Hold up your phone, point the camera at a printed receipt, and ask the assistant to add up the items and tell you the tip. A 2022 chatbot could not have done this without three separate systems wired together: an OCR engine to read the receipt, a calculator, and a language model to phrase the reply.
A 2026 multimodal model just does it. The same network reads the image, parses the numbers, does the math, and writes the answer. There is no pipeline of glued-together services. There is one model.
The previous article covered reasoning models, the choice of how long a model thinks. Multimodality is a different kind of upgrade: not a longer or smarter model, but a wider one. It changes what counts as input and output. This article covers how images, audio, and video get folded into the same transformer that already handled text, and what that unlocks in practice.
ONE MODEL, MANY CHANNELS.
The naive approach to handling images and text together would be to bolt a vision model onto a language model with some glue code. That is what early systems did. The image went through a separate network, came out as a description, and the description got fed to the language model as text. Two models, one duct tape.
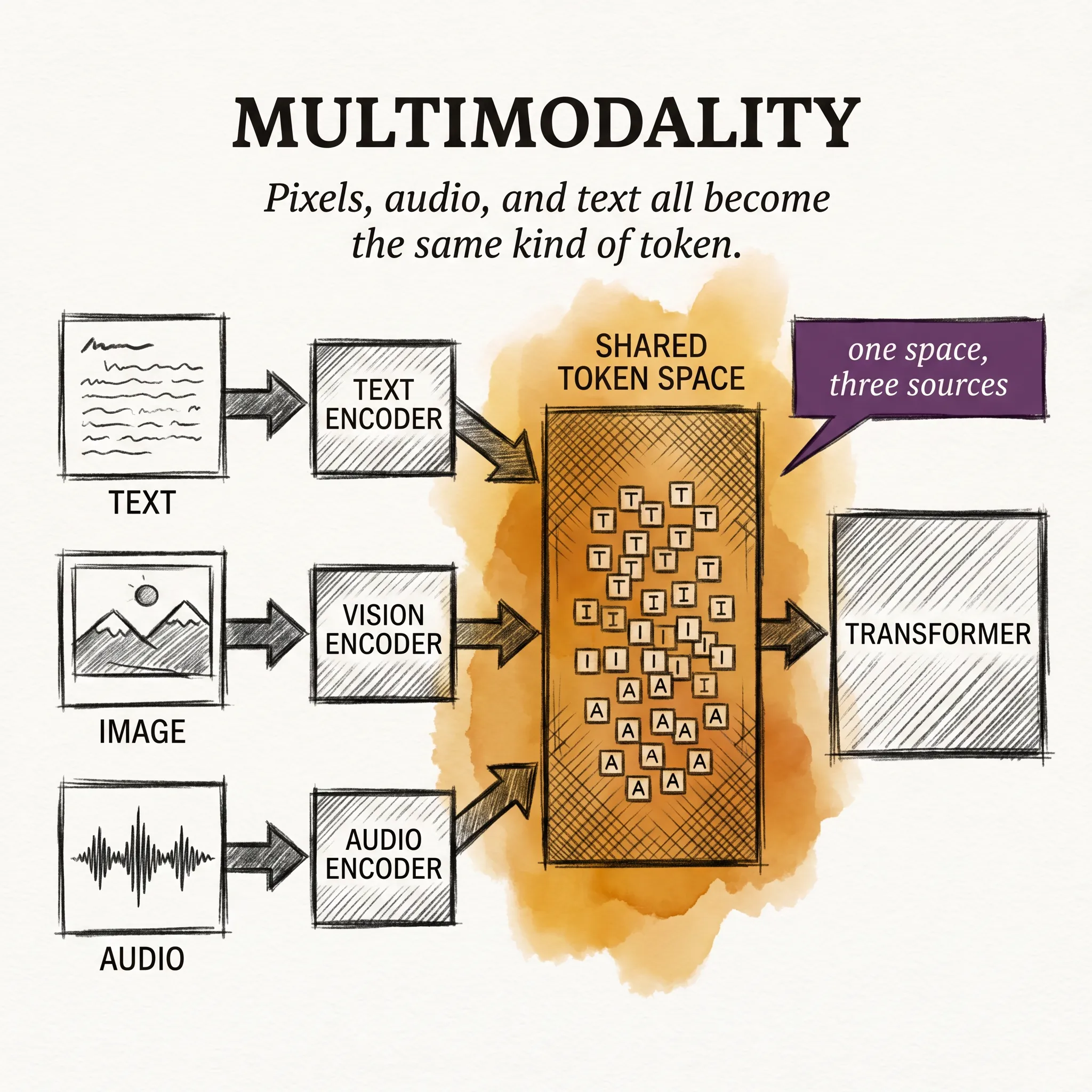
Modern multimodal models do not work like this. One transformer sits in the middle. Pixels, audio waveforms, and characters all get translated into the same kind of token before the transformer ever sees them.
Once they are tokens, they share an embedding space. The model treats a tokenized image and a tokenized sentence as neighbors in the same vector space, and attention works across them the same way it works across two paragraphs of text.
This is why a multimodal model can answer questions about an image without ever generating an English description first. The image and the question live in the same space from the start.
HOW AN IMAGE BECOMES TOKENS.
The trick that made vision practical inside a language model came from a 2020 paper called Vision Transformer, or ViT. It proposed something simple: chop an image into a grid of small square patches, flatten each patch, and treat the resulting sequence as if it were a sentence of tokens.
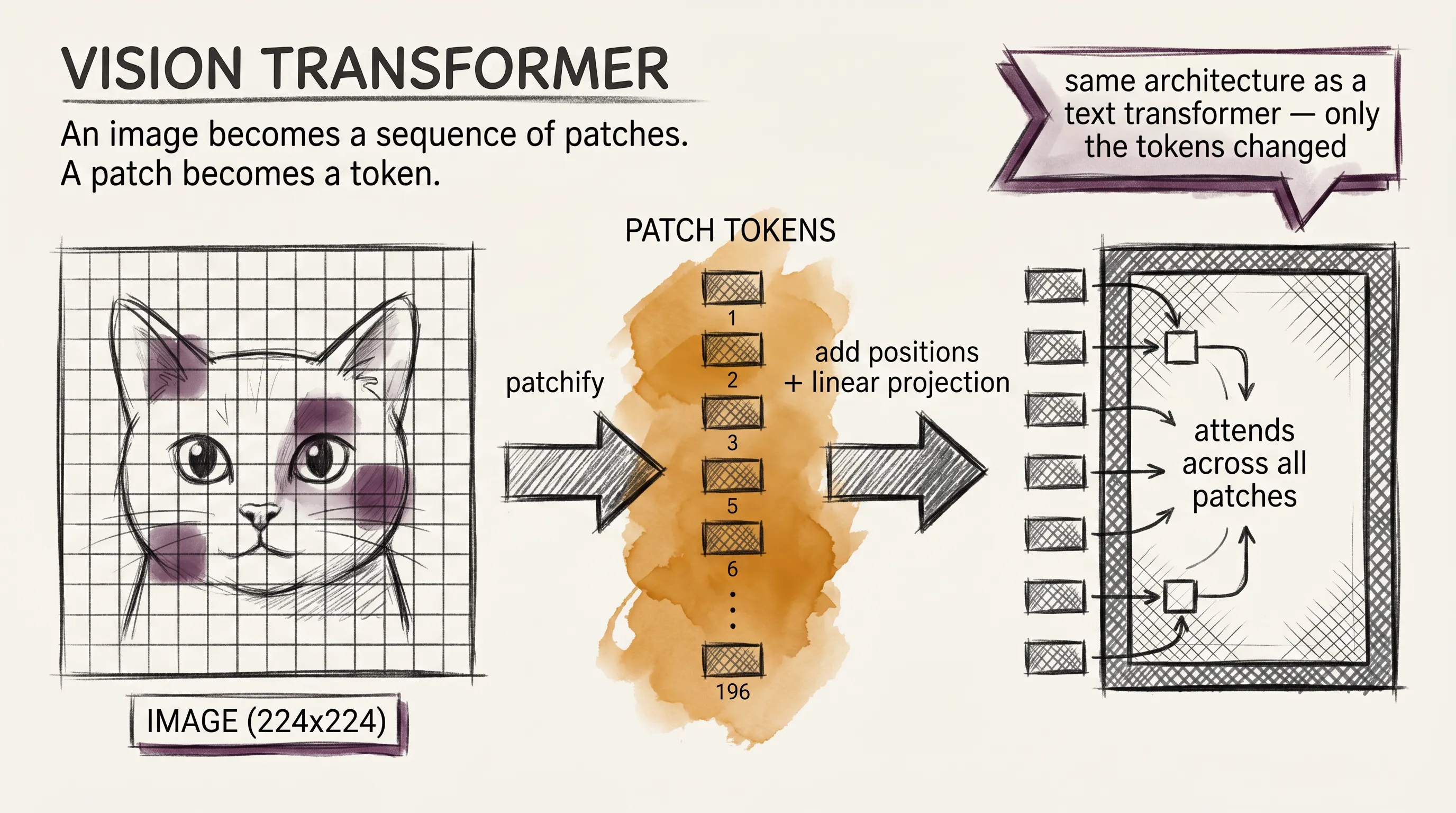
A 224-by-224 image cut into 16-by-16 patches becomes a sequence of 196 patches. Each patch goes through a small linear layer that turns it into a vector. Add positional encoding so the model knows where each patch was in the original image, and you have a sequence the transformer can attend to.
This works for the same reason chain-of-thought worked: the transformer architecture does not care what kind of token it gets, as long as it gets a sequence of vectors with positions attached. Pixels in patches, words in sentences, notes in melodies. Once they look like tokens, attention can do its job.
HOW AUDIO BECOMES TOKENS.
Audio has the same problem with a different shape. A raw waveform is too long and too noisy to feed directly into a transformer. The first wave of audio models converted the waveform into a mel spectrogram, a 2D image of frequency over time, and then treated that image like a vision input.
The newer approach uses a neural audio codec. The codec is a small model that compresses audio into a short sequence of discrete tokens, the way a JPEG compresses an image. Training the codec means optimizing it so the tokens preserve enough information to reconstruct the original sound.
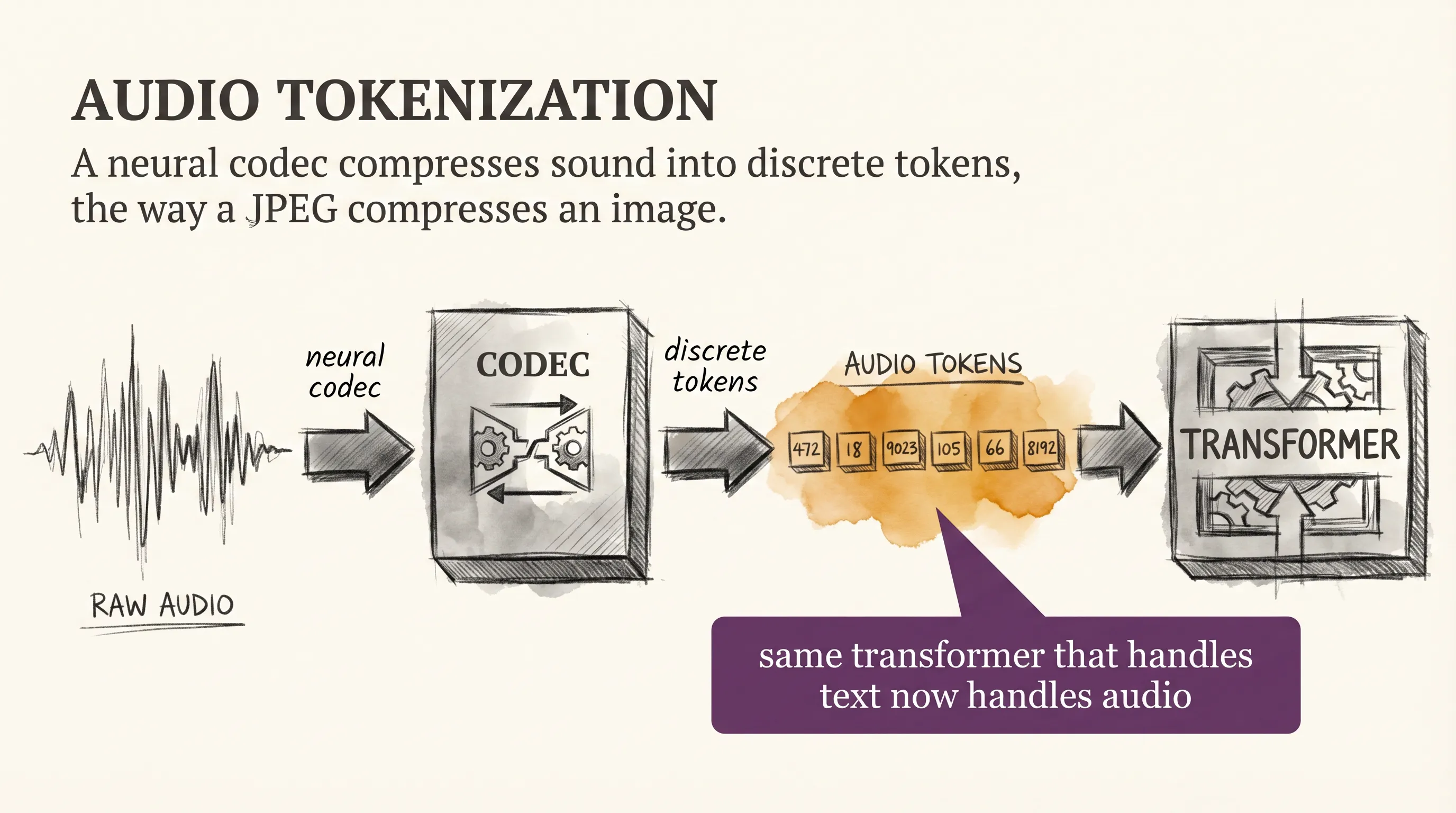
Once audio is a token sequence, the main transformer can read it, generate it, and mix it with text the same way it mixes anything else. This is what made native voice models possible. Old voice assistants did speech-to-text, ran a language model, then ran text-to-speech, losing all the tone and pacing along the way.
A modern voice model trains on audio tokens directly. It hears your tone, your hesitation, the laugh in your voice. It can answer in a tone of its own, not a flat text-to-speech read.
TRAINING THE WHOLE THING TOGETHER.
The architectural picture is only half the story. The training data is the other half.
A multimodal model trains on huge collections of paired data: images with captions, videos with transcripts, audio with text, screenshots with the queries that produced them. The pairing teaches the model that this image and this sentence are about the same thing, so their embeddings should land near each other in the shared space.
Think of it like teaching a child two languages from birth. Adults point at everyday objects while saying the word in both languages. The child does not learn the languages separately and then translate; they learn them as alternative names for the same things. A multimodal model sits in the same position with text and pixels and sound.
By 2026, the frontier models are trained jointly on all four modalities at once: text, image, audio, video. The cross-pairings are what make the model useful. The model can describe a video, read a screenshot, transcribe a song, generate an image from a sentence, and explain a chart, because every one of those tasks is just attention across tokens that happen to come from different sources.
WHAT THIS UNLOCKS.
The capability list reads dry on paper but feels different in practice.
Point and ask becomes natural. Hold a phone up to a circuit board, a recipe, a parking sign in another language, or a textbook diagram, and the model just sees what you see. There is no protocol for describing what you are looking at; you show it.
Screenshot debugging changes how people work with code. A user pastes a screenshot of an error dialog and the model reads the error, recognizes the framework from a logo in the corner, and suggests a fix. None of those steps were possible before vision was inside the model.
Voice assistants finally hear you, not a transcript of you. Tone, sarcasm, hesitation, accent, all of those carry information the old text-only pipeline threw away. A native voice model uses them. Whether that feels useful or unsettling probably depends on the day.
Image and video generation join the same family. The model that reads pixels can also write them. By the time we are talking about Sora, Veo, and the open-weight video models that follow, we are no longer dealing with separate systems for understanding and generation. The understanding model and the generation model share weights or share an architecture.
The next article closes Act II by surveying the 2026 model lineup itself: which labs ship which models, how the frontier and the open-weight world relate, and what to actually pick for a given job.
T.
References
-
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al., 2020) - The Vision Transformer paper. Showed that the transformer architecture, with no vision-specific inductive biases, can match or beat convolutional networks on image classification when fed patches as tokens.
-
Learning Transferable Visual Models From Natural Language Supervision (Radford et al., 2021) - The CLIP paper from OpenAI. Showed that training a joint image-text embedding space on hundreds of millions of internet image-caption pairs produces representations that generalize across tasks. The conceptual ancestor of every modern multimodal model.
-
GPT-4 Technical Report (OpenAI, 2023) - The first frontier-scale demonstration that a single transformer can handle text and images natively, including reading charts, diagrams, and screenshots. The paper that moved multimodality from research to product.
-
High Fidelity Neural Audio Compression (Defossez et al., 2022) - The Encodec paper from Meta. Introduced the neural audio codec approach that lets language models treat audio as a discrete token sequence, underlying most modern native-voice systems.