The last article covered context windows: how much a model can see at once, and why extending that window costs so much compute. That was one constraint on the model’s working environment. Now we move one level up. We look at the model itself: how big it is, what that means, and whether bigger is actually better.
WHAT A PARAMETER ACTUALLY IS.
A parameter is a number. One of the learned weights inside the model’s neural network. During training, the model processes billions of examples and adjusts these numbers repeatedly to minimize prediction error. When training ends, those numbers are frozen.
The model you run is the result of that process: one weight matrix after another, stacked into layers. Seventy billion parameters means seventy billion of these individual numbers. Not seventy billion ideas, not seventy billion facts. Just seventy billion floating-point values that collectively encode what the model learned.
Think of it like RAM in a computer. More RAM does not make your code smarter, but it lets you hold more things in working memory at once. More parameters give the model more representational capacity, a larger space in which to encode patterns. How well the model uses that capacity depends entirely on the quality and quantity of training data.
WHAT 70B COSTS IN PRACTICE.
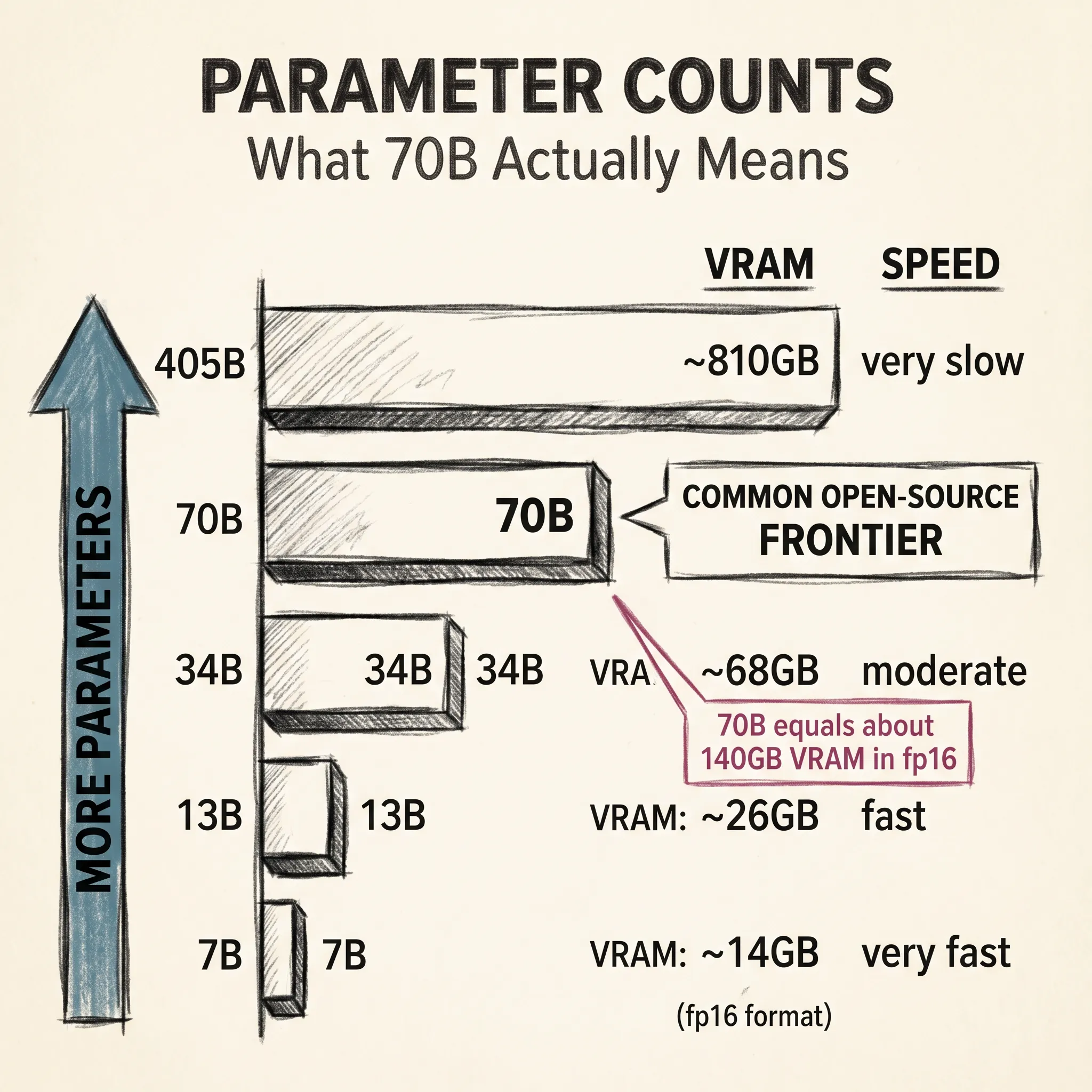
This is where the number gets concrete. To run a model, you need to load its parameters into GPU memory. In the most common inference format, fp16 (16-bit floating point), each parameter takes two bytes. Seventy billion parameters times two bytes is 140 gigabytes.
You need that much VRAM just to hold the model before processing a single token. A typical high-end consumer GPU has 24 GB. To run a 70B model in fp16, you need either a large server GPU (an A100 or H100 has 80 GB) or multiple GPUs working together.
Think of it like shipping freight. A small van carries small loads fast and cheap; a flatbed truck carries heavy loads but needs special infrastructure and costs more to run. The 7B model is the van, the 70B is the truck. Both get the job done, but the operational requirements are in a completely different category.
Speed follows the same pattern. More parameters means more computation per generated token. On a single consumer GPU, you might see 40 to 50 tokens per second with a 7B model and 5 to 10 with a 70B. For interactive use, that gap is noticeable.
This is also why model quantization matters. Converting weights to 4-bit or 8-bit format cuts memory use by half or more, at some cost to output quality. It is the main technique that lets consumer hardware run models it was not designed for.
THE SCALING LAWS.
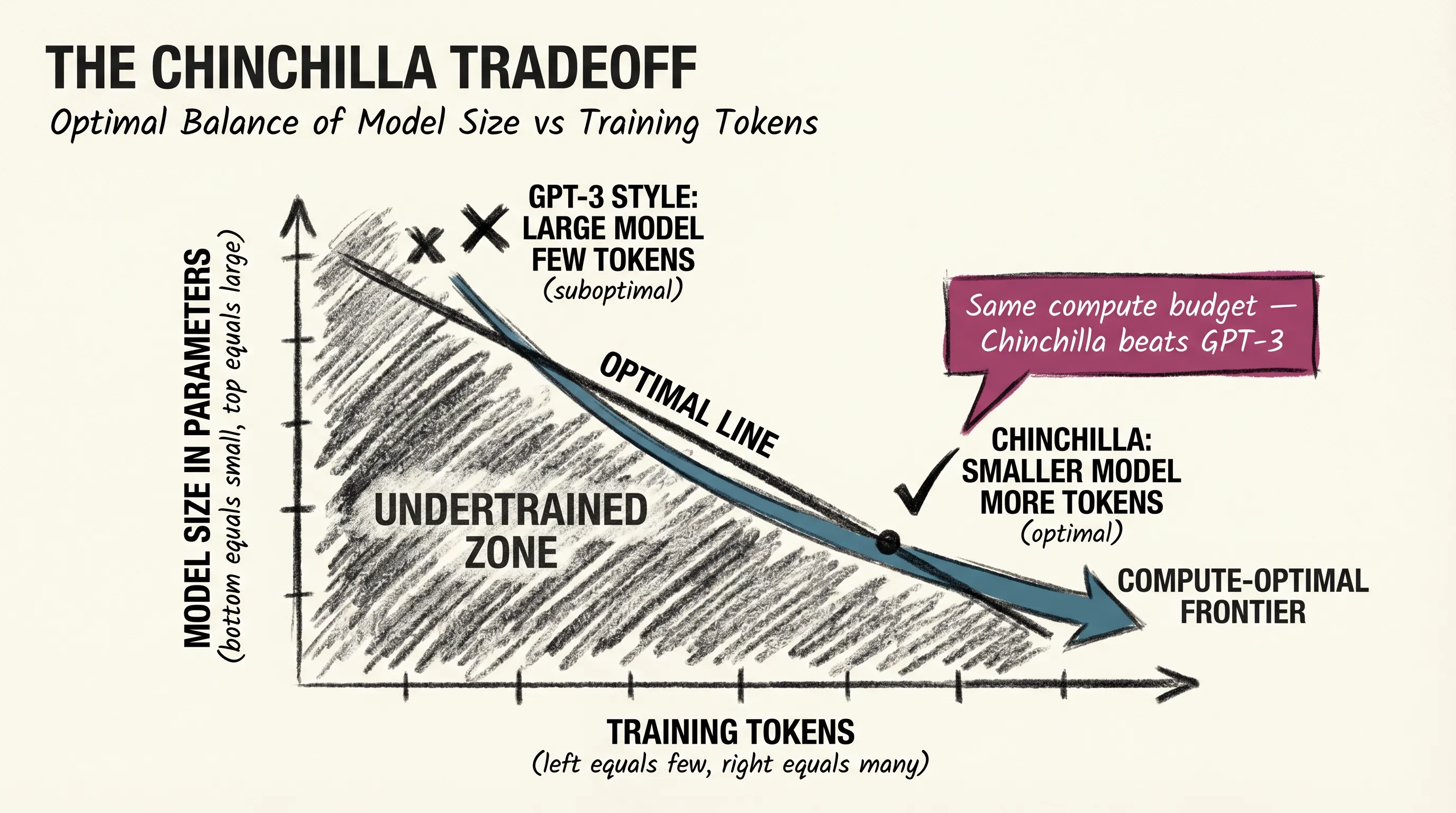
In 2022, researchers at DeepMind published a paper that changed how the field thinks about model size. Known as Chinchilla, after the model they trained as proof of concept, the paper’s core finding was this: the field had been training large models on too little data.
The insight was about the relationship between three things: model size, training data, and compute budget. If you have a fixed amount of compute, there is an optimal balance between how many parameters you train and how many tokens you train on. Larger models trained on insufficient data underperform smaller models trained on more.
It is like baking bread. If you double the pan size but keep the same amount of dough, you get a thin, flat loaf. The capacity is there; the material is not. Chinchilla showed that a model half the size of GPT-3, trained on four times as much data, could match or beat it on most benchmarks.
Before that paper, the assumption was roughly: bigger model equals better model. Teams raced to increase parameter counts while training data stayed roughly fixed. Chinchilla overturned that assumption. The framing shifted from how many parameters to how many parameters given how many training tokens.
The correction had real consequences beyond model size. Scaling one variable while ignoring the others tends to hit diminishing returns faster than you expect, and this turned out to be a lesson that applied across the field.
WHAT SCALE ACTUALLY BUYS YOU.
Quality does not scale linearly with parameters. Somewhere between 7B and 70B, models start doing things reliably that smaller models do poorly: multi-step reasoning, code that holds together across functions, language tasks that require broad world knowledge.
Researchers call these emergent capabilities: abilities that appear at certain scales and are hard to predict from results at smaller scales. The framing is contested. Some argue these are genuine phase transitions where new behaviors appear. Others say the apparent emergence is partly a measurement artifact, where binary benchmarks make gradual improvements look sudden.
The literature has not resolved it either. What is observable is that 70B models handle things that 7B models handle poorly, and the difference matters in practice even if the theoretical framing is still open.
What scale reliably buys: better instruction following, more consistent factual accuracy, stronger reasoning, and better handling of ambiguous prompts. What scale does not fix: hallucination, which persists across model sizes, and knowledge cutoffs, which depend entirely on training data.
THE 2026 CAVEAT.
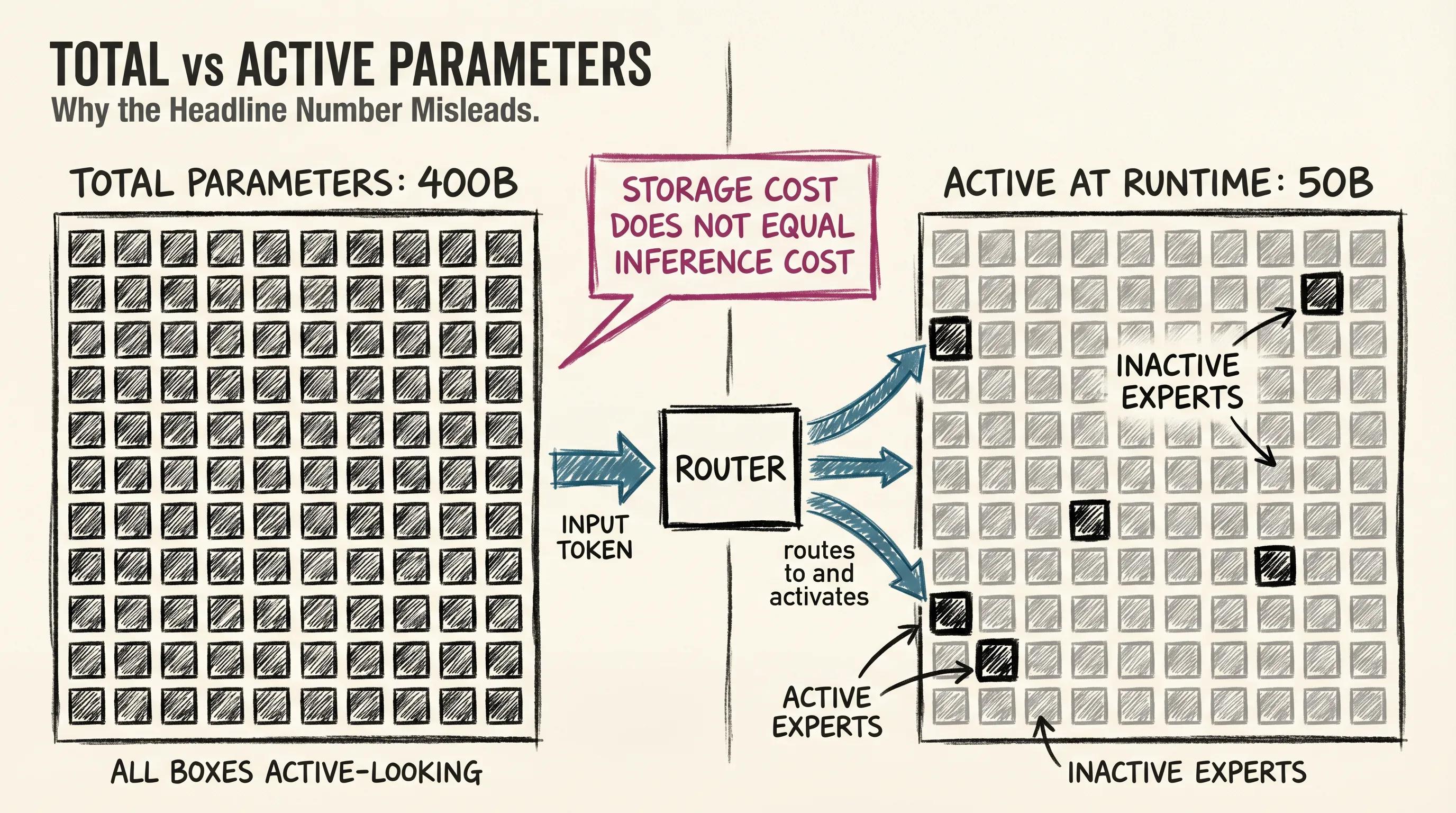
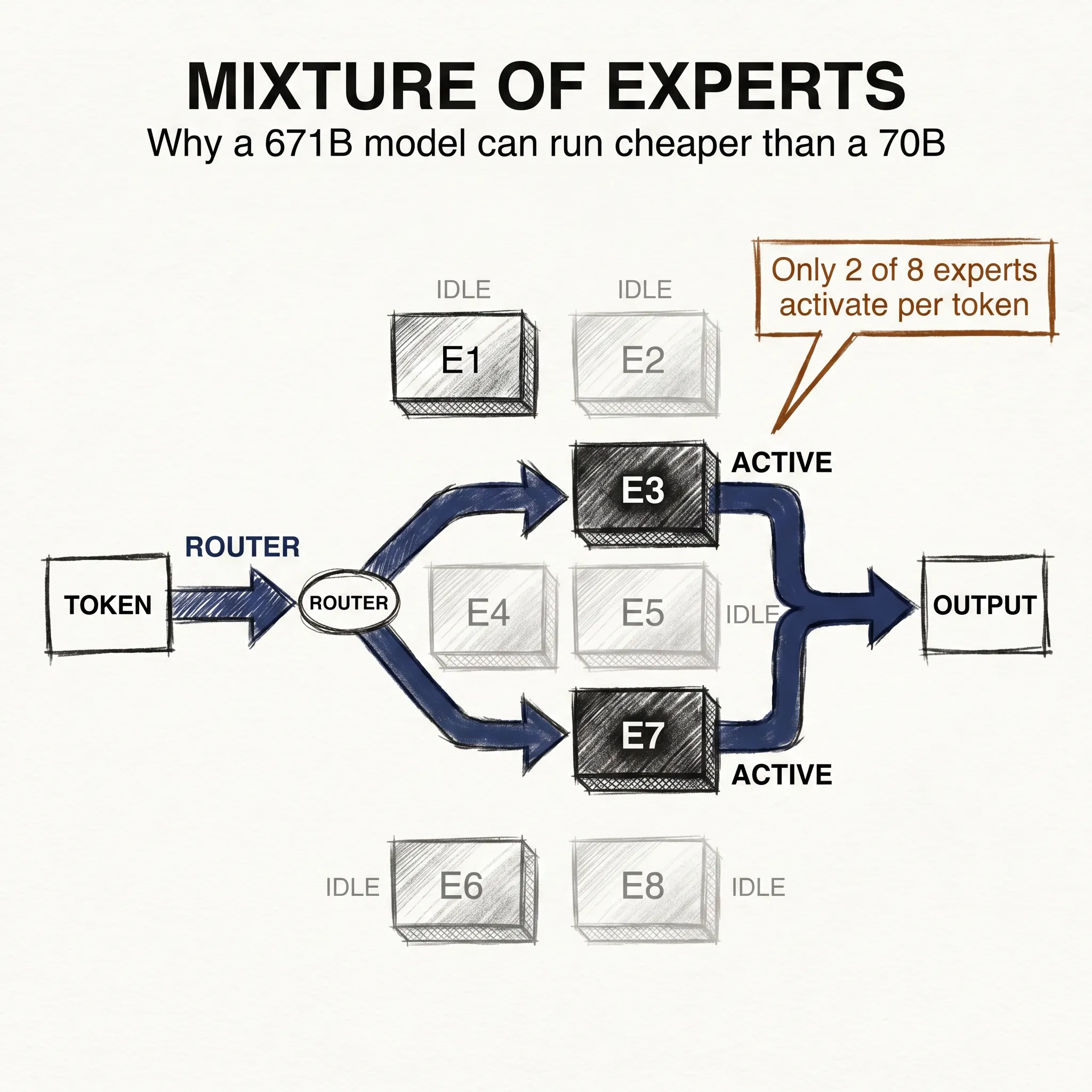
Here is the part that makes the headline number harder to read now. Most frontier models in 2026 use a Mixture of Experts architecture, which the next article covers in detail. The short version: instead of activating all parameters for every token, the model routes each token to a subset of specialized sub-networks.
A model might have 400B total parameters but only activate 50B at a time during inference. Think of it like a hospital with 400 specialists on staff. For any given patient, only a handful are consulted. The total headcount describes the institution’s breadth; it does not describe who is in the room right now.
When a lab announces a 400B parameter model, the number is not wrong. But it describes something different from a dense 400B model. The active parameter count determines inference speed and memory at runtime. The total determines storage and training cost, and for most frontier systems in 2026, those are different numbers.
The practical reading: treat parameter counts as a rough proxy for scale, not a precise technical specification. Pay more attention to benchmark results and hardware requirements than to the headline count.
The next article looks at Mixture of Experts in detail: how routing works, why it became the dominant approach at the frontier, and what it actually means for efficiency and capability.
T.
References
-
Training Compute-Optimal Large Language Models (Hoffmann et al., 2022) - The Chinchilla paper. Establishes the relationship between model size, training tokens, and compute budget, showing that pre-2022 frontier models were systematically undertrained relative to their size.
-
Scaling Laws for Neural Language Models (Kaplan et al., 2020) - The original scaling laws paper from OpenAI. Established the power-law relationships between compute, model size, and loss that the Chinchilla work later refined and corrected.
-
Emergent Abilities of Large Language Models (Wei et al., 2022) - Introduces the emergent abilities framing and shows apparent phase transitions in capability at certain model scales on specific benchmarks.
-
Are Emergent Abilities of Large Language Models a Mirage? (Schaeffer et al., 2023) - Challenges the emergence framing, arguing that apparent phase transitions are artifacts of nonlinear evaluation metrics rather than genuine discontinuities in model capability.