality jump is bigger than people expect.
Then there is the metadata problem. Two chunks can be identical in content and totally different in authority, one is a draft, one is the signed contract. If your retriever does not know that, neither does your model. Real RAG systems carry source, date, version, and trust signals through the pipeline, and the prompt tells the model what to do with them.
There is a deeper limit. Retrieval is only as good as the question. If the user asks an oblique question about a topic, the embedding lands in the wrong neighborhood and the right chunks never surface. Some teams now use a small LLM to rewrite the query before retrieval, which is one more model in the stack.
THE PRACTICAL DECISION
Here is the rough decision tree most teams converge to in 2026.
If the task is general reasoning or writing, prompt the model well and stop. If the task needs current or private information, add RAG. If the task needs a specific format or style at scale, fine-tune a small model with LoRA on top of the prompt and retrieval, not instead of them. Almost nobody needs to train a base model.
The gap between mediocre and excellent applications is rarely the model. It is whether the team takes prompting seriously as engineering, builds retrieval that actually surfaces the right context, and instruments the system to see what is going wrong. Boring work, mostly. The good results live there. Have you ever shipped an LLM feature and spent the next month tuning the prompt rather than the model?
The next article gives the model a third lever, the ability to call tools and run actions, which is where the agentic side of 2026 actually starts.
T.
References
- Lost in the Middle: How Language Models Use Long Contexts (Liu et al., 2023) - Empirical evidence that long-context models perform worse on information placed in the middle of the input, foundational to chunking and reranking decisions.
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Lewis et al., 2020) - The original RAG paper, including the architecture and motivation that shaped the modern stack.
- The Prompt Report: A Systematic Survey of Prompting Techniques (Schulhoff et al., 2024) - A 76-page taxonomy of prompting patterns, useful as a reference for which techniques actually move the needle.
- Anthropic Prompt Engineering Guide - Practical patterns for system prompts, structured output, and tool use, written by the lab whose models you are likely to be calling.
- Pinecone Vector Database Learning Center - Plain-English explanations of chunking, embeddings, retrieval, and reranking from a vendor that lives this stack daily.