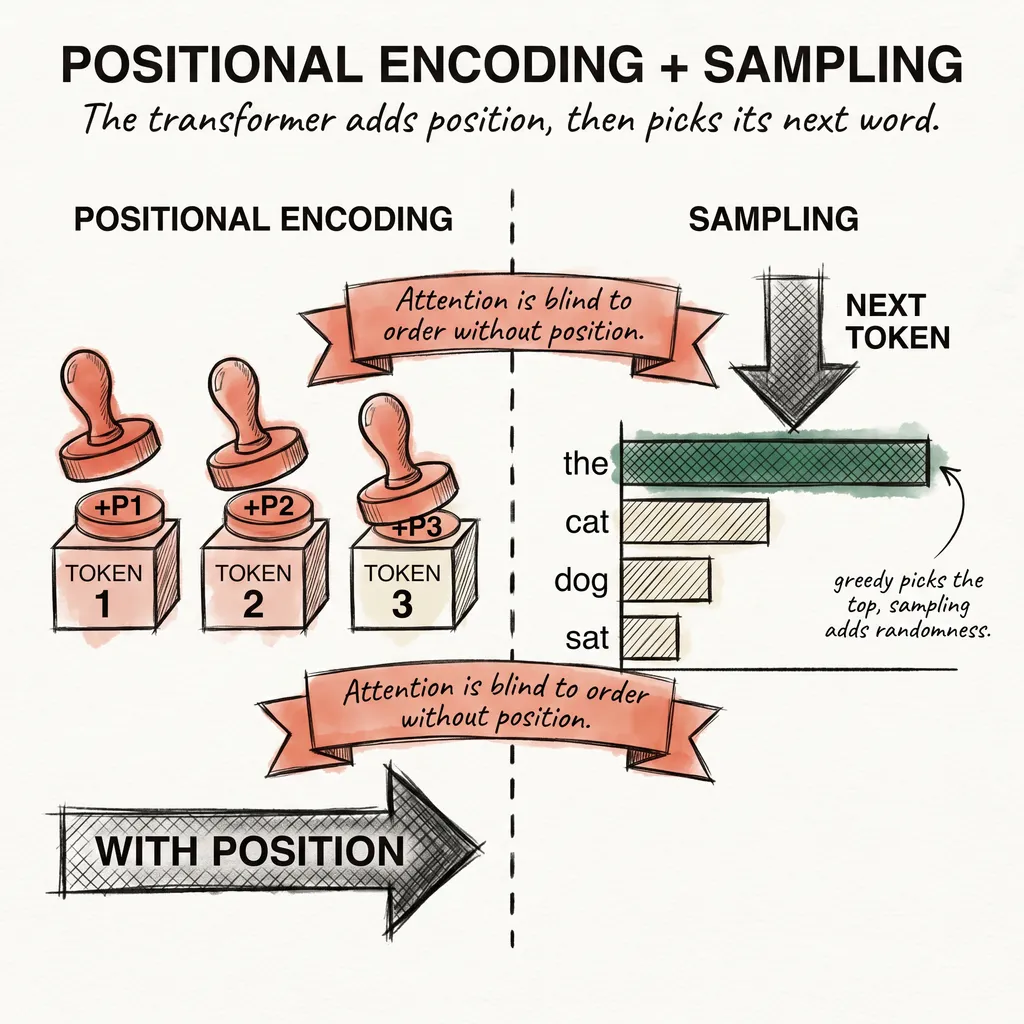
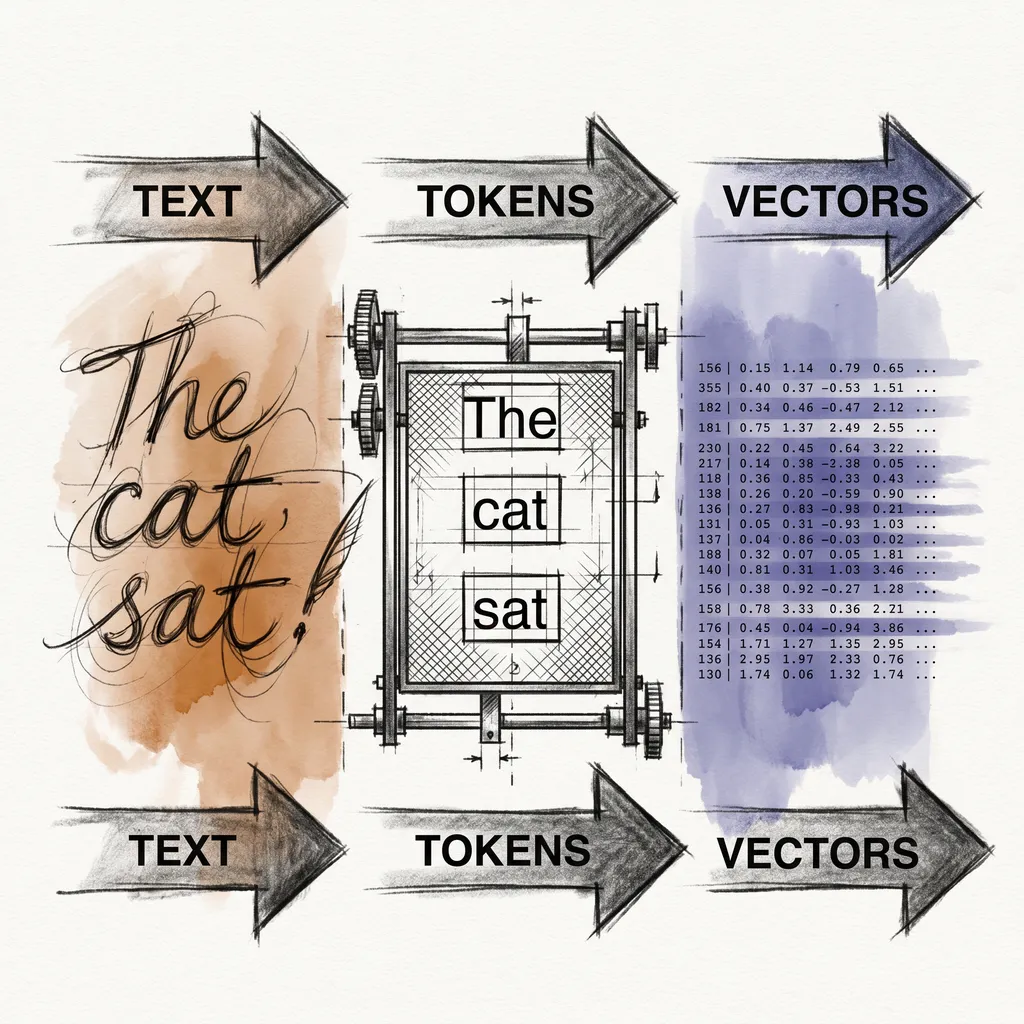
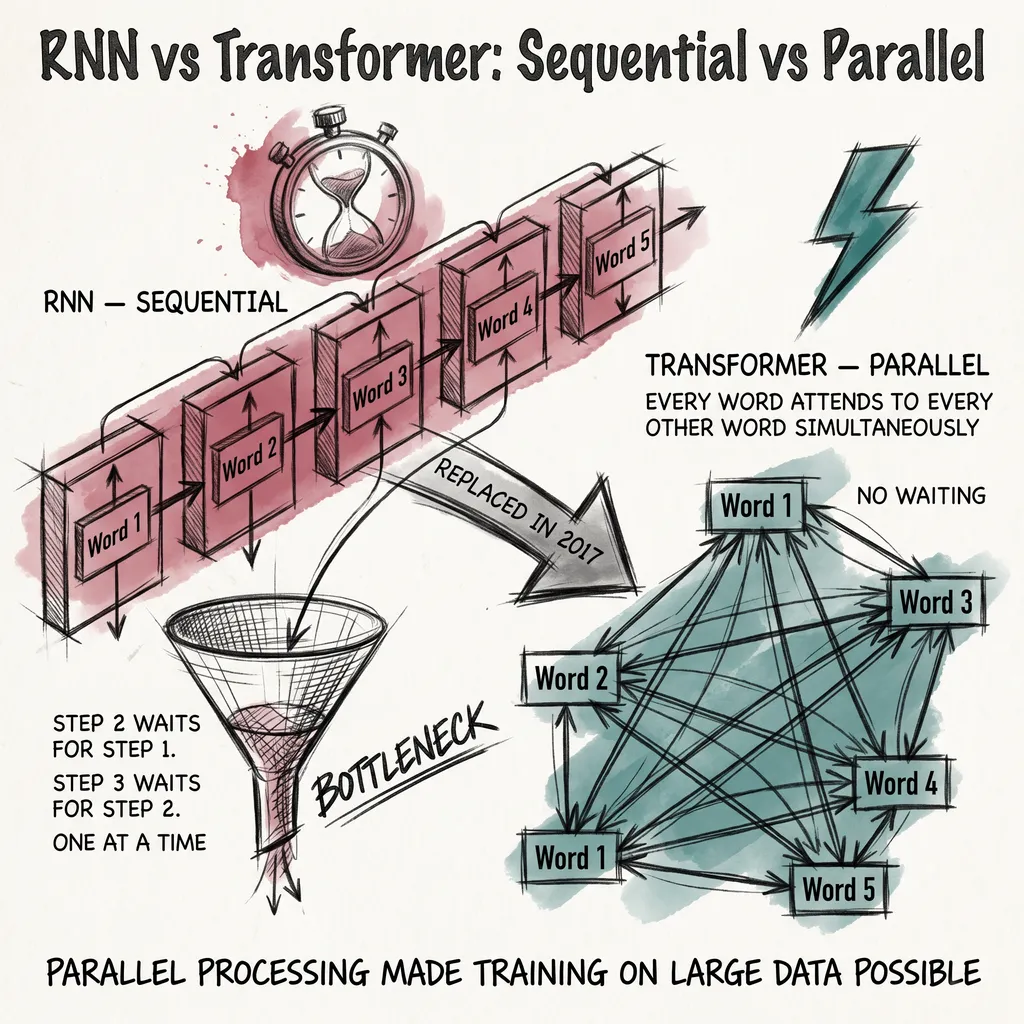
The previous act covered the full inference pipeline: tokens, embeddings, attention, positional encoding, sampling. You now know what happens between your prompt and the model’s reply, step by step.
One constraint sits on top of that pipeline and shapes what the model can do before it even starts. The context window. This act covers the design decisions that wrap around the pipeline and determine what a model can do in practice. Context windows are the first one to understand.
You have probably noticed that long conversations with AI tools sometimes go wrong in a specific way. The model starts ignoring something you said earlier. Or it seems to forget you told it to use a particular format. These failures usually trace back to one cause.
WHAT A CONTEXT WINDOW ACTUALLY IS
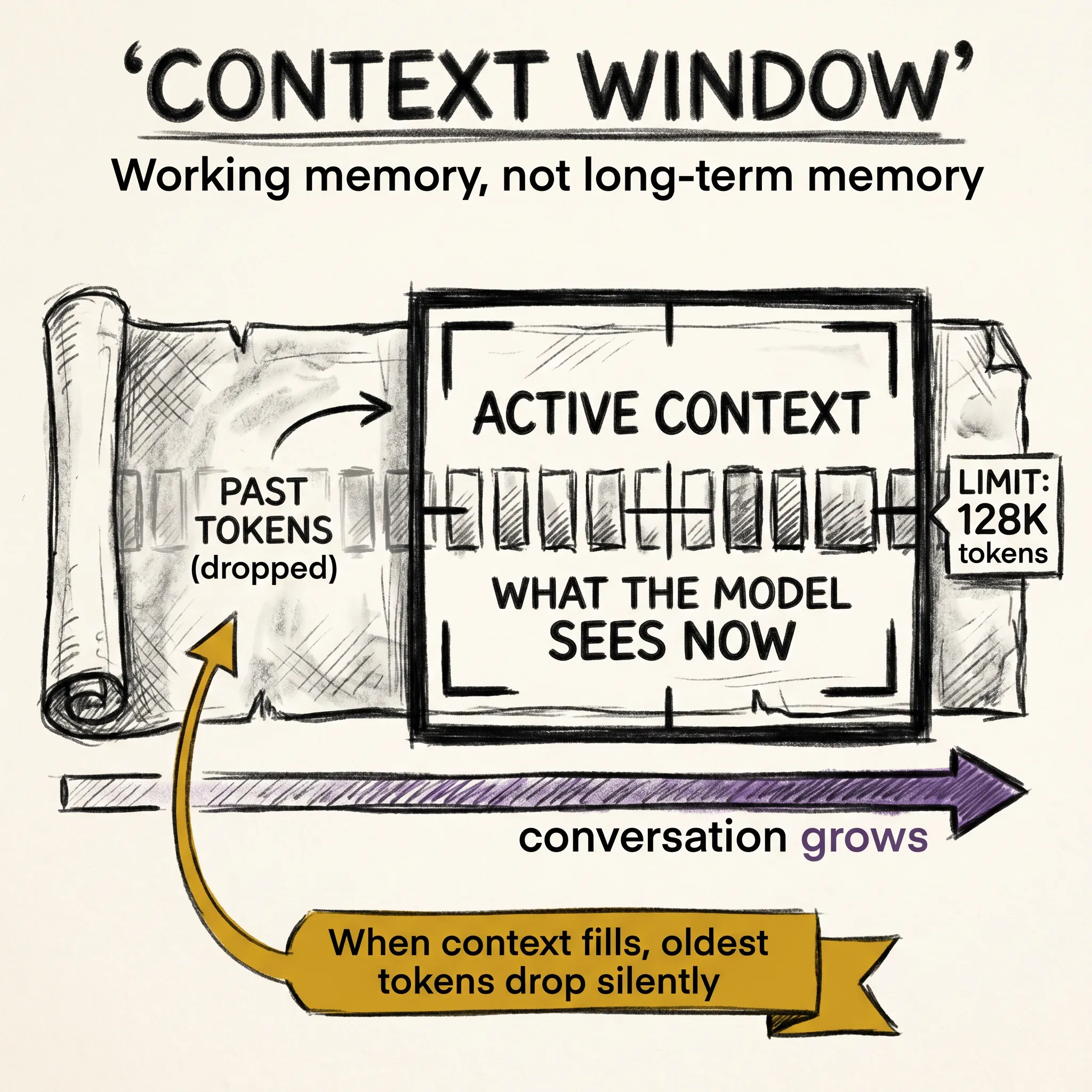
A context window is the total number of tokens the model can process at once. Every token in your prompt, every token in the model’s previous replies, every document you paste in: they all count toward the limit.
When the conversation plus context exceeds the window, something has to give. Most systems silently drop the oldest tokens to make room for new ones. The model does not know those tokens are gone. It just sees a shorter history.
This is not memory in the way humans use the word. Think of it like a whiteboard in a room with no walls. You can write as much as fits on the board, and anything that falls off the edge is simply gone. The board does not know what used to be on it.
A model has no persistent store of past conversations. It does not remember that you talked to it yesterday. Each new session starts empty.
The context window is not long-term memory. It is working memory: what the model can see right now, in this session. I think this distinction matters more than most people realize.
When people complain that AI forgets things, they often mean two different problems. One is forgetting within a session, which is a context window problem. The other is forgetting across sessions, which requires external storage, not a bigger window. The two get conflated constantly.
WHY EXTENDING THE WINDOW IS HARD
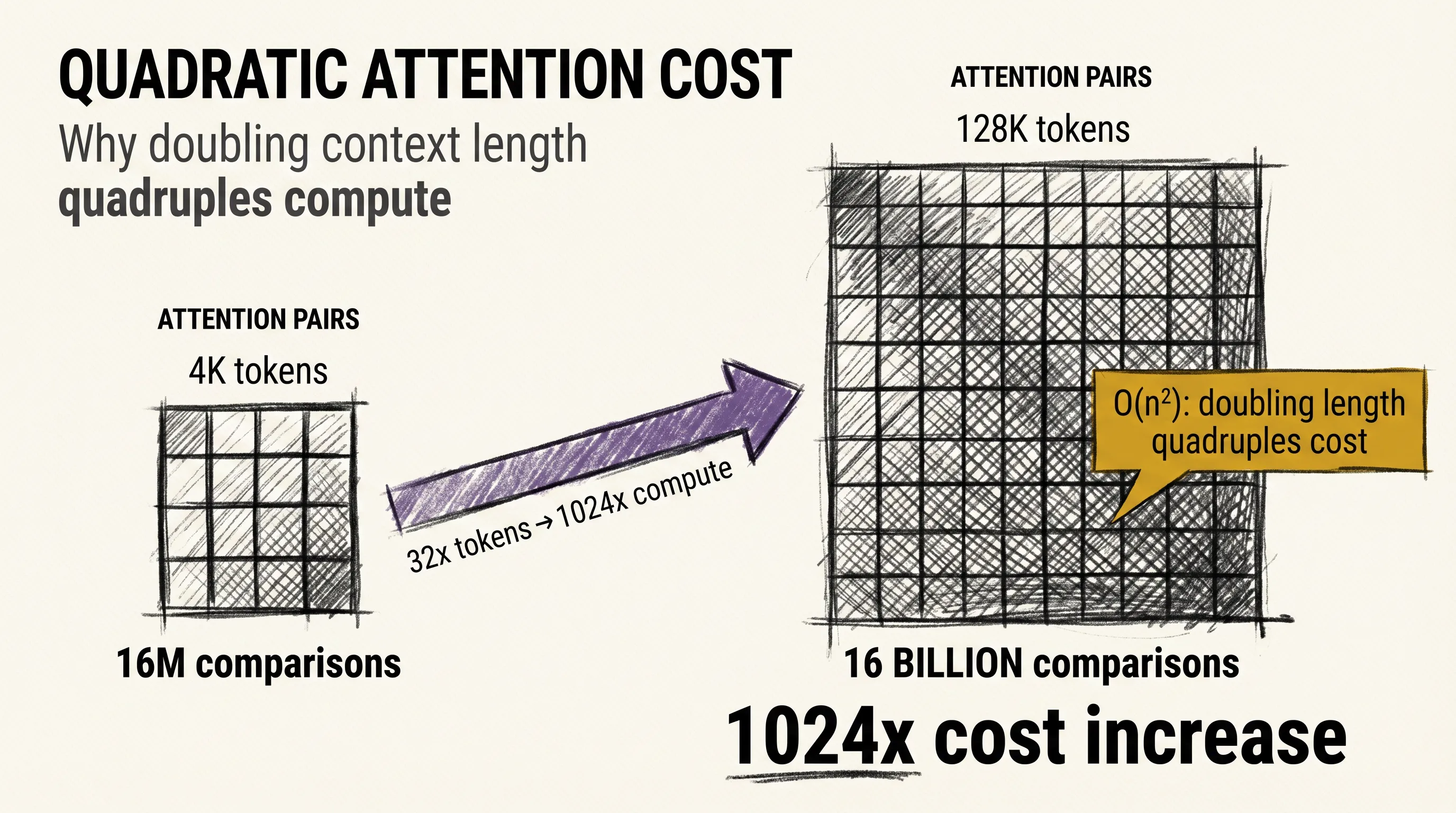
The attention mechanism from article three compares every token against every other token simultaneously. For a sequence of N tokens, that means N squared comparisons.
At 1,000 tokens, you have 1 million comparisons. At 10,000 tokens, you have 100 million. At 100,000 tokens, you have 10 billion. The cost grows quadratically: doubling the sequence length quadruples the compute.
Imagine a room where every person has to shake hands with every other person. With 10 people you have 45 handshakes. With 100 people you have 4,950. With 1,000 people you have nearly half a million.
Adding more people does not just add more handshakes linearly. It explodes. Attention has the same structure.
This is not a hardware limitation you can engineer around with more chips. It is the mathematical structure of attention itself.
A model with a 4K context window is fast and cheap to run. The same model architecture with a 128K context window is dramatically slower and more expensive, even with no other changes. The attention matrix alone grows 1,024 times larger.
This is why for a long time most models capped at 4K or 8K tokens. It was not a lack of ambition. It was economics.
THE KV CACHE
Extending context became more practical with one key optimization: the KV cache, short for key-value cache.
In article three, attention computed key and value vectors for every token at every layer. When you generate a new token, the model would recompute those vectors for the entire sequence from scratch, including the part that has not changed. This is like re-reading a whole book every time you add a sentence.
The KV cache stops that. After processing the prompt, the model stores the computed key and value vectors for each token at each layer. When generating the next token, it reads from the cache instead of recomputing. Only the new token requires fresh computation.
This makes generation dramatically faster and makes long contexts viable. Without the KV cache, a 128K context window would require 128K passes of full attention for every single token generated. With it, the prompt pays its compute cost once, and generation proceeds token by token with only the incremental work.
The tradeoff is memory. The KV cache lives in GPU VRAM, and it grows linearly with context length.
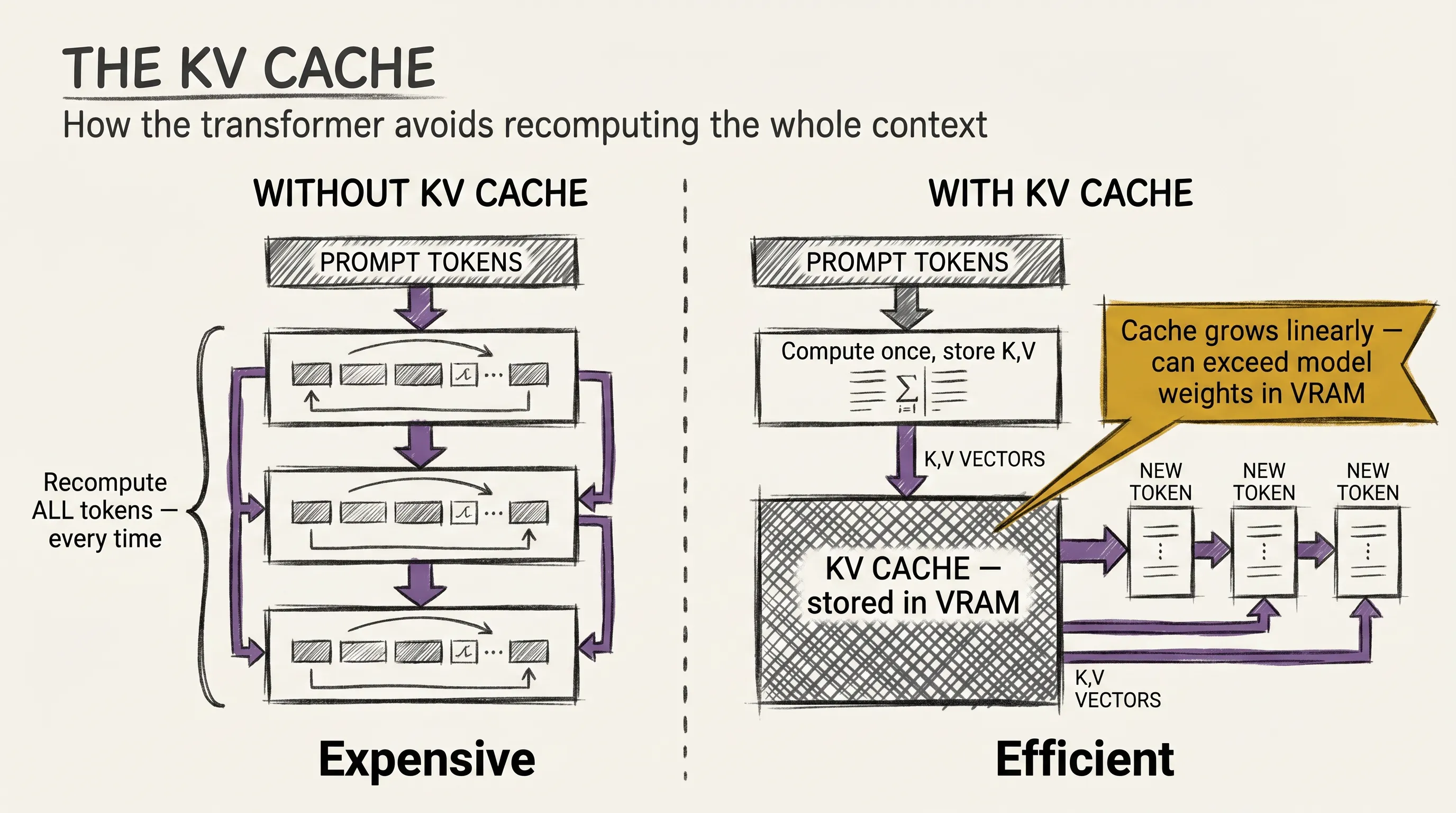
A model with a 128K context window and a large embedding dimension can have a KV cache that consumes more memory than the model weights themselves. Long contexts are not just slower. They are genuinely more expensive to serve.
TECHNIQUES FOR LONGER WINDOWS
Several approaches have emerged to reduce the quadratic cost of attention at long range.
Sliding window attention limits each token to attending only to its local neighborhood, say the 4,096 nearest tokens, rather than the full sequence. Think of it as attending to the last few pages of a book rather than the whole thing. This keeps attention cost linear with context length, not quadratic. The model loses the ability to directly attend to distant tokens, but many tasks only need local context anyway.
Sparse attention is a generalization: instead of attending to all tokens or only nearby ones, each token attends to a learned or fixed subset. The pattern can be local windows, strided patterns, or combinations. The goal is to capture what matters while discarding the bulk of the O(N squared) pairs.
Rotary position embeddings, or RoPE, are the positional encoding approach from article five, now standard in most modern models. RoPE handles longer sequences better than the original sinusoidal approach because the rotational structure extends more gracefully. Research has shown RoPE can generalize to sequences longer than those seen during training with the right fine-tuning, though not indefinitely.
None of these completely eliminate the cost. They reduce it, often significantly, but a model running a one-million-token context window is still doing an enormous amount of work.
WHAT THIS MEANS IN PRACTICE
A 128K context window holds roughly a hundred thousand words of text, which is a long novel. That sounds enormous until you see what eats the tokens in practice.
System prompts can run thousands of tokens before you type a word. Every round of conversation accumulates. Pasted documents consume context fast. Code, which tokenizes inefficiently, goes through the window even faster.
The practical rule is simpler than the math: the effective context is usually less than half the advertised limit. Put the most important information near the start of the prompt and near the most recent exchange.
Research on attention patterns consistently shows that models attend most reliably to the beginning and end of their context, with a dip in the middle. This is sometimes called the lost in the middle problem. The model behaves like a reader who pays close attention to the first and last pages of a document and skims the middle. If a critical fact lives on page 150 of a 300-page context, the model may miss it even though it technically fits in the window.
Longer context windows do not solve the forgetting problem. They delay it. The underlying challenge, how to let a model effectively use information that is far back in a long sequence, is still an active research area.
The next article covers what happens when you scale up the model itself: parameter counts, what 70B actually means, and the scaling laws that predict how much capability you get per additional unit of compute.
T.
References
-
Attention Is All You Need (Vaswani et al., 2017) - The original transformer paper. The O(n^2) attention complexity is the structural constraint that makes context window extension expensive by default.
-
Lost in the Middle: How Language Models Use Long Contexts (Liu et al., 2023) - Empirical study showing model performance degrades on information placed in the middle of long contexts, with strongest retrieval at beginning and end positions.
-
Longformer: The Long-Document Transformer (Beltagy et al., 2020) - Introduces sliding window attention and global attention patterns as practical alternatives to full quadratic attention for long documents.
-
RoFormer: Enhanced Transformer with Rotary Position Embedding (Su et al., 2021) - The RoPE paper. Rotary embeddings are now standard in LLaMA, Mistral, and most modern production models, and handle context extension more gracefully than learned or sinusoidal approaches.
-
Efficient Streaming Language Models with Attention Sinks (Xiao et al., 2023) - Shows that a small number of initial tokens receive disproportionate attention regardless of content, which helps explain why information at the start of context is reliably attended to.