If you walked away from AI in mid-2024 and came back a year later, you would not recognize the leaderboard. Top-tier models from that era now sit in the middle of the pack. Open-weight releases match closed ones on most benchmarks.
Voice and vision both live inside the same model now. A pricing tier that did not exist eighteen months ago, the thinking model, now eats half the serious queries. Did you see this coming? Most people did not.
This article is the closing piece of Act II. It is a field guide to who ships what in 2026, and a practical way to think about which model to actually pick when you have a job to do.
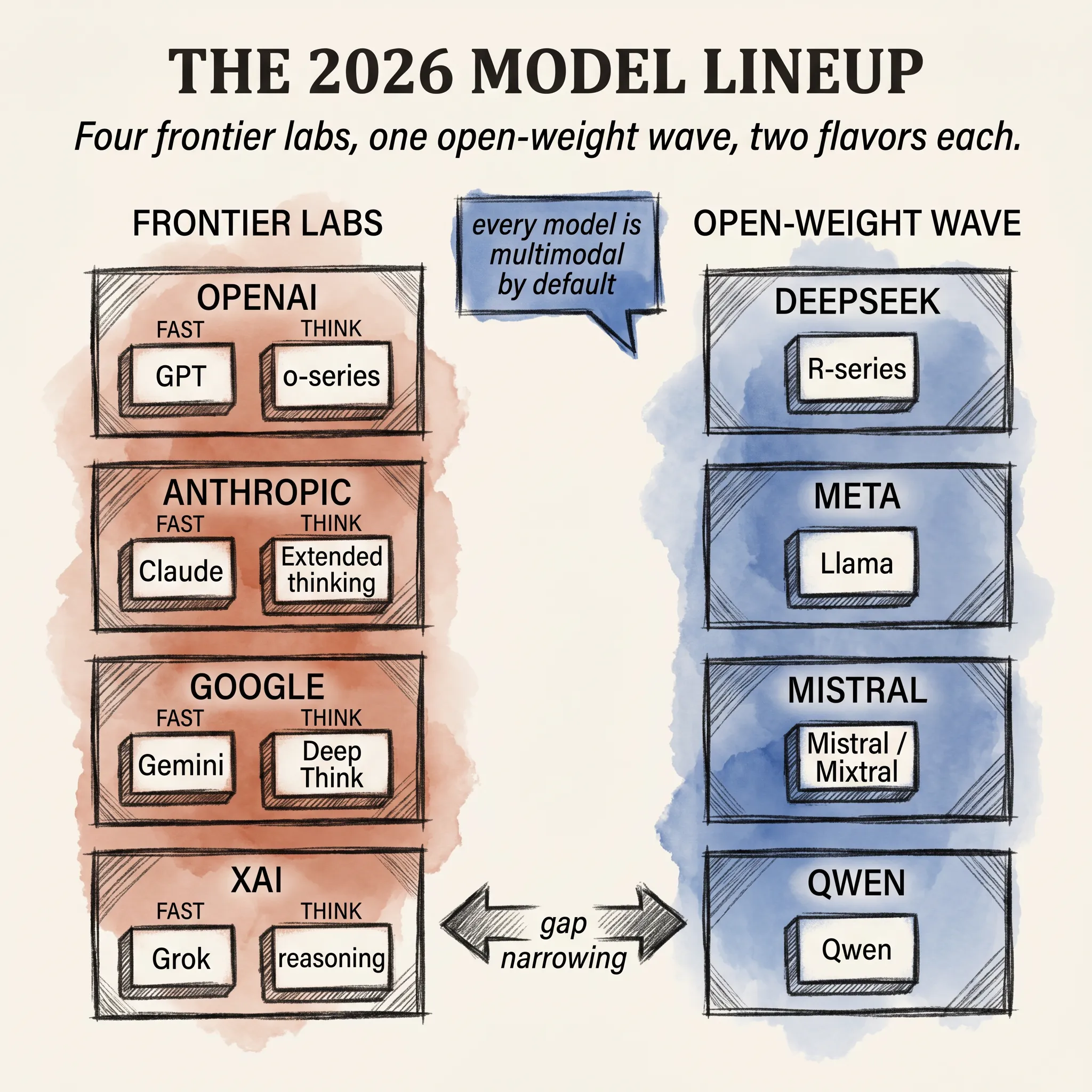
The previous two articles covered the design choices that defined modern models: reasoning changed how long they think, and multimodality changed what they can read. Together those choices reshaped the lineup. Every serious lab ships at least two flavors now, most of them are multimodal by default, and the open-weight world is closer to the frontier than at any time before.
THE FOUR FRONTIER LABS.
Four organizations sit at the top of the closed-model field in 2026. Their products differ in details but rhyme in structure.
OpenAI ships the GPT family for everyday queries and the o-series for thinking. The current naming has GPT for the fast lane and o3 or its successor for hard problems. The two share a backbone but the o-series spends ten to a hundred times more compute per answer.
Anthropic ships Claude in two modes within a single model: a quick response by default, and an extended thinking mode that shows visible reasoning before answering. One model serves both modes; only the inference budget changes. That is a meaningful divergence from the OpenAI split.
Google ships Gemini with a similar two-tier shape. The fast tier handles routine work; Deep Think handles the harder slice. Gemini also leans heaviest on native multimodality and on long context, which still matters when the task is to summarize a 400-page PDF.
xAI ships Grok with a focus on real-time data integration and a slightly looser content policy. Their reasoning tier launched later but caught up fast on the math and code benchmarks that define the frontier conversation.
The interesting thing about this list is how similar it has become. Every frontier lab now ships a fast model plus a thinking model, every model is multimodal, every one has tool use.
The arms race shifted from architecture to data and training. So where does that leave anyone hoping for a clear winner? When the products converge on the same shape, the interesting differences move to brand, price, and which company you trust with your data.
THE OPEN-WEIGHT WAVE.
The bigger story of 2025 and 2026 is what happened in the open-weight world. For a long time the gap between the best closed model and the best open one was about a year. Today it is closer to three months.
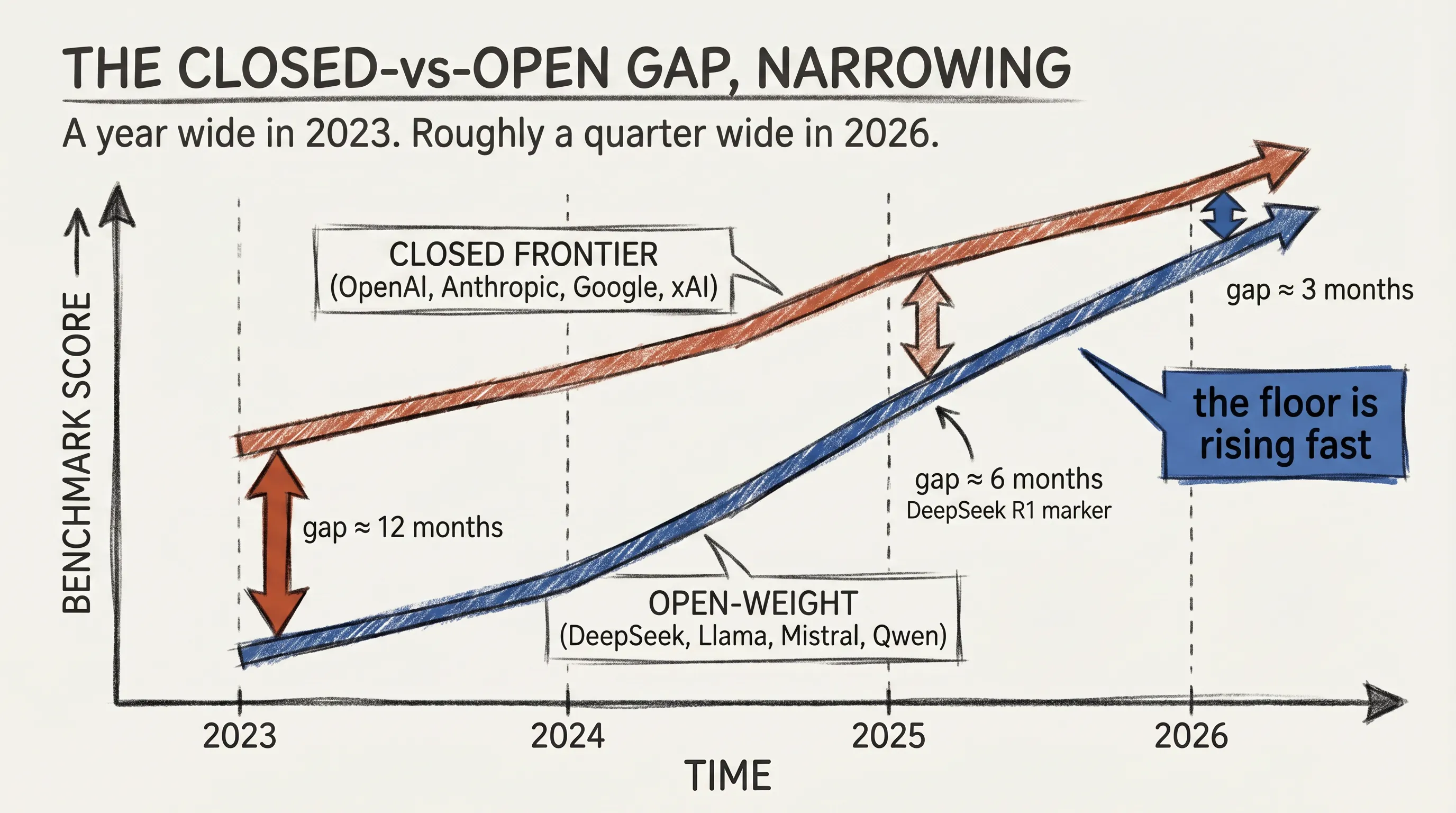
DeepSeek shipped R1 in early 2025, demonstrating that the RLVR recipe behind reasoning models worked at open-weight scale. Their next releases pushed further. The takeaway was not that open-weight had matched closed; it was that the gap was no longer a moat.
Meta keeps shipping Llama in successive generations, each one available in 8B, 70B, and 400B-class sizes. Mistral keeps shipping competitive European-trained models with permissive licenses. Qwen out of Alibaba has emerged as a real contender at the frontier of multilingual and code work.
The practical effect is that anyone willing to run their own inference, or rent it from a non-frontier provider, has a good model for almost every task. Privacy-sensitive workloads that could not legally use a closed API now have a credible local option. Cost-sensitive work that could not afford GPT-class pricing has the same.
This is not a story about open winning. The frontier still has the best models. It is a story about the floor rising fast, the way budget cars caught up to luxury cars on basic features in the 1990s.
TWO FLAVORS, ONE PRODUCT.
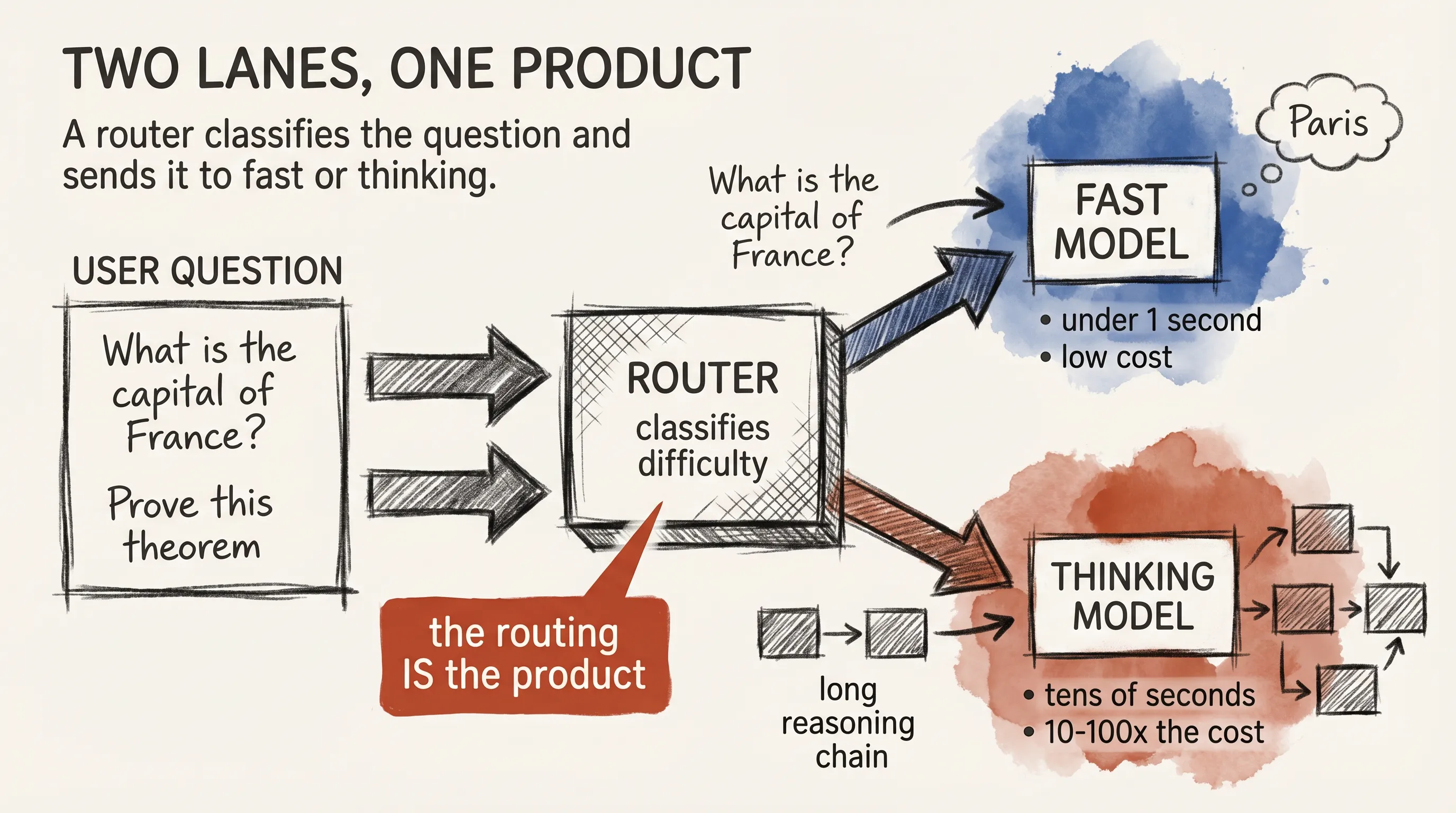
Almost every lab now ships its model in two flavors: a fast lane and a thinking lane. The labels differ. The shape is the same.
The fast lane handles the bulk of traffic: chat, summaries, casual code, simple lookups. It answers in under a second and costs little. The thinking lane takes harder problems and spends more compute, more time, and more money on each one. It is the right tool for math, multi-step coding, planning, and ambiguous specs.
A 2026 product often makes the choice automatically. The user types a question; the system routes it to the fast tier or kicks it to the thinking tier based on detected difficulty. Think of it like a hospital triage desk: the urgent case gets the specialist, the rest go to the general queue.
When the routing works, it feels like one smart assistant. When it fails, the user gets a five-second wait on a question that should have been instant, or a one-second answer to a question that needed five minutes.
The point for the reader is that there is no longer a single model behind any major product. There is a small fleet, and the routing is part of what you are paying for.
HOW TO ACTUALLY CHOOSE.
Picking a model in 2026 comes down to four levers: capability, latency, cost, and privacy. Most decisions resolve by ranking those four for the task at hand.
If capability is the only thing that matters and the task is hard, use a thinking model from a frontier lab. There is no substitute for the top tier on the hardest problems. The cost and latency are real, and worth it for the right work.
If latency is the bottleneck, like a chat interface or a tool that runs many small calls, use a fast-tier frontier model or a strong open-weight model in the 70B class. Either will answer quickly. The frontier model will be slightly more reliable; the open one will be much cheaper at scale.
If cost is the bottleneck, run an open-weight model on rented or owned hardware. The 70B-class models in 2026 cover most non-frontier workloads. The break-even against a closed API is usually around a few million tokens per day.
If privacy is non-negotiable, run an open-weight model locally. This is a real option in 2026 in a way it was not in 2023. The hardware floor is a single high-end GPU for a 70B-class model. The capability floor is good enough for most internal tools.
A useful question before any model choice: what specifically is hard about this task? If the answer is the reasoning, lean toward a thinking model. If the answer is the data is private, lean toward open-weight.
If the answer is I do not know, start with a frontier fast tier and only escalate when you hit a problem. Treat the model like a kitchen knife: a good general-purpose one cuts most things, and you only swap to the specialist blade when the work calls for it.
WHAT IT FEELS LIKE NOW.
The interesting thing about 2026 is that the differences between the top models are small enough that workflow matters more than choice of provider. A reader who never switched from one frontier model to another is probably leaving small wins on the table; a reader who switches constantly is probably wasting time on the comparison.
The right level of attention is occasional, not constant. Every six months or so, glance at the lineup. If something obviously moved, switch.
This article closes Act II of the series. The next act turns to the unglamorous side: how these models fail, how we measure them, and what the benchmarks actually mean. Hallucinations, jailbreaks, and the games labs play with their own scorecards.
T.
References
-
Stanford AI Index Report 2025 - The annual snapshot of the field. Tracks frontier vs open-weight performance, training compute, and the rate at which the gap is closing.
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-AI, 2025) - The release that made the open-weight reasoning story real. Often cited as the moment the closed-versus-open gap stopped being a year wide.
-
Anthropic’s Responsible Scaling Policy - One of the clearest published views on how a frontier lab thinks about capability tiers and deployment thresholds. Useful as background when reasoning about which lab to use.
-
Hugging Face Open LLM Leaderboard - The community-maintained ranking of open-weight models. The single best public view of where the open frontier sits at any moment.