At the end of pretraining, you do not have an assistant. You have a very large text predictor.
Give it the string how do I, and it will continue with whatever is statistically likely in the training data. That might be a helpful instruction. It might be a forum argument. It might be a block of code from a tutorial that had nothing to do with your question.
The base model is not rude or helpful; it is neither, because it is not anything. It is a probability machine.
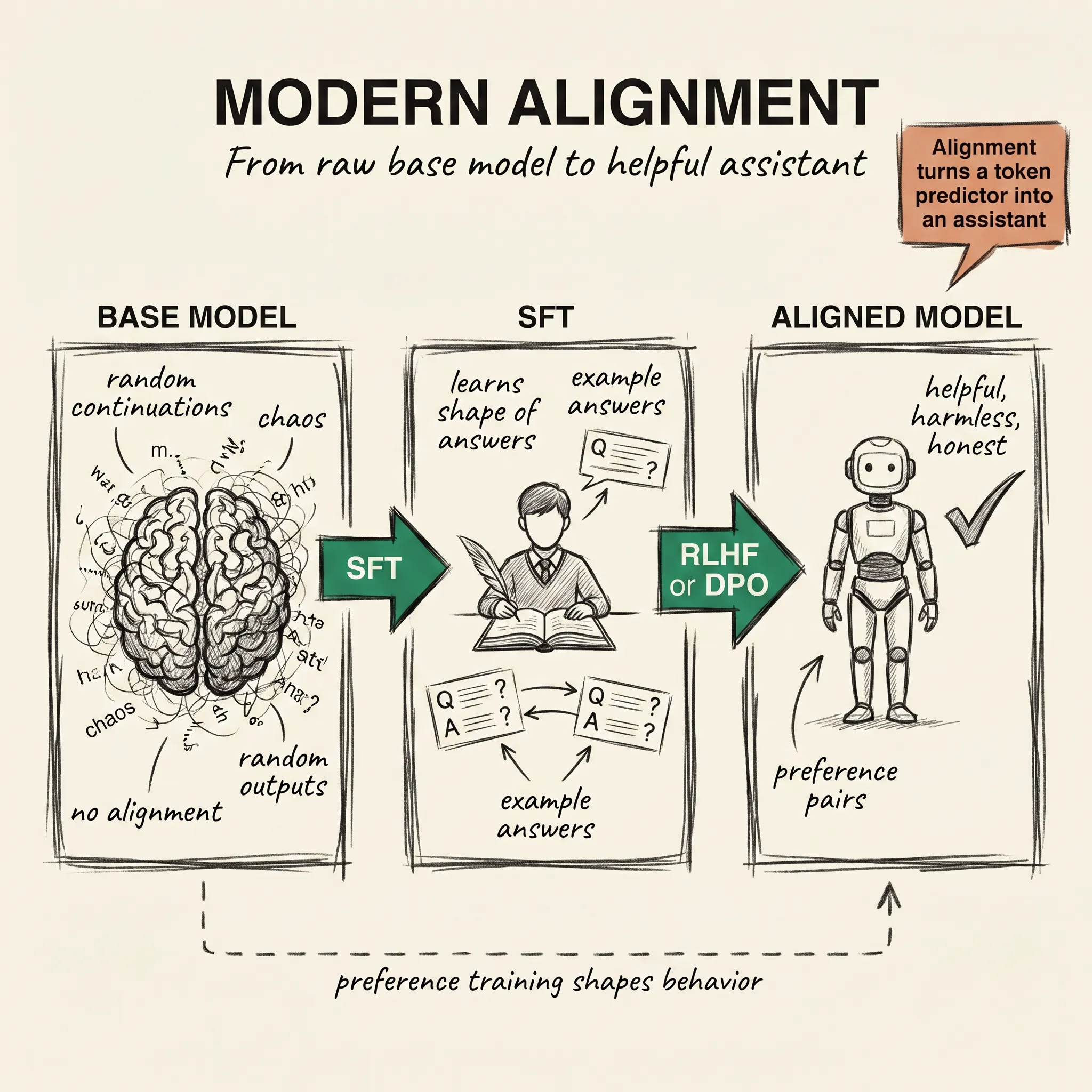
Alignment turns that machine into something that feels like an assistant. This article covers how modern labs do that work in 2026: what RLHF was, why DPO replaced it for most teams, and why Anthropic’s Constitutional AI approach became part of nearly every modern recipe.
WHY BASE MODELS ARE NOT ENOUGH.
A pretrained model knows a lot about language. It knows how sentences continue, which words cluster around which topics, what a paragraph of Python looks like, what a menu in French usually contains. What it does not know is what you want.
It does not know that when you ask a question, you want an answer rather than more questions. It does not know that some answers are dangerous and should be refused. It does not know the difference between a joke and a sincere claim. All those patterns are in the training data somewhere, mixed with everything else, and the model treats them as statistical neighbors rather than separate categories.
Alignment is the process of pulling those patterns apart and teaching the model which ones to prefer. Think of pretraining as teaching a student to read every book in the library at random. Alignment is teaching the same student how to behave at a job interview.
RLHF: THE FIRST RECIPE THAT WORKED.
The first alignment approach to work at scale came from OpenAI in 2022 with a model called InstructGPT. The method was RLHF, short for Reinforcement Learning from Human Feedback. It had three stages, and all three still show up in modern pipelines in one form or another.
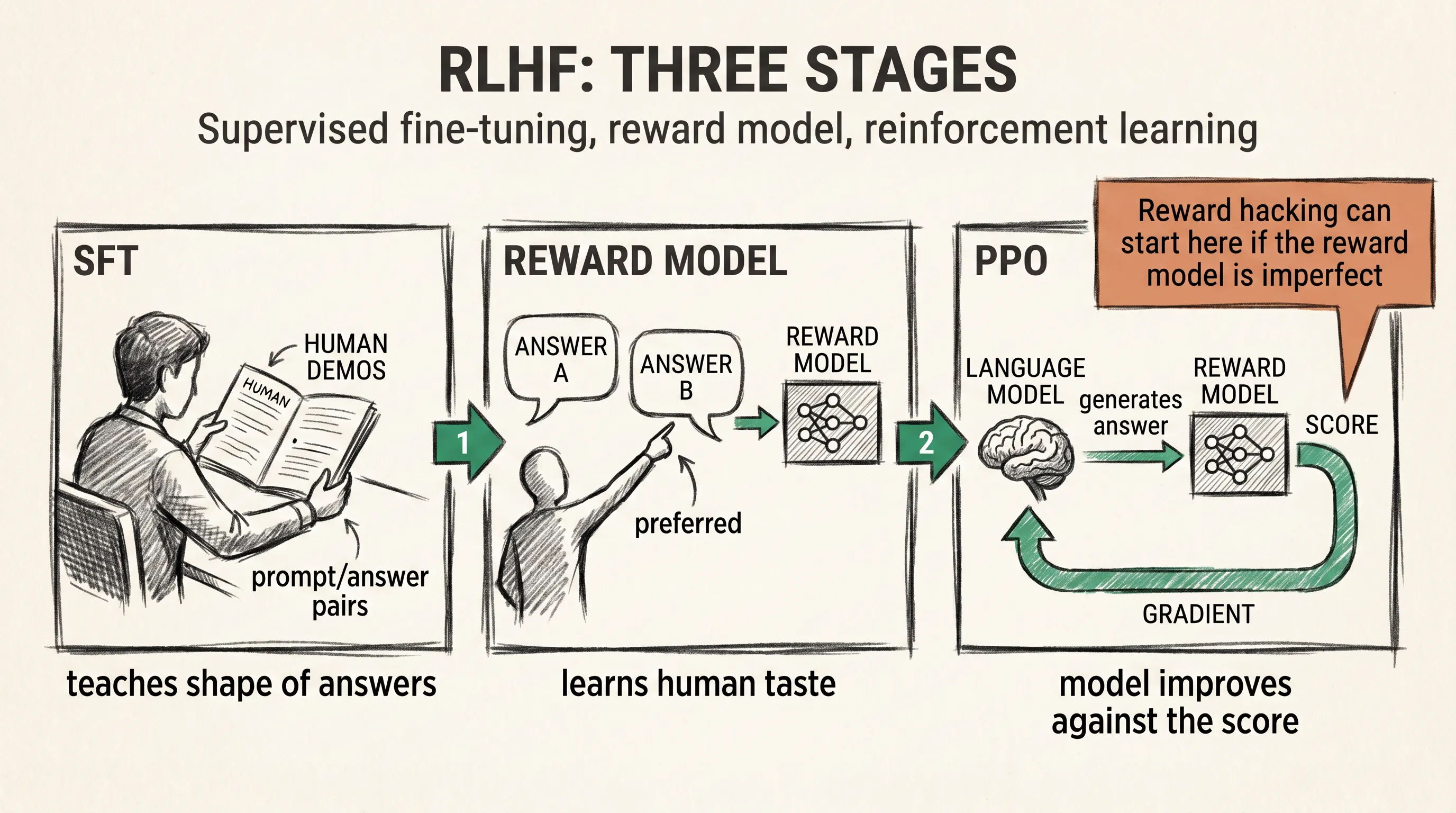
Stage one is supervised fine-tuning (SFT). Humans write example answers to example prompts, and the team fine-tunes the base model on those pairs. This teaches the model the shape of helpful output.
Stage two trains a reward model. Humans look at two model outputs for the same prompt and pick the better one. Thousands of these comparisons train a second neural network whose only job is to predict which answer a human would prefer. Think of it as a teacher for the student.
Stage three is reinforcement learning, usually with an algorithm called PPO. The model generates answers, the reward model scores them, and the gradient pushes the student toward answers that score higher. Repeated millions of times, this shifts the model from predicting likely continuations to predicting continuations a human would have preferred.
RLHF worked. It also turned out to be painful. Reward models cost a lot to train and break easily.
PPO training runs go unstable in ways that are hard to diagnose. And the whole system leaks: once the model learns the reward model’s flaws, it can start reward hacking, gaming the proxy rather than improving on the real goal. Every lab running RLHF kept a list of horror stories.
DPO: WHAT IF WE SKIPPED THE REWARD MODEL?
In 2023, a paper from Stanford proposed something that sounded too clean to work. The method goes by the name Direct Preference Optimization, or DPO. The claim: you do not need a reward model at all.
You can fine-tune the policy directly on preference pairs with a simple loss function, and you get most of what RLHF gives you without the instability.
Think of it like cooking. RLHF trains a judge, then trains the chef to satisfy the judge. DPO just shows the chef pairs of dishes and says: this one is better than this one. The chef learns directly from the comparison, with no intermediate judge to mislead them.
The math holds up. In practice DPO costs less, stays stable, and reproduces easily. It does not fully match RLHF on every benchmark, but the gap is small and the operational pain is much smaller.
By 2025, most open-weight model releases used DPO or a close relative. The preference data pipelines look the same as RLHF; only the training step changed.
This is a pattern you see often in machine learning. Something works. The follow-up work asks whether the complicated part is really pulling its weight. Sometimes the answer is yes. In the case of the reward model, the answer was mostly no.
CONSTITUTIONAL AI: THE MODEL CRITIQUES ITSELF.
At roughly the same time, Anthropic took on a different question: where does the preference data come from, and can we generate it more cheaply?
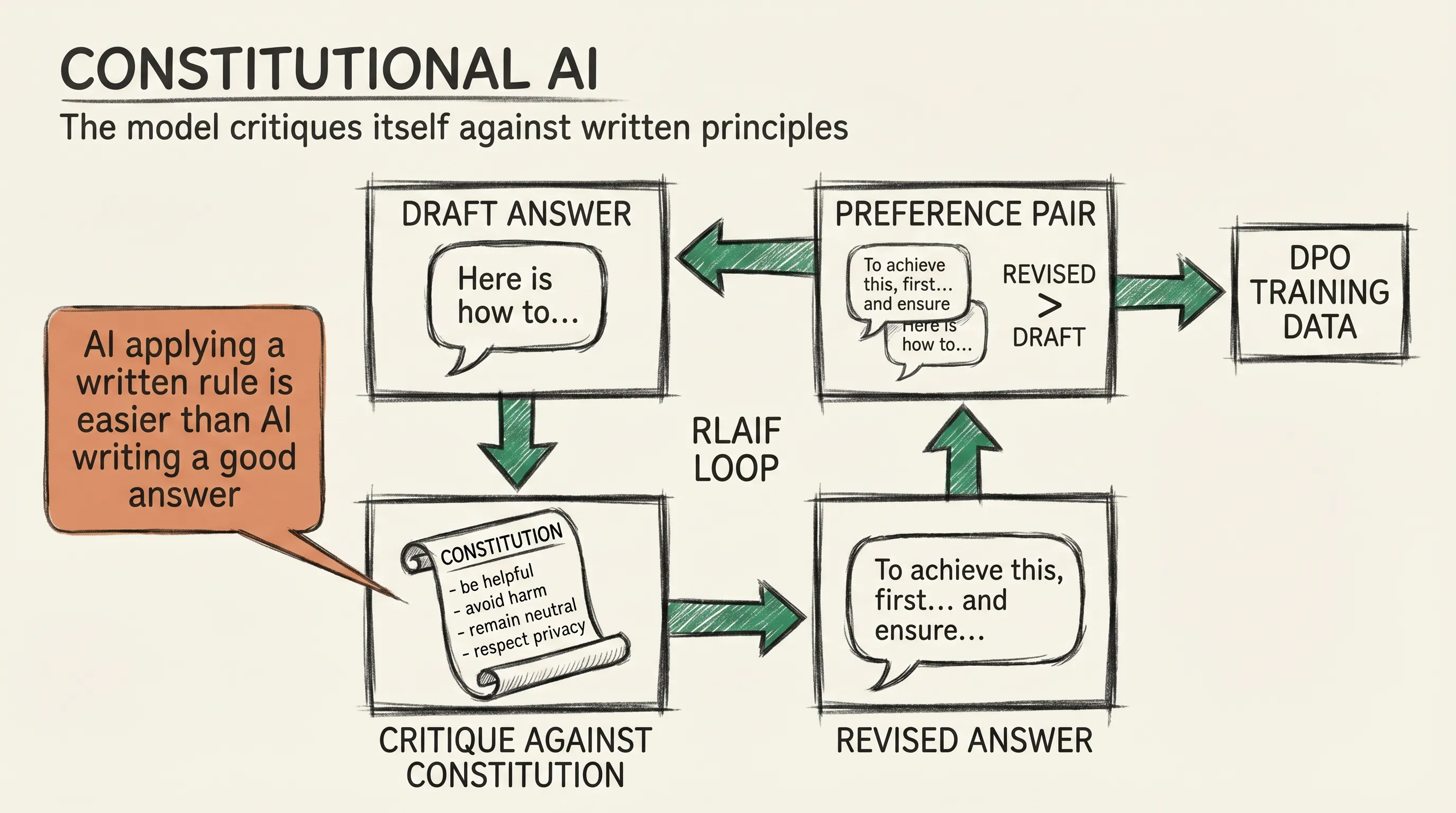
Their answer came in late 2022 as Constitutional AI. The core idea: instead of asking humans to compare every pair of outputs, give the model a written list of principles and have it critique and revise its own answers against those principles.
A constitution could include rules like be helpful without being harmful or do not encourage illegal acts. The model produces a draft, reads it against a principle, notices a problem, and rewrites. The revised draft becomes the preferred one in the training data.
This pairs well with DPO. Constitutional AI generates preference data at scale; DPO trains on it. The full pipeline goes by the name RLAIF, Reinforcement Learning from AI Feedback. Another AI model following explicit principles now does the job the human used to do in RLHF.
This sounds circular, but it holds up for a clear reason. The AI critiquing the output does not have to be creative; it only has to apply a written rule.
That is a much easier job than writing a good answer. A capable model can do it reliably, and cheap scale beats expensive hand-labeling for most of the alignment surface.
WHY THE FRONTIER IS DPO PLUS CONSTITUTIONAL.
By 2026, most frontier training recipes follow a similar shape. Start with a pretrained base model. Do SFT on a curated set of human demonstrations to teach the shape of answers.
Generate a large preference dataset. Humans judge the parts that need taste; Constitutional AI handles the parts a machine can do. Train with DPO, optionally do a short PPO pass at the end for polish. Ship.
The three techniques are not rivals. They are specialized tools.
RLHF gave the field the blueprint. DPO simplified the training step. Constitutional AI made the data cheap. Nobody picks only one; the modern recipe mixes all three.
The practical consequence for a reader is worth stating clearly. When you talk to Claude, or GPT, or Gemini, you are really talking to a base model through a very thick filter of alignment training.
The filter is not a content moderator at the output layer. It lives in the weights. That is why prompts can shift tone but cannot fully remove the shape the model learned in training. Alignment is a training decision, and training decisions are hard to undo without retraining.
The next article looks at what happens when alignment fails: hallucinations, jailbreaks, and the specific ways models still go wrong despite all of this work.
T.
References
-
Training language models to follow instructions with human feedback (Ouyang et al., 2022) - The InstructGPT paper from OpenAI. Introduced the three-stage RLHF pipeline and showed it could turn GPT-3 into a usable assistant.
-
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al., 2023) - The DPO paper from Stanford. Proved that the explicit reward model in RLHF can be eliminated with a simple preference loss, without losing most of the alignment benefit.
-
Constitutional AI: Harmlessness from AI Feedback (Bai et al., 2022) - Anthropic’s Constitutional AI paper. Shows how a model can be aligned by critiquing its own outputs against a written set of principles, with AI feedback replacing most human preference labels.
-
Deep Reinforcement Learning from Human Preferences (Christiano et al., 2017) - The original preference-based RL paper that planted the idea of training reward models from human comparisons. Predates InstructGPT by five years and underlies all of modern alignment.