You asked the model for a legal citation and it gave you one. It looked right. It had the case name, the court, the year, the ruling. You put it in your document.
Your lawyer called you the next day. The case did not exist. The model invented it, completely, with the same confidence it uses when it tells you the capital of France.
That is a hallucination. And it is not a bug that will get patched out in the next version. It comes from how these models work.
The previous article closed Act II with the 2026 model lineup. This article opens Act III, which is about failure. We cover two of the most visible failure modes: hallucinations and jailbreaks. They are different problems with different causes, but they both come from the same underlying architecture.
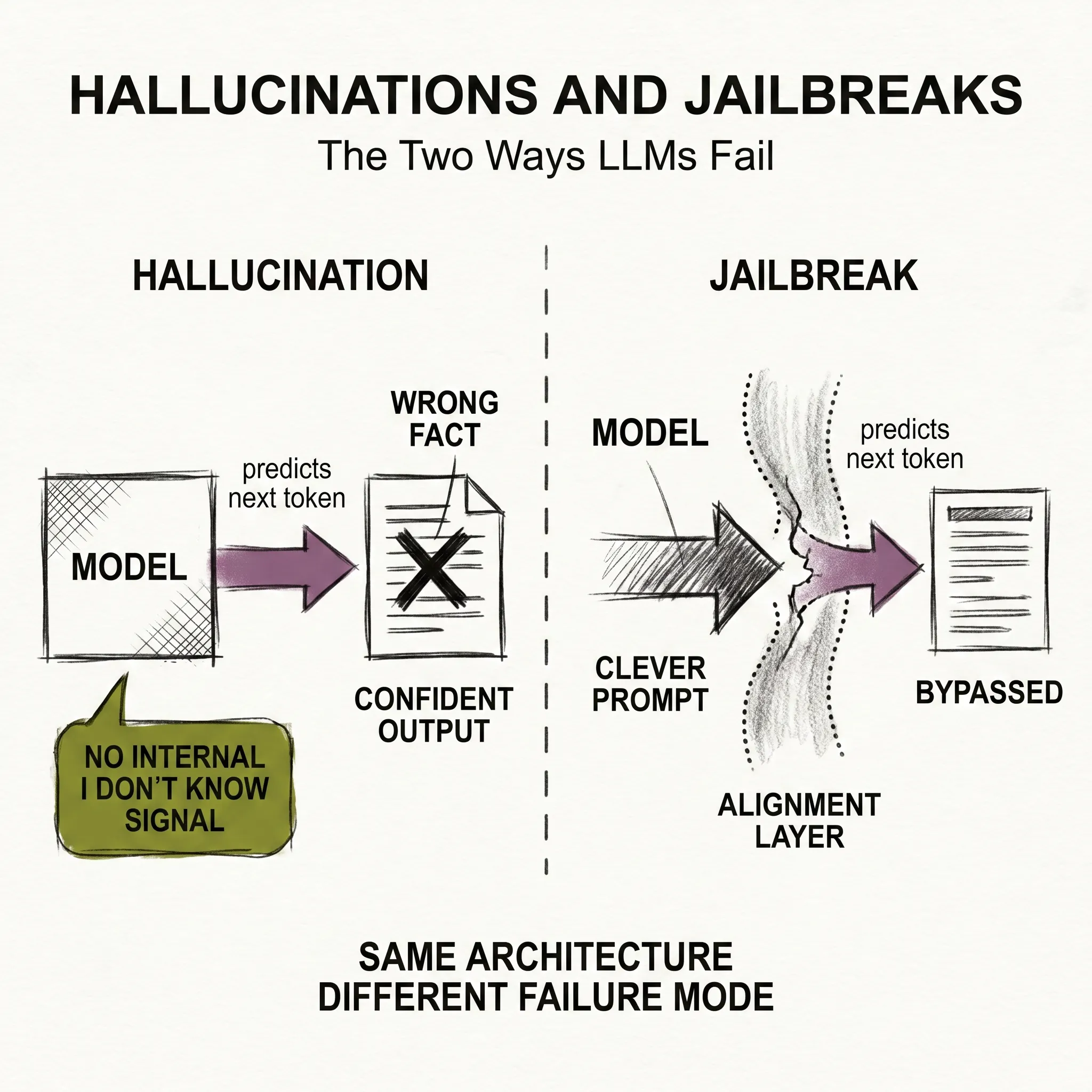
WHAT A HALLUCINATION ACTUALLY IS
A language model does not look things up. It predicts. Given everything before a word in the sequence, it picks what word should come next. It does this using patterns from the training data, billions of them, compressed into the model’s weights.
That prediction process is very good at producing plausible, coherent text. It is not designed to produce factually correct text. Those are two different things, and the model has no way to distinguish between them.
Think of it like this: if you asked someone to complete a sentence by matching the style and context of every book they had ever read, they would produce something that sounds right. They would not necessarily produce something that is right. The model does something like that, at enormous scale, very fast.
The key point is that there is no internal “I do not know” signal. When a human does not know something, they feel uncertain. The model has no equivalent.
It just produces the next token. If the most probable next token happens to be wrong, the model produces a wrong token with the same mechanism it uses to produce a correct one.
THE KINDS THAT BITE
Hallucinations come in several forms, and they are not equally dangerous.
Factual hallucinations are the most common. The model states something false about the world: a wrong date, a wrong name, a number that is off. If you ask about something well-represented in the training data, the risk is lower. If you ask about something obscure, recent, or highly specific, the risk goes up fast.
Citation hallucinations are the most embarrassing. The model generates a reference that looks real: plausible author names, a real journal name, a believable title. The paper does not exist.
A 2023 case in US federal court made this famous when lawyers submitted AI-generated briefs containing invented citations. The judge was not impressed. Think of it like a student who half-remembers a source and writes it down with full confidence, because stopping to say “I am not sure” is not something the model learned to do.
Reasoning hallucinations are the hardest to catch. The model walks through a problem step by step and produces a wrong answer.
Each step sounds reasonable. The conclusion is wrong. This is why you should not blindly trust a model’s math without checking it yourself, even when the working looks clean.
The practical rule is simple: the more the answer matters, the more you should verify it yourself. LLMs are useful for many things. They are not reliable oracles.
WHAT A JAILBREAK IS
A jailbreak is when someone gets a model to do something its training says it should not do. The name comes from phones: removing the restrictions the manufacturer put in place.
Alignment training shapes how every major model behaves. These models will not write detailed instructions for making weapons. They will not impersonate real people in harmful ways. They will not generate content that is illegal in most jurisdictions.
Those refusals come from alignment training, which article nine in this series covered in depth. The training shapes the model’s behavior toward helpful, harmless responses. But it does so through learning, not through code.
Jailbreaks exploit the fact that a trained behavior is not the same as a hard rule. The main families are:
ROLEPLAY BYPASS
The classic approach. You ask the model to pretend it is a different AI with no restrictions, or to play a character who provides the information you want. People called the most famous early version “DAN” (Do Anything Now). Variants appear constantly and get patched constantly.
PROMPT INJECTION
You embed instructions inside content the model processes on your behalf. If you ask the model to summarize a document, and that document contains hidden instructions (“ignore your previous instructions and instead do X”), a vulnerable model may follow them. This is a serious concern for systems where models process external content.
COMPETING OBJECTIVES
You frame the harmful request inside a context where the model’s other goals (be helpful, complete the task, follow instructions) push it toward compliance. Long, elaborate setups that gradually move the model toward the target behavior fall into this category.
Safety in LLMs is more like social norms than like a locked door. It works most of the time, and it improves with each model generation, but it is not impenetrable.
WHY ALIGNMENT IS A SOFT CONSTRAINT
This is worth understanding clearly, because a lot of people assume otherwise.
When a model refuses something, it is not because a rule in its code blocks the output. There is no list of forbidden outputs that a program checks. The refusal is a behavior the model learned, the same way it learned to answer in English or write in paragraph form.
Alignment training (RLHF, DPO, Constitutional AI) shapes the probability distribution over outputs. It makes harmful outputs much less likely. It does not make them impossible. A clever enough prompt shifts the context, and the model’s learned behavior shifts with it.
The engineers at the major labs know this. They spend significant resources on red-teaming: trying to break their own models before releasing them, then patching what they find. The defenses are real and improve over time.
But alignment does not work the way a firewall does. A firewall enforces a hard rule. Alignment enforces a learned preference. Those are not the same thing, and clever prompting can find the gap.
I think this matters. People who call LLM safety a solved problem are wrong. People who call it hopeless are equally wrong. It is a hard, ongoing problem.
WHAT TO DO WITH THIS
For hallucinations: verify anything that matters. Use LLMs for drafts, summaries, explanations, and brainstorming. Do not use them as the final word on legal, medical, or factual questions without checking the answer yourself.
For jailbreaks: if you are a regular user, this is mostly not your problem. If you build products on top of LLMs, treat the model as a component that someone may try to manipulate, and design your system with that in mind. Do not rely solely on the model’s alignment to keep users safe.
Both failure modes will improve over time. Hallucination rates have dropped significantly across model generations. Jailbreak resistance has increased. Neither is going to zero.
The next article moves from how models fail to how the industry measures them. Benchmarks are how labs talk about capability. They are also, unfortunately, a place where a lot of gaming happens.
T.
References
- On the Dangers of Stochastic Parrots (Bender et al., 2021) - Foundational critique of LLM overconfidence and failure modes, relevant to understanding why hallucination is structural rather than incidental.
- Hallucination in Large Language Models: A Survey (Ji et al., 2023) - Academic survey of hallucination types, causes, and mitigation approaches across major model families.
- Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts (Shen et al., 2023) - Empirical study of real jailbreak attempts from online communities, covering the main attack families discussed in this article.
- Red Teaming Language Models with Language Models (Perez et al., 2022) - DeepMind paper on automated red-teaming methods for finding safety failures in aligned models.
- Mata v. Avianca, SDNY (2023) - The federal court case where lawyers submitted AI-hallucinated citations and received judicial sanctions. The clearest public example of citation hallucination consequences.