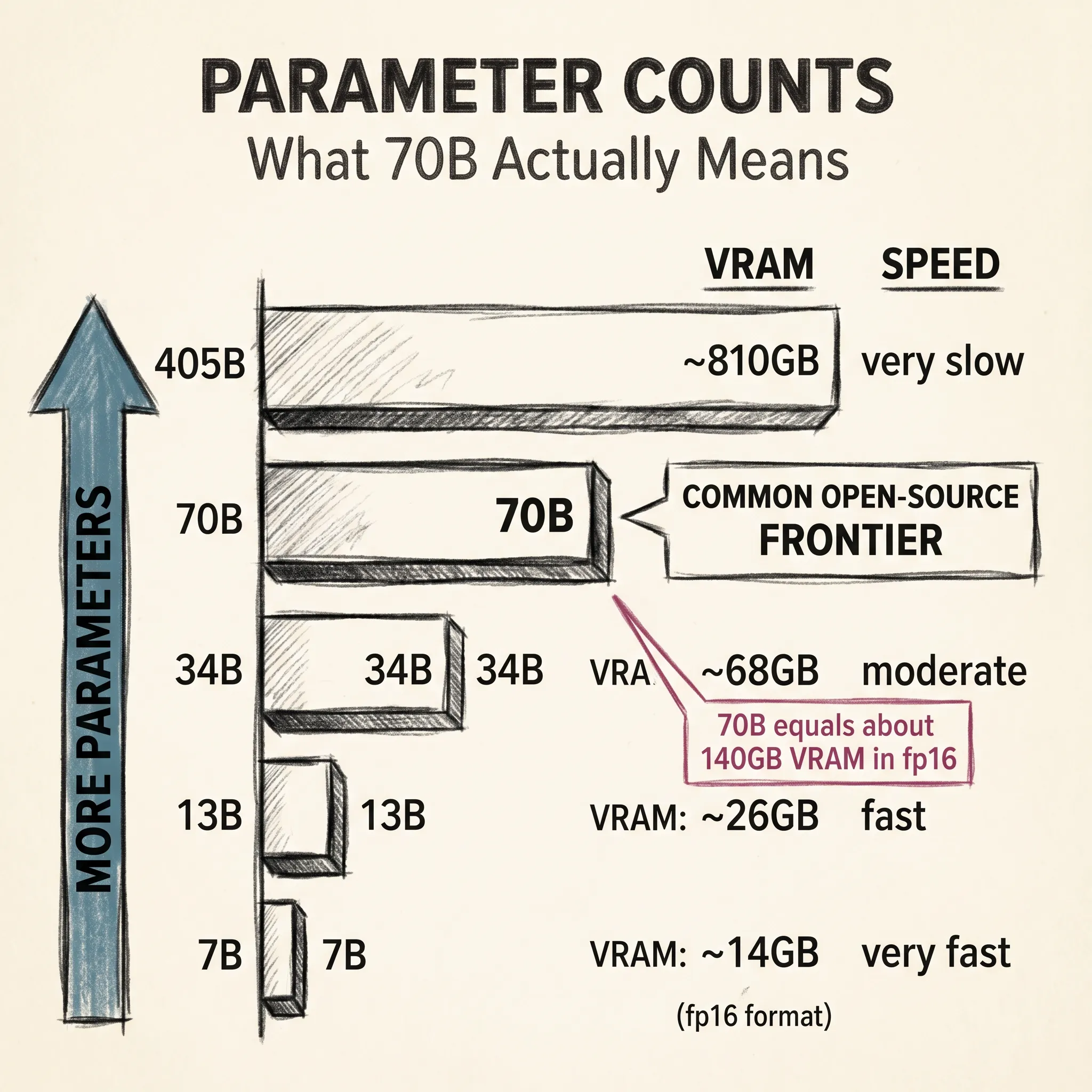
The last article ended on a small confession. Parameter counts used to describe one clear thing. A 70B model had 70 billion active weights, and every one of them ran for every token.
That stopped being true at the frontier. Most major 2026 models use a different design, and the design has a name: Mixture of Experts, usually shortened to MoE. This article explains what it is, why it won, and why a 671B MoE model can cost less to run than a dense 70B.
THE PROBLEM WITH DENSE MODELS.
A traditional language model is what researchers call dense. Every parameter runs for every token. A 70B dense model multiplies 70 billion numbers together at every forward pass, for every word it generates. This is simple and it works, but it scales badly.
If you want a smarter model, the dense approach has only one move: make it bigger. And bigger means more compute per token, more memory, more electricity, more heat. At a certain point the cost of running the model grows faster than the capability gain.
Chinchilla, from the previous article, told labs how to train dense models efficiently. It did not solve the problem that running a dense model at scale is expensive.
The question researchers asked was simple. A large model is like a large library. For any specific sentence you are reading, do you really need to consult every book on every shelf? Probably not.
A paragraph about chemistry does not need the part of the model that handles French grammar. A line of Python does not need the weights specialized in poetry. So what if we could route each token only to the shelves that matter?
WHAT MIXTURE OF EXPERTS ACTUALLY DOES.
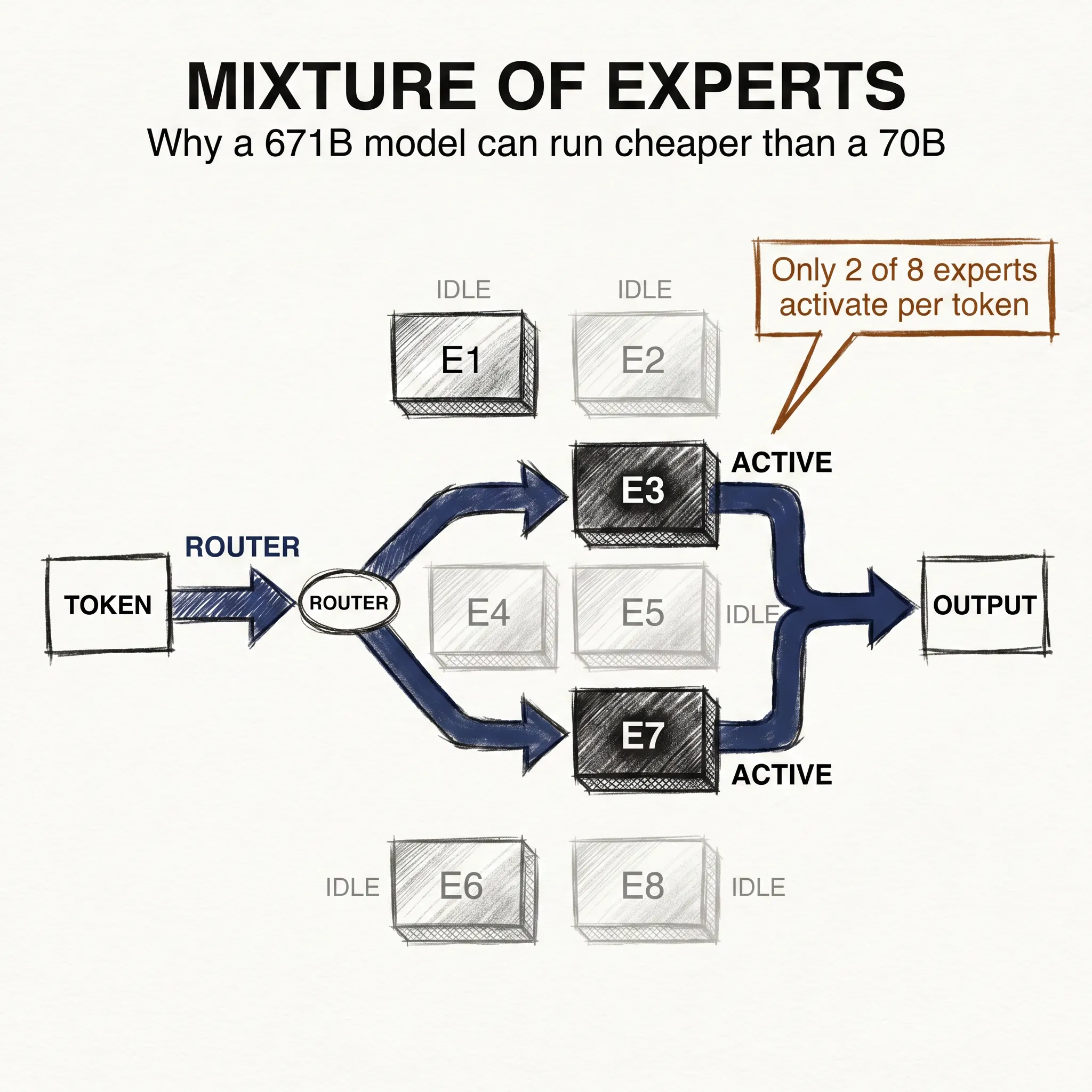
An MoE model replaces some of its dense layers with a set of parallel sub-networks called experts. A typical setup has eight, sixteen, or even hundreds of experts at each MoE layer. Every expert is structurally identical, just a feed-forward block, but their weights are different because they learn to specialize during training.
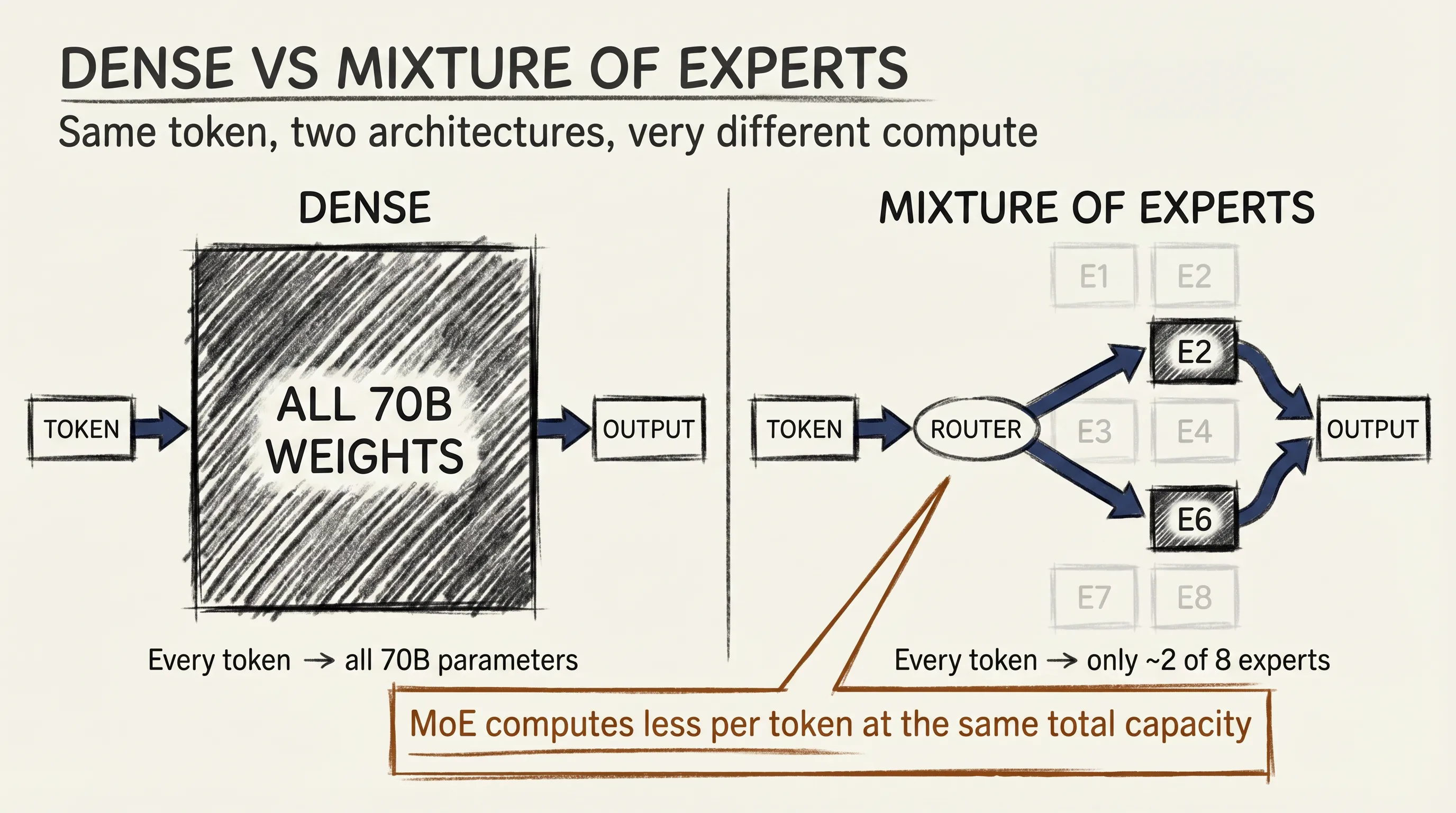
For each token that enters the layer, a tiny neural network called the router decides which experts should handle it. Most real systems use top-2 routing: the router picks the two most relevant experts, and only those two touch the token. The other experts do nothing for this token. Their two outputs then combine, weighted by how confident the router was in each pick, and the layer passes the result forward.
This is the central idea in one sentence. You get a model with a huge total capacity, but at inference time only a small fraction of that capacity activates for any given token.
WHAT THE ROUTER ACTUALLY LEARNS.
Nobody hand-writes the router. It trains together with the rest of the model. During training, the router learns which kinds of tokens each expert handles best, and each expert, in turn, gets better at the tokens the router keeps sending it. You do not program the specialization; it emerges.
What exactly do experts specialize in? Less than you might hope. Interpretability research has shown the specializations are usually not clean topic categories like chemistry or French. They are lower-level patterns that do not map to human concepts: syntactic structures, token groupings, statistical regularities in the text.
Think of it less like a university faculty divided by department, more like a busy kitchen where each cook has quietly learned to grab one specific kind of pan. The partitioning is useful to the model without being legible to us.
Training an MoE model is also harder than training a dense one. The router can collapse, sending everything to one favorite expert and leaving the others untrained. To prevent this, training uses load balancing losses that actively punish the router for being too concentrated. Getting this balance right is one of the hardest parts of MoE engineering, and it is where a lot of the proprietary knowledge at frontier labs sits.
ACTIVE VS TOTAL PARAMETERS.
This is where the 671B number becomes confusing and interesting at the same time.
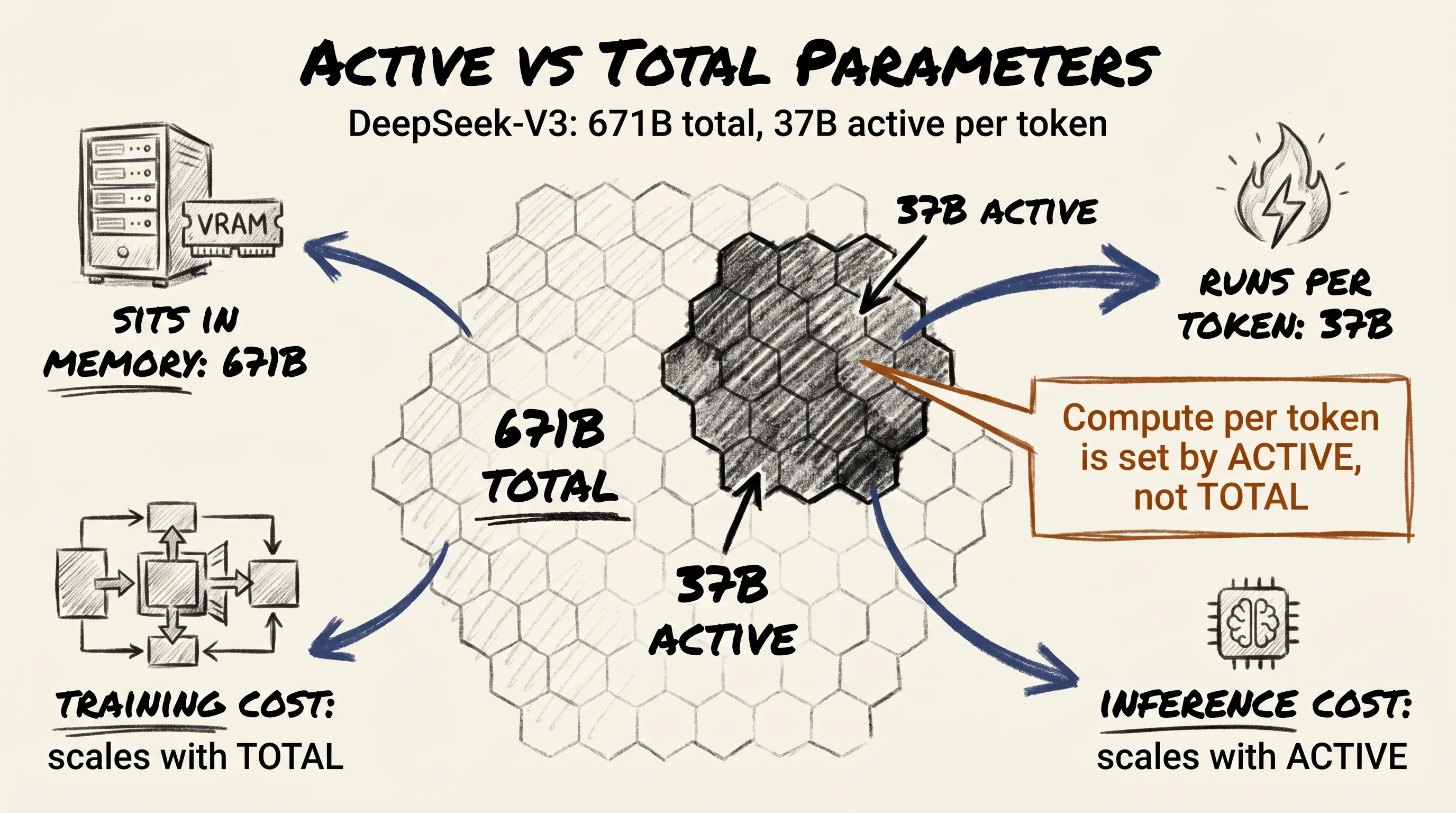
Take DeepSeek-V3, released at the end of 2024. The full model has about 671 billion parameters. That number describes the total weights that must sit in memory while the model runs.
But for any given token, only around 37 billion of those weights are actually used. The other 634 billion are in the room but do nothing for that token. Imagine a dinner party where ninety percent of the guests are there to look at, not to talk to.
Compare this to a dense Llama-3 70B. Every one of those 70 billion parameters runs for every token. So in terms of actual computation per token, the 671B MoE does less work than the 70B dense model. That is why inference on DeepSeek-V3 can be faster and cheaper than on Llama-3 70B, even though the headline number is almost ten times larger.
The headline number has not become meaningless, but it has split into two. The total parameter count tells you about training cost, storage, and how much hardware memory you need to load the model. The active parameter count tells you how much computation runs per token, which determines inference speed and cost.
When a lab announces a model, it usually gives both, in a format like 671B total over 37B active. Anyone who reads one number without the other is reading half the story.
THE HARDWARE TRADE-OFF.
MoE is cheaper to compute, but not cheaper in every way. To run a 671B MoE model you still need to hold all 671 billion parameters somewhere accessible. The router might pick any expert at any moment, so every expert must be ready.
Think of it like running a hotel. You can only check in two guests at a time, but you still have to heat all the rooms, because you never know which ones will be needed.
In practice this raises the memory floor for serving the frontier. A dense 70B runs on two consumer GPUs. DeepSeek-V3 at full precision needs more than a terabyte of memory, which puts it firmly in the multi-GPU server tier. Quantization helps, but the asymmetry stays: MoE is cheap per token, expensive per instance.
This is why MoE at the frontier is mostly a story about serving infrastructure at large providers. When you use Claude or GPT or DeepSeek through an API, the provider absorbs this hardware cost and you pay per token. On a per-token basis you get a model that is much larger than what you could run locally. On an upfront basis, that model is not something you download.
WHY MOE WON.
By 2026, nearly every frontier model is either an MoE or a dense model trained with MoE influence. Mixtral 8x7B from Mistral was the first open-weight MoE to attract serious attention in early 2024. GPT-4 was widely believed to be an MoE.
DeepSeek-V3 pushed the open-weight frontier to 671B total parameters. Claude and Gemini are not fully documented, but the economics make it very likely their frontier models follow a similar pattern.
The pattern won because it solved a specific problem. Labs wanted to keep scaling capability without scaling the cost per token at the same rate. Dense scaling did not give them that; MoE does.
It is not magic, and it is not free. You pay for it in training complexity and serving hardware. But it shifts the cost curve in the direction labs needed.
For the reader, the practical takeaway is the one from article 07, now sharper. Treat the parameter count as a rough indicator, not a specification. Ask whether the number is total or active. When the two diverge by an order of magnitude, the model you are looking at is playing a different game than the one you are used to.
The next article steps back from the engineering and asks a different question: how a base model, which just predicts the next token, becomes an assistant that follows instructions and refuses harmful ones. We call that shift alignment, and modern alignment looks nothing like what it did three years ago.
T.
References
-
DeepSeek-V3 Technical Report (DeepSeek, 2024) - Documents the 671B total / 37B active architecture, the MoE routing design, and the training approach used to build the first open-weight frontier MoE.
-
Mixtral of Experts (Jiang et al., 2024) - The Mixtral 8x7B paper from Mistral. Describes top-2 routing in an open-weight model and established the template later extended by DeepSeek and others.
-
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (Shazeer et al., 2017) - The original sparse-MoE paper that introduced the routing approach modern transformers use. Predates the transformer era in spirit but defined the core mechanism.
-
Switch Transformer: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Fedus et al., 2021) - Google’s scaling study of MoE transformers. Covered single-expert routing and the load-balancing losses that keep training from collapsing onto one expert.