Ask a 2022 chatbot whether 9.11 is larger than 9.9. There is a good chance it tells you yes.
The model is reading the numbers as version strings. Nine-point-eleven looks bigger than nine-point-nine because eleven is bigger than nine, and the pattern of version 9.11 is newer than version 9.9 shows up everywhere in the training data.
The arithmetic answer is sitting in there too, but the wrong pattern wins. The model gives you the first plausible thing it sees.
Now ask a 2026 reasoning model the same question. It pauses, writes a short internal note, lines the digits up, compares them, and tells you 9.9 is larger.
Same model family, same weights in many cases. What changed is permission to think before answering.

The previous article covered alignment, the training stage that decides how a model behaves. Reasoning models are about a different decision: how long the model gets to think, and what we train it to do with that time. This article covers the chain-of-thought breakthrough, the test-time compute shift that followed, and a simple rule for when to reach for these models.
A NEW RECIPE, NOT A NEW ARCHITECTURE.
It is tempting to assume that o1, o3, DeepSeek R1, Claude with extended thinking, and Gemini Deep Think run on some new transformer variant. They do not.
The architecture under the hood is the same transformer covered in earlier articles. The breakthrough lives in two places: a training recipe that rewards good reasoning chains, and an inference setup that lets the model emit a long internal scratchpad before its final answer. Think of it like a student who can show their working on the back of the page before writing the answer on the front.
The model thinks in the same tokens it would otherwise speak. Those tokens just stay private and the answer comes at the end.
This matters because reasoning is not a property of one specific model. It is a mode you can train any sufficiently large transformer to enter. The frontier labs all reached it at roughly the same time from different starting points, which usually signals that the underlying idea was waiting to be picked up.
THE CHAIN-OF-THOUGHT BREAKTHROUGH.
The first crack in the door came from a 2022 Google paper on chain-of-thought prompting. The authors noticed something almost embarrassing.
Ask a model a math problem and it usually got the answer wrong. Add the words let us think step by step to the prompt, and accuracy jumped, sometimes by a lot.
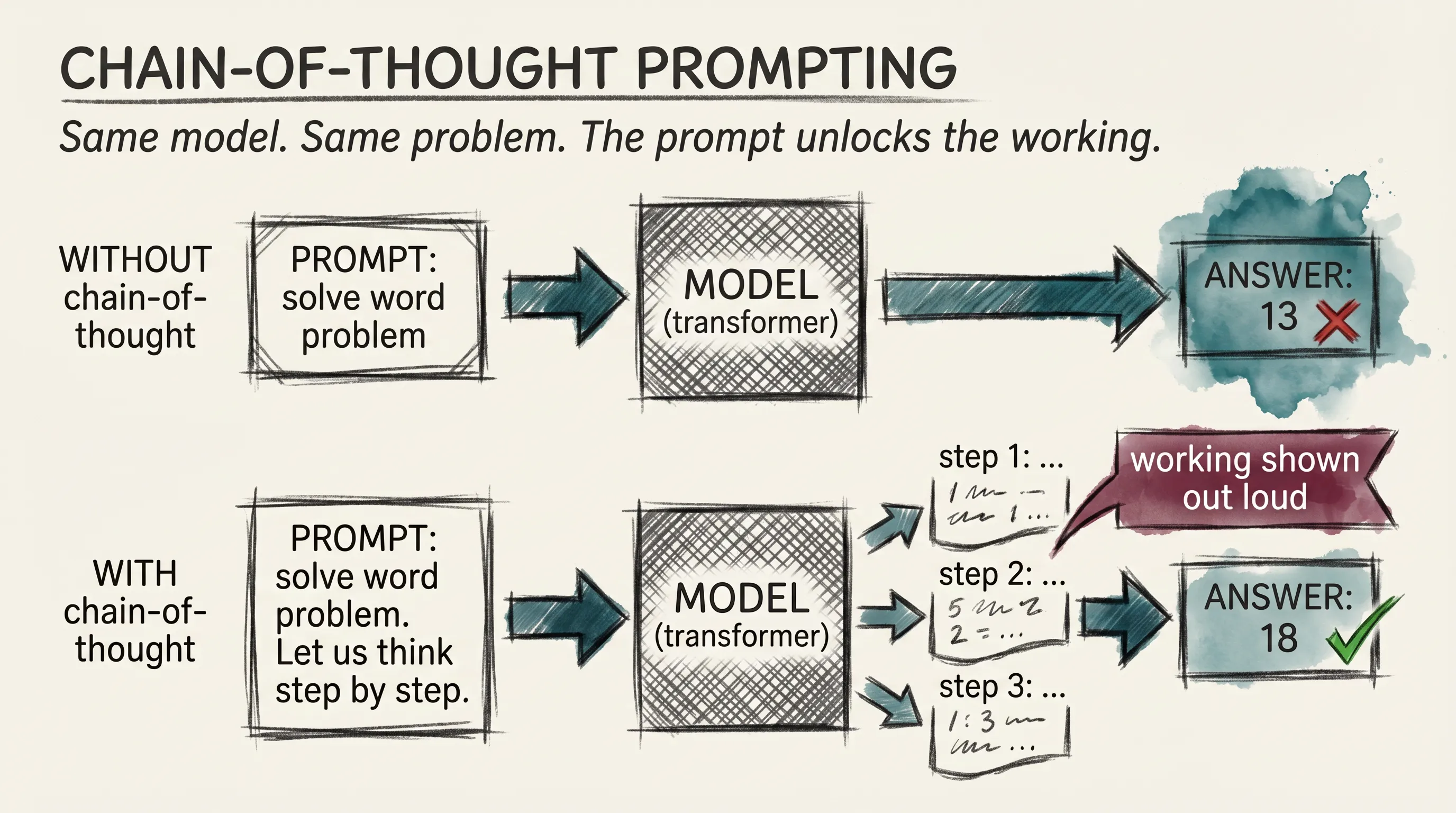
Nothing about the weights changed. The model already had the ability to do the working. It just was not using it by default, because most of its training data did not show working. Adding a few words to the prompt unlocked behavior that was already there, like a chess player who plays badly until you tell them to actually look at the board.
That observation reframed the whole problem. If the model already knew how to reason and just needed to be asked, the next step was to train it to ask itself. Why leave that to the user every time?
TRAINING THE MODEL TO THINK.
The training paradigm that emerged goes by the name reinforcement learning from verified rewards, or RLVR. It sits close to RLHF in spirit, with one key difference. Instead of a reward model trained on human preferences, the reward signal comes from a verifier.
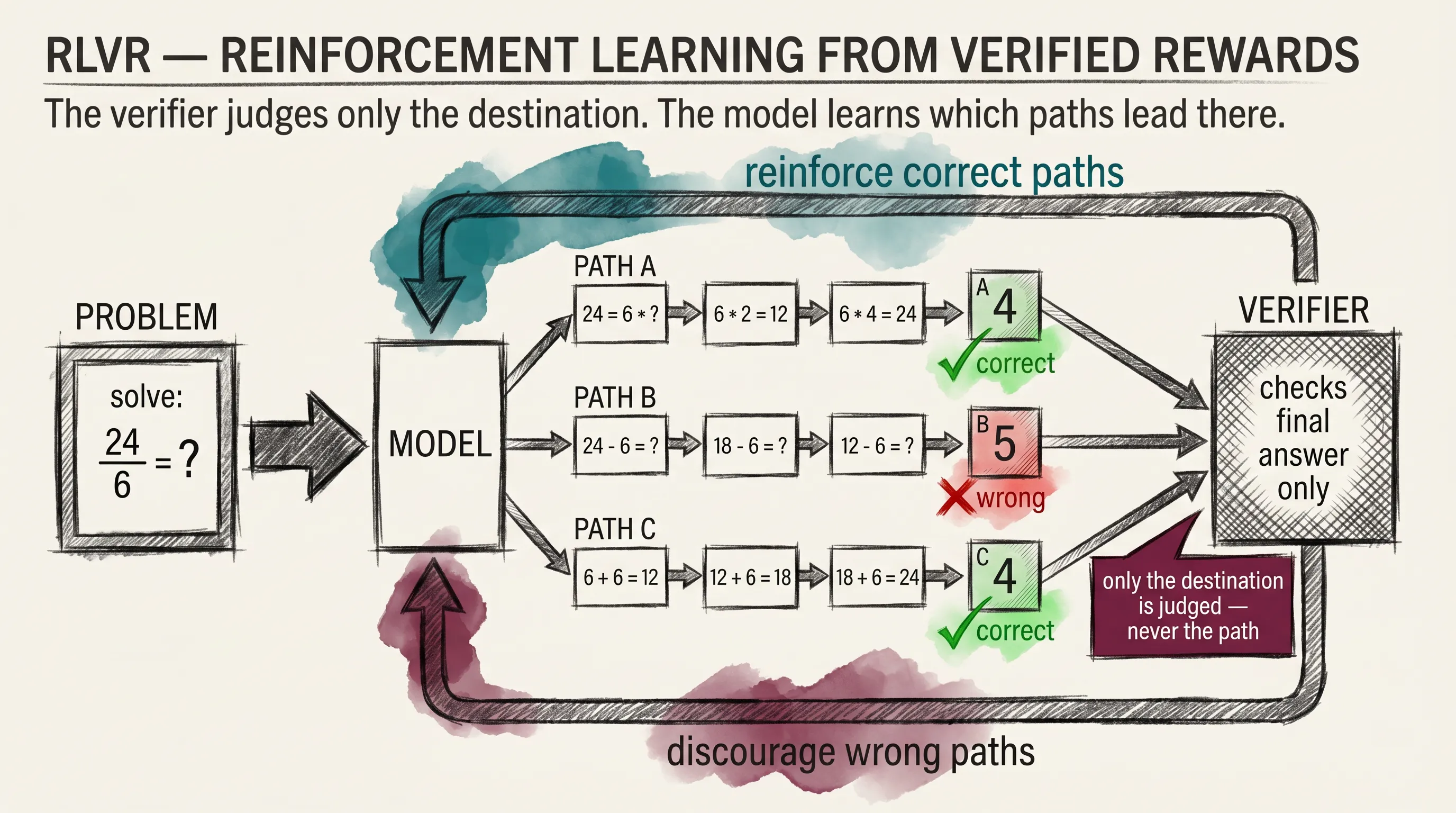
For math, the verifier checks whether the final answer is correct. For code, it runs the code against the tests. For logic puzzles, it compares the answer to the ground truth. Whatever the path the model took, only the destination gets judged.
That is a powerful constraint. The model tries thousands of paths during training. Paths that reach a verified correct answer get reinforced. Paths that wander get discouraged.
Over time the model learns to spend its tokens on patterns of thought that actually pay off: checking its own work, listing edge cases, backtracking when something does not add up. Picture a maze where every successful run lights up the path; after enough runs, the lit corridors form the strategy.
The behaviors that emerge look surprisingly human. A reasoning model will write wait, let me reconsider that, or I made an arithmetic error in the last step, let me redo it. Nobody hand-coded those habits. The training rewarded them into existence because they led to higher answer accuracy.
TEST-TIME COMPUTE: THE 2024 SHIFT.
The other half of the story happens at inference. Until 2024, most labs treated inference as a fixed cost. You buy your tokens, the model speaks them, you get an answer. The big knob for better quality was making the model bigger.
Reasoning models broke that assumption. They showed that on a hard problem, a smaller model that thinks for longer can beat a larger model that answers immediately. Test-time compute became a third lever, alongside training compute and model size.
Think of it like a student taking an exam. A bigger brain helps, but so does extra time on the hard questions.
Until 2024 the field had been making bigger brains. Test-time compute means handing the same brain a longer clock.
In practice this looks like the model emitting a long internal monologue before its visible reply. That hidden monologue can run to tens of thousands of tokens. On a benchmark like AIME or a code competition, more thinking tokens reliably improve the score, often dramatically.
The trade is straightforward. You burn more compute at inference time to get a better answer.
A reasoning model can take thirty seconds, sometimes minutes, to answer a hard question. The cost per query goes up by ten or a hundred times depending on how deep the model goes.
For the right problem the trade is excellent. For a request like what is the capital of France, it is absurd.
WHEN TO USE A REASONING MODEL.
The mental model is simpler than the marketing suggests. Reasoning models earn their cost when the work between question and answer is the hard part. The cost is wasted when the answer is essentially a lookup or a rephrasing.
Reach for a reasoning model on math and quantitative work, multi-step coding tasks, ambiguous specifications that need careful interpretation, planning a sequence of actions, and logic problems where wrong intermediate steps lead to wrong conclusions.
Skip it for casual chat, summarization of clear text, simple translation, and quick factual recall. There is no virtue in burning thirty seconds of compute on a question a base model gets right in one.
A useful rule: if a careful human would want a piece of paper to think it through, a reasoning model probably helps. If a human would answer instantly, a base model probably suffices.
The 2026 model field reflects this split. Most labs ship two flavors: a fast model for everyday traffic, and a thinking model for the harder slice.
Some products switch between them automatically. Others let the user pick. Either way, the days of one model for everything are over for most of the frontier.
The next article in this series turns to multimodality, the work of getting models to see images and hear audio rather than only reading text. That capability changes which problems are tractable at all, and we will look at why.
T.
References
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022) - The Google paper that showed asking a model to think step by step substantially improves performance on math and logic tasks. The empirical result that started the whole thread.
-
OpenAI o1 system card (OpenAI, 2024) - The first public-facing reasoning model release. Documents the test-time compute approach and shows how thinking longer translates into accuracy gains on hard benchmarks.
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-AI, 2025) - The R1 paper. Shows that reinforcement learning from verified rewards produces strong reasoning behavior in an open-weight model, and provides one of the clearest descriptions of the RLVR recipe.
-
Let’s Verify Step by Step (Lightman et al., 2023) - The OpenAI paper that argued for process-supervised reward models, an early step toward training models to value good reasoning paths rather than only correct final answers.