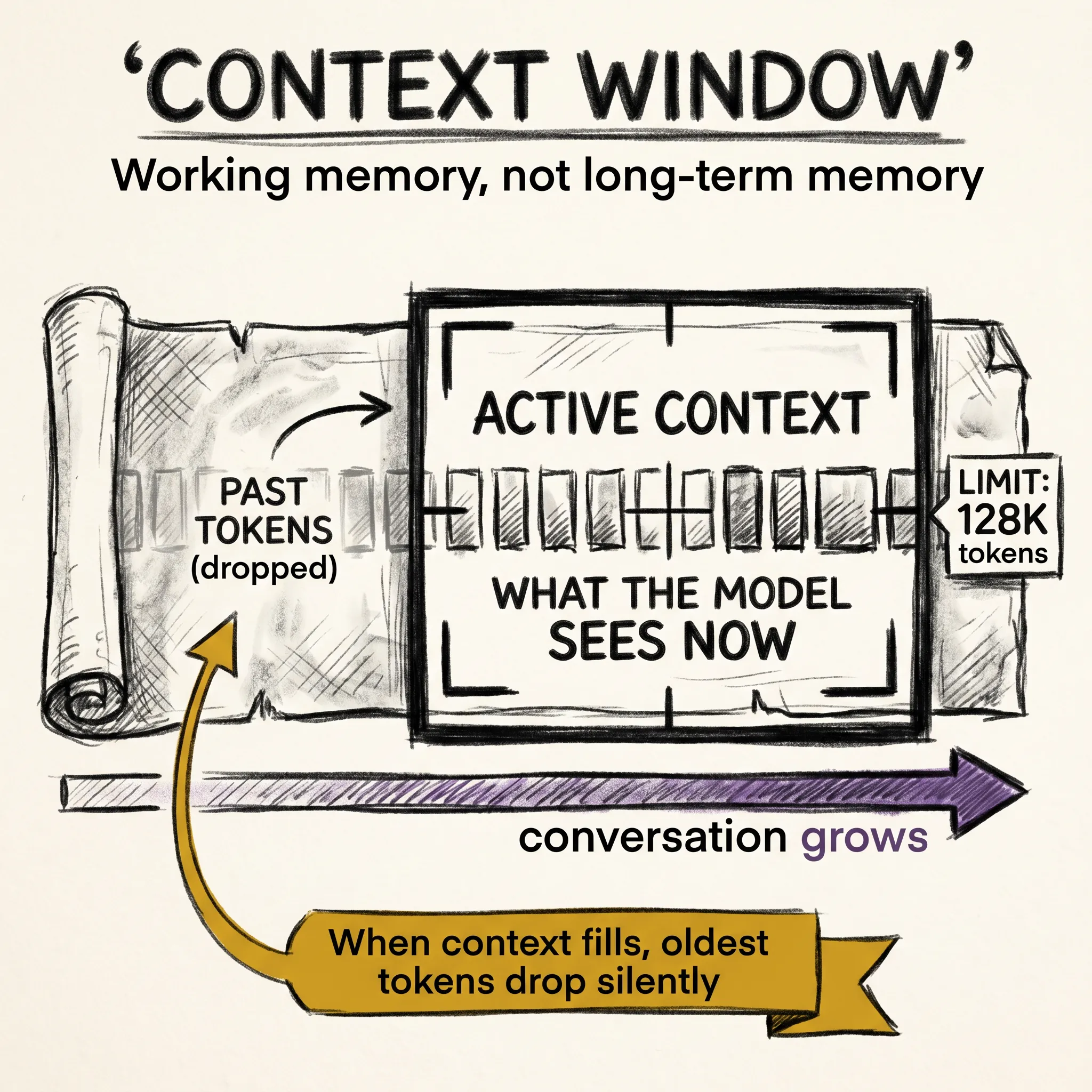
The previous article described how the transformer’s attention mechanism works: every word looks at every other word directly, in parallel, and decides what is relevant. But there is a step that happens before any of that.
The model cannot read.
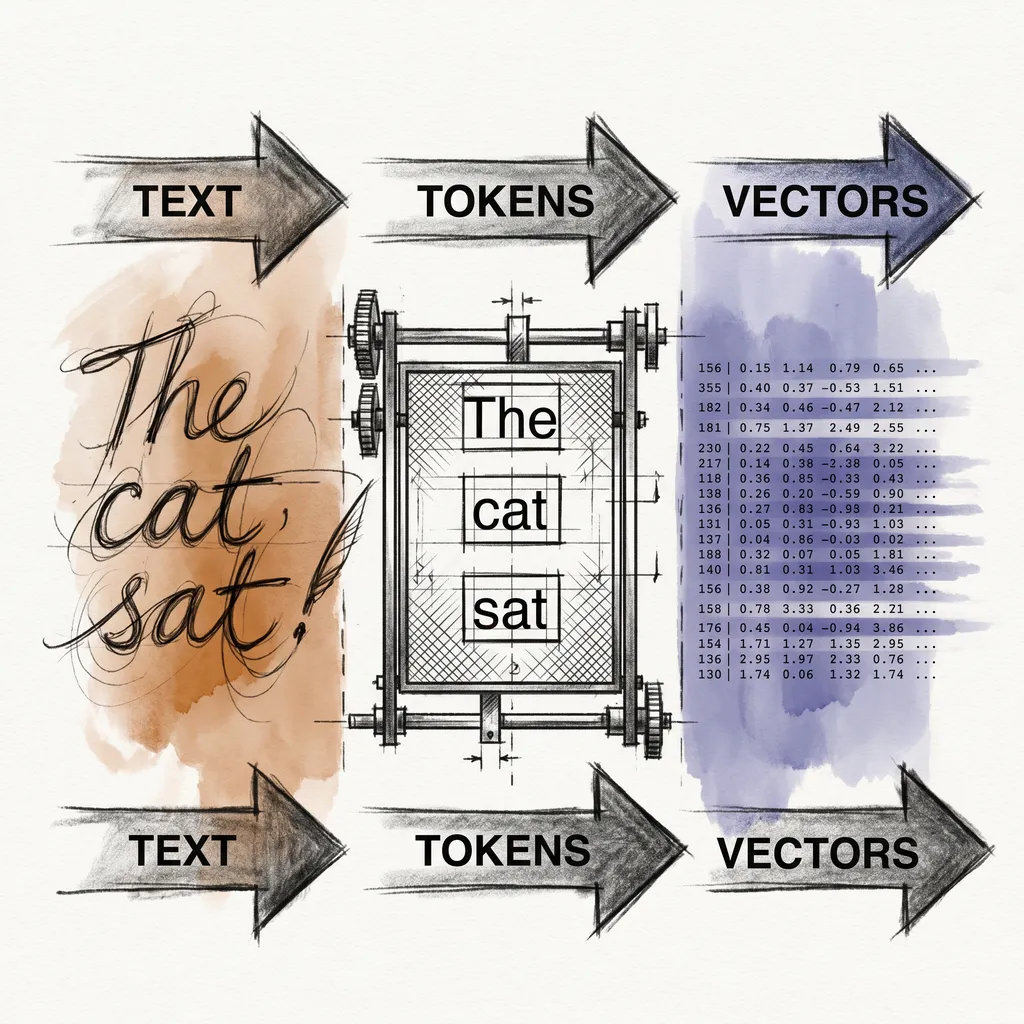
It cannot process letters, spaces, or punctuation as symbols the way you and I do. It can only work with numbers. So before any attention happens, your text has to go through a conversion pipeline. By the end of this article, you will know exactly what that pipeline does, and what it means that a model understands a word at all.
THE PROBLEM WITH WORDS
The obvious solution would be to assign each word a number. The gets 1. Cat gets 2. Sat gets 3.
You could build a lookup table for every word in English and feed those numbers to the model. Seems clean enough on paper.
The problem is that this approach breaks on contact with real text. Vocabulary is not fixed. Languages invent new words constantly. People misspell things, use slang, and coin terms.
A word-level dictionary that covered all real-world text would need millions of entries, and it would still fail on anything it had never seen. A single out-of-vocabulary word would leave the model with nothing.
There is a second problem. Cats and cat would be completely different entries, even though they share almost everything. Running and runner and ran would be unrelated. Any morphological connection that a human sees instantly would be invisible to the model.
TOKENS ARE NOT WORDS
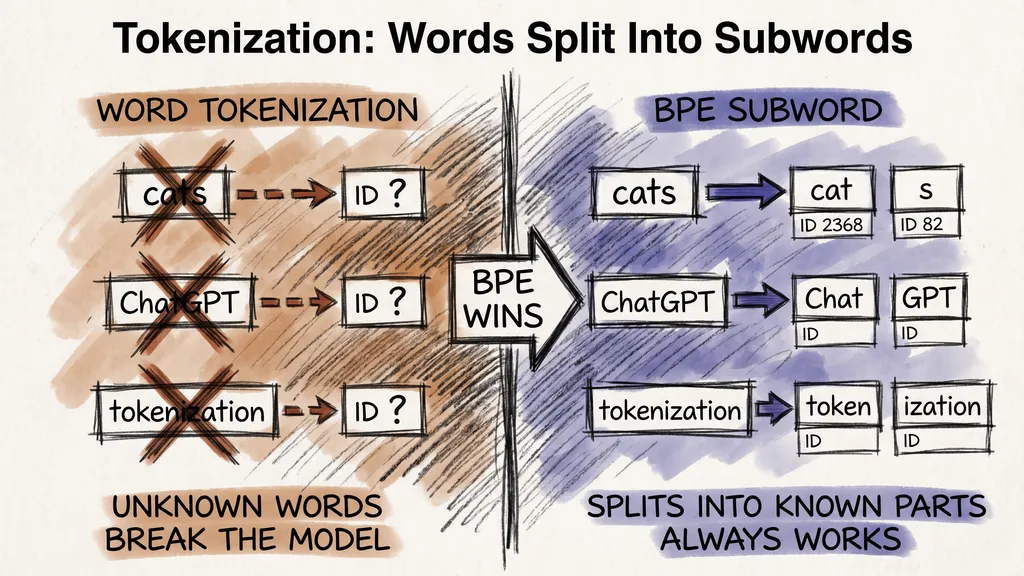
The solution that large language models actually use is subword tokenization. Instead of splitting text at word boundaries, the model splits it into smaller units that are bigger than characters but smaller than words. These units are called tokens.
The most common algorithm for building these units is Byte Pair Encoding, or BPE. The idea is simple: start with individual characters as your base vocabulary, then repeatedly find the pair of symbols that appears most often together and merge them into a new unit. Repeat thousands of times until the vocabulary reaches the target size.
Common words end up as single tokens. Rarer words get split into recognizable pieces.
The word tokenization might become [token, ization]. The word unbelievably might become [un, believ, ably]. A word the model has never seen gets split into its components, and the model can work with those pieces. The approach is similar to how you sound out an unfamiliar word by breaking it into syllables you recognize.
I find this solution surprisingly elegant. It is not how humans read at all. We see whole words and grab their meaning in one shot. But for a system that needs to cover all of language from a fixed vocabulary, subword tokenization is the right tradeoff.
THE VOCABULARY
Every model has a fixed vocabulary: the complete list of all tokens it knows. GPT-4 uses around 100,000 tokens. Llama 3 uses 128,000.
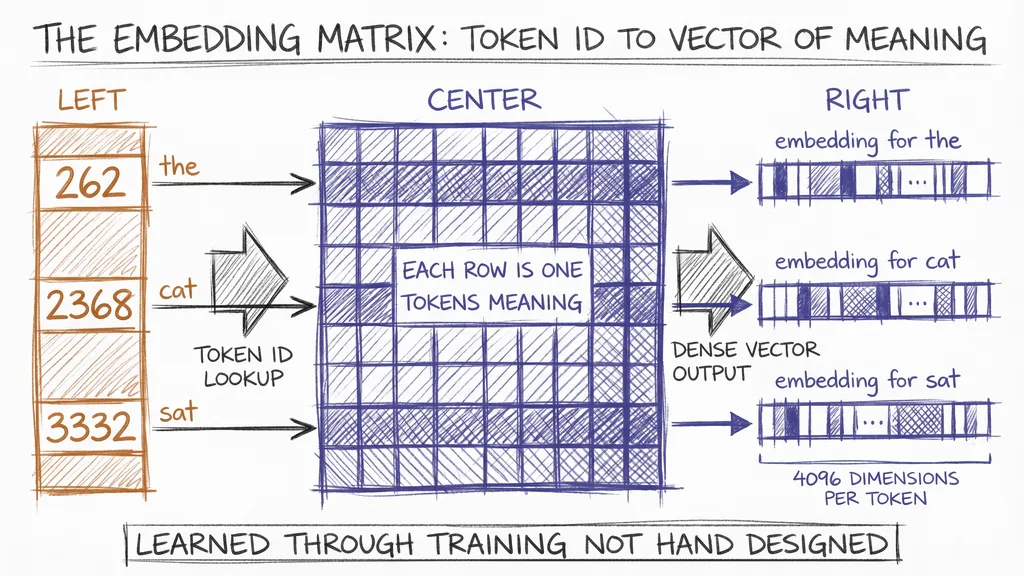
The vocabulary gives each token a unique integer, its token ID. The word the might be token 262. The word transformer might be token 47208. The newline character might be token 198.
The mapping is fixed and deterministic, like a phone book where every token has exactly one number and that number never changes.
When you send a prompt to a language model, the tokenizer converts your text string into a sequence of token IDs. The cat sat becomes something like [262, 3797, 3332]. That sequence of integers is what the model actually receives as input.
This is also why models sometimes behave strangely with numbers. The string “9.11” does not necessarily become a single token. Depending on the tokenizer, it splits into three separate pieces: the digit 9, a period, and the digits 11.
The model then processes those three pieces with no built-in arithmetic relationship between them. It is not a calculator reasoning about values.
FROM NUMBERS TO MEANING
At this point the model has a sequence of integers. But integers by themselves carry no semantic content. The number 262 does not mean anything on its own.
To get from token ID to something the model can reason about, there is one more step. Each token ID gets looked up in a table called the embedding matrix, and what comes back is a dense vector of floating-point numbers. This vector is the token’s embedding.
Think of the embedding matrix as a library where every token has a shelf, and on that shelf sits a long list of numbers, say 4096 of them, that together encode the token’s meaning. The embedding for king is a specific point in that high-dimensional space. The embedding for queen will be close to it. The embedding for table will be far away.
No one designs these positions by hand. They emerge from training.
HOW EMBEDDINGS LEARN MEANING
The embedding matrix starts as random noise. During training, the model processes billions of examples and adjusts its weights through backpropagation. The embedding matrix is part of those weights, and it shifts with every update.
Over time, tokens that appear in similar contexts drift toward each other in the embedding space. Tokens that rarely appear together drift apart. The model was never told that king and queen should be neighbors. That relationship crystallized from the statistics of how those words co-occur in text.
The geometry of this space captures real semantic structure. The vector difference between king and man turns out to be roughly the same as the difference between queen and woman.
Plural forms cluster near their singulars. Past tenses cluster near present tenses. No one designed any of this.
This is the part I think people underestimate. The model does not have a dictionary entry for justice that says “abstract noun, relating to fairness.” It has a 4096-dimensional vector encoding how justice behaves in relation to every other concept in the vocabulary, learned from every sentence in its training data. That is a very different kind of representation.
THE COMPLETE PIPELINE
The tokenizer breaks your text into a list of token IDs. The embedding matrix looks up each ID and returns a dense vector. Then positional information gets added to each vector so the model knows where in the sequence each token sits.
That last step, positional encoding, is the subject of the next article.
The output of this pipeline is a matrix: one row per token, each row a dense vector of floating-point numbers. This is what the transformer’s attention layers actually operate on. All the queries, keys, and values from the previous article work on these vectors. The whole machinery described there was waiting for exactly this input.
The text is gone. What remains is geometry.
T.
References
-
Neural Machine Translation of Rare Words with Subword Units (Sennrich et al., 2016) - The paper that introduced Byte Pair Encoding to NLP, the subword tokenization algorithm now used in GPT, LLaMA, and most major language models.
-
Efficient Estimation of Word Representations in Vector Space (Mikolov et al., 2013) - The Word2Vec paper that first demonstrated learned word embeddings capturing semantic geometry, including the famous king-man+woman=queen result.
-
Language Models are Few-Shot Learners (Brown et al., 2020) - The GPT-3 paper, which details the tokenizer and embedding dimensions used in a production-scale language model, including the 50,257-token vocabulary and 12,288-dimensional embeddings.
-
tiktoken (OpenAI, 2022) - The open-source tokenization library used by GPT-3.5 and GPT-4, with the cl100k_base vocabulary. Lets you tokenize any text and see exactly how it is split.