In 2017, eight researchers at Google published a nine-page paper with an unusually confident title: Attention Is All You Need. It proposed to replace the dominant architecture in natural language processing with something completely different. Within two years, that proposal became the foundation of every major language model on the planet.
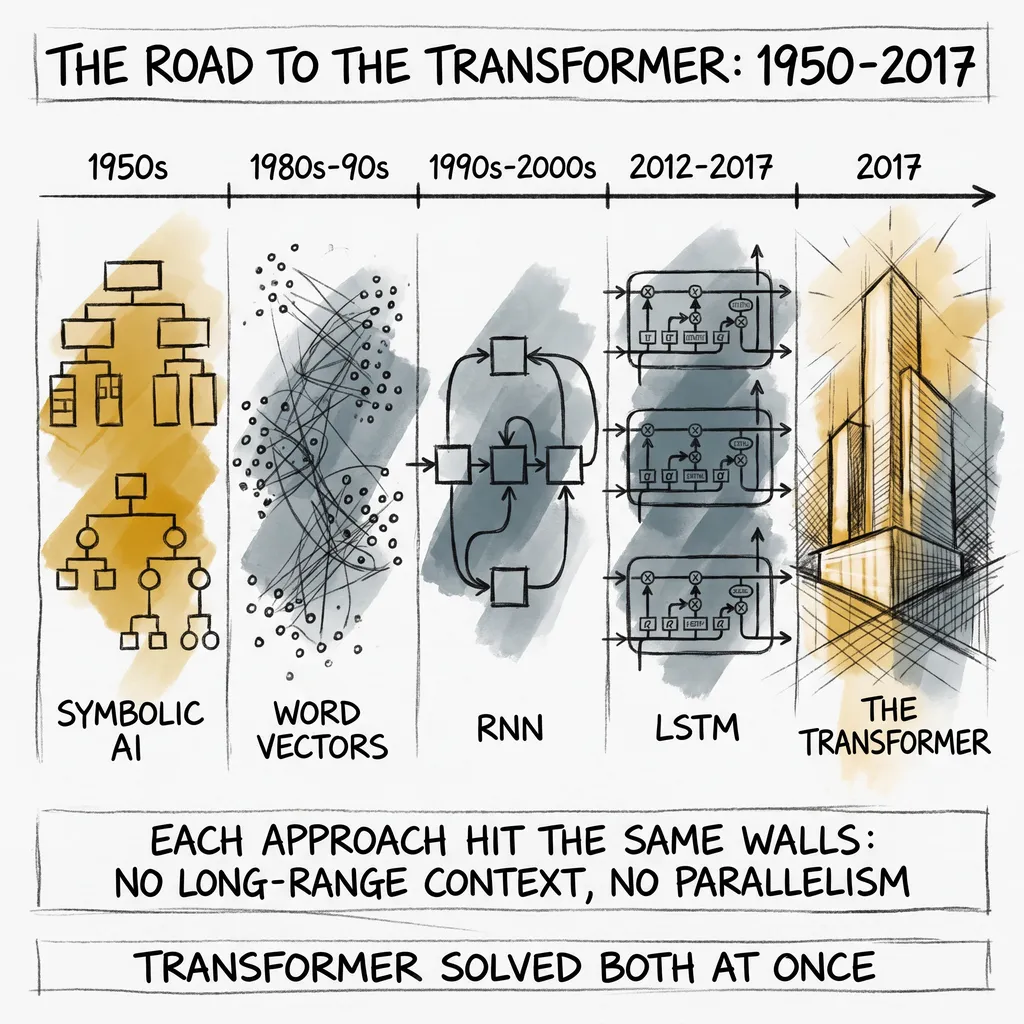
The previous article covered everything that came before: symbolic AI, word vectors, RNNs, and LSTMs. Each approach hit the same two walls: sequential processing that could not be parallelized, and information that degraded over distance. The transformer solved both at once, and it did it with one idea.
THE PROBLEM IN ONE SENTENCE
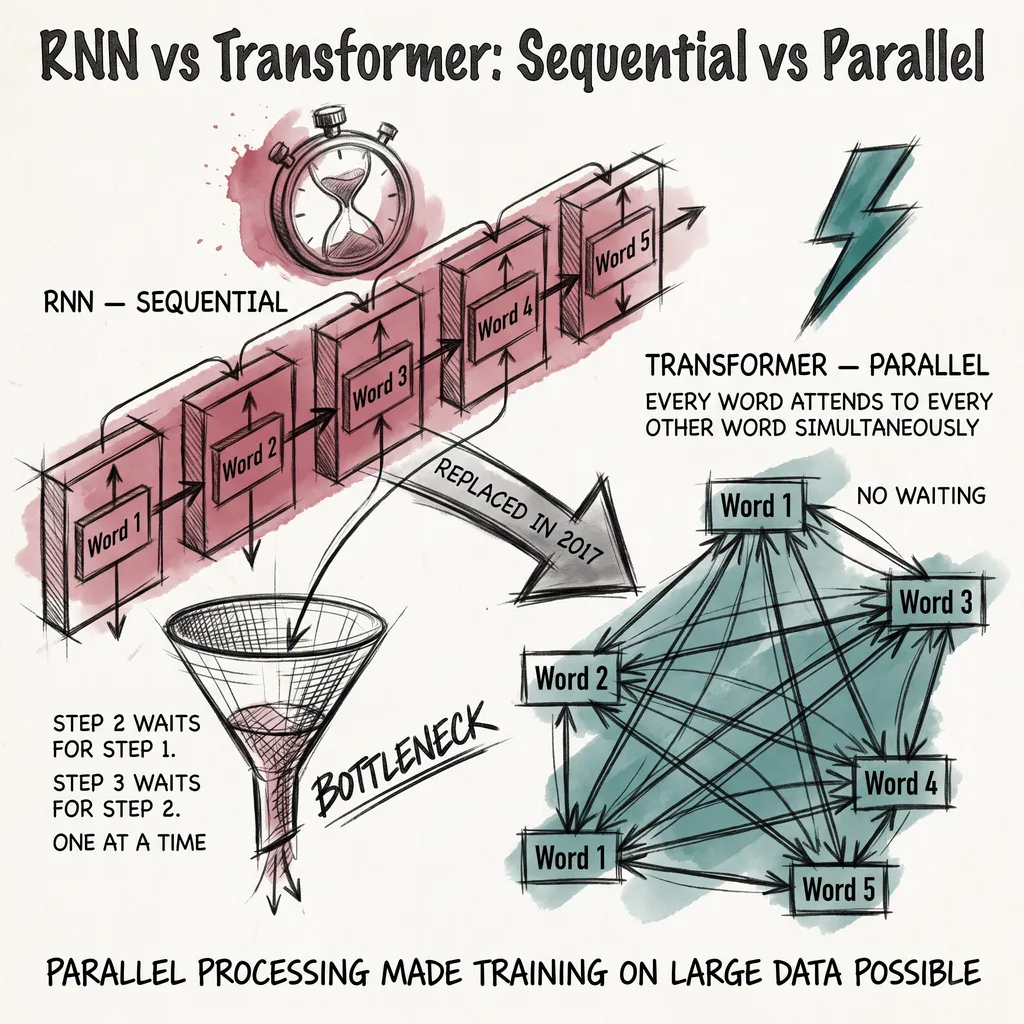
An RNN reads text the way you might read a novel while someone rips out pages behind you. You carry a running summary, update it word by word, and hope the relevant details survive long enough to matter. For a short sentence this works reasonably well. For a long document, important context gets overwritten by everything that comes after it.
The transformer asks a different question entirely. Instead of processing words in order and hoping context survives, what if every word could look directly at every other word and decide for itself what is relevant?
That is attention.
WHAT ATTENTION ACTUALLY IS
For each word in the input, the model creates three vectors: a query, a key, and a value. Think of it like a library search. The query is what you are looking for. The keys are catalog entries for every book on the shelf.
When processing the word it in the sentence “The animal crossed the road because it was tired,” the model uses it as a query and compares it against the keys for every other word. It gets back a weighted mix of all the values. The word animal scores highest, because the model has learned that pronouns usually refer to nearby nouns. The word was scores low, because it carries little useful information.
No one programs these weights by hand. The model learns them during training, across billions of examples, until the attention pattern reliably captures what matters for each context.
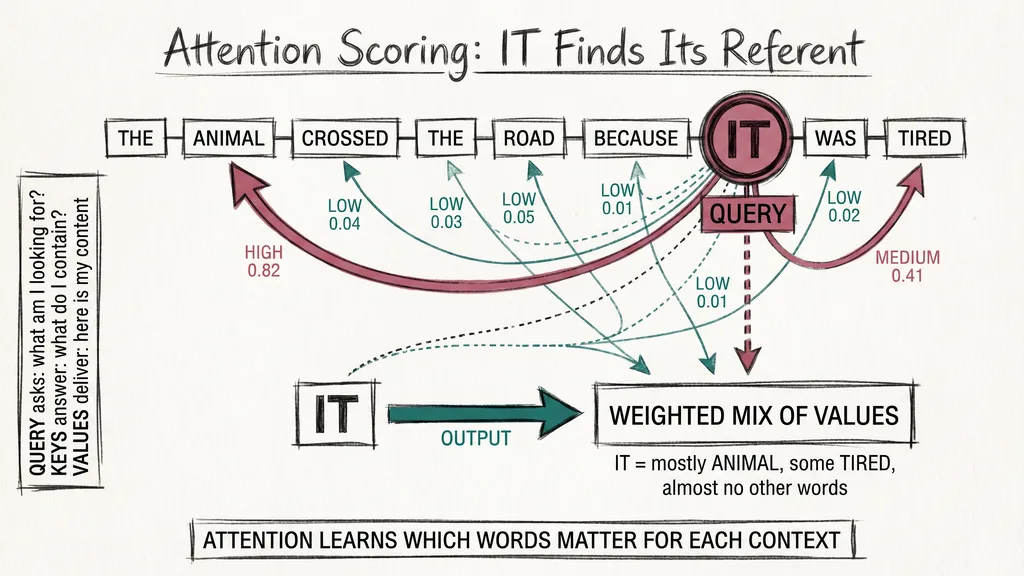
This is fundamentally different from an RNN. An RNN processes animal and moves on, hoping that information survives to when it appears several words later. Attention reaches back directly, with no chain of steps in between. Distance does not weaken the connection.
MULTI-HEAD ATTENTION AND THE PARALLEL LEAP
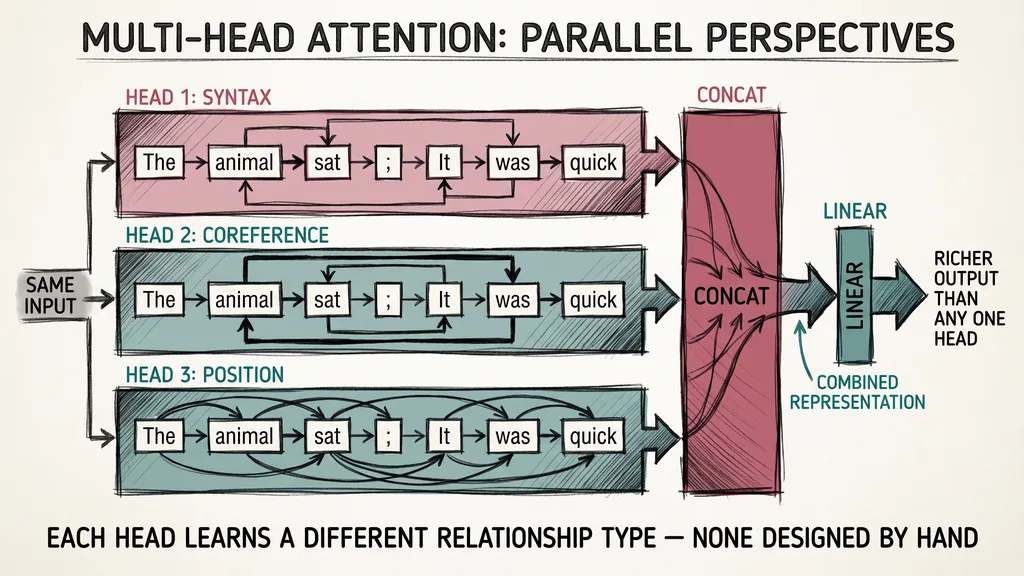
One attention mechanism is powerful. The transformer uses several running in parallel, and the intuition is easy to follow. A single attention head can only focus on one kind of relationship at a time. Multiple heads can track syntax, semantics, coreference, and position all at once, then combine their findings.
Think of it like a detective working a case by sending different analysts to examine different aspects of the evidence simultaneously: one on forensics, one on witnesses, one on financials. Each specialist focuses on their lane. You combine their reports at the end for a richer picture than any one of them could produce alone.
The technique has a name: multi-head attention. It is also where the sequential bottleneck finally breaks.
In an RNN, step 3 cannot begin until step 2 is finished. In a transformer, every position computes its attention simultaneously. On modern hardware, a transformer processes a full sentence in roughly the time it takes an RNN to process one word. Training on large datasets became feasible where it had not been before.
This matters more than it might seem. The transformer was not just better at language. It was better in a way that scaled with hardware improvements.
More GPUs meant faster training, bigger models, better results. The architecture and the hardware trend were perfectly matched.
THE REST OF THE ARCHITECTURE
Two more pieces complete the picture.
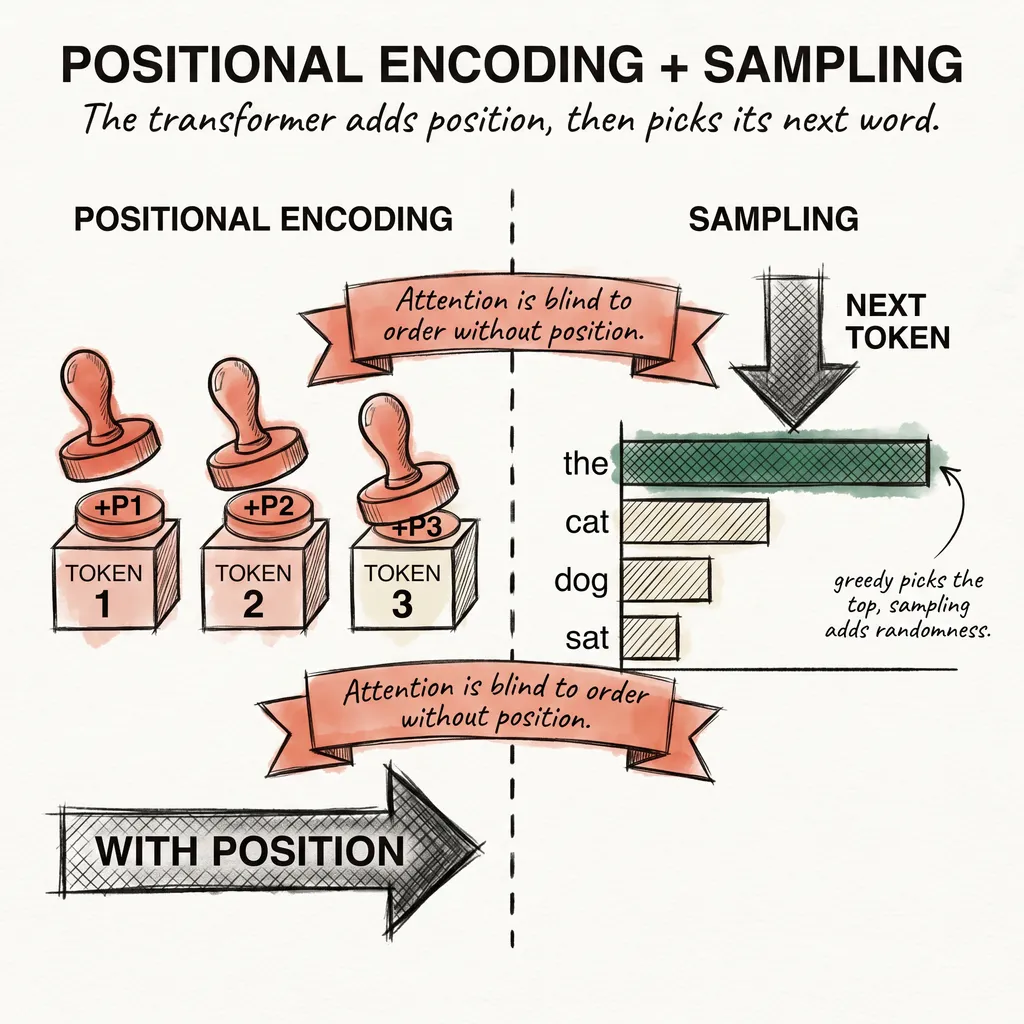
Positional encoding is the part that surprises most people. If every word attends to every other word simultaneously, the model has no natural sense of order. The word dog at position 1 and the word dog at position 7 would look identical without some extra signal.
Think of it like seat numbers in a concert hall. The music is the same regardless of where you sit, but without a number printed on your ticket you cannot tell row 1 from row 7. Position, like seat assignment, has to be added explicitly. The transformer does this by encoding each position as a pattern of sine and cosine values at different frequencies, stamped onto each word’s representation before the attention step.
The original transformer also had an encoder and a decoder. The encoder reads the full input and produces a rich representation of it. The decoder generates output one token at a time, attending both to the encoder’s output and to what it has already generated. This split worked well for translation: encode the source language, decode the target.
Later architectures simplified this. BERT kept only the encoder for understanding tasks. GPT kept only the decoder for generation tasks. Both became foundational.
WHY EVERYTHING AFTER IS A TRANSFORMER
I was not following the field closely when the 2017 paper landed. But looking back now, what surprises me is not that it worked. It is that nothing better has arrived since.
Most architecture proposals get two or three years of dominance before something displaces them. The transformer has been the foundation for almost a decade.
The reason is not mysterious. It solved the right constraints at exactly the moment the field needed to scale. Language models before 2017 could not see much context at once, and training large ones took too long to be practical. Attention removed both constraints at the same time.
GPT-1 was a decoder-only transformer, released in 2018. GPT-3 was the same architecture, much larger. Claude, Gemini, and GPT-4 all build on variations of the same blueprint.
Whether the transformer is the correct long-term answer is a genuinely open question. I suspect it is not the final word. But that is a later article.
The next article covers what happens when you actually train a transformer: tokens, embeddings, and the mechanics of turning raw text into numbers the model can operate on.
T.
References
- Attention Is All You Need (Vaswani et al., 2017) - The original transformer paper proposing multi-head self-attention as a complete replacement for recurrent architectures.
- The Illustrated Transformer (Jay Alammar, 2018) - Visual step-by-step walkthrough of the transformer architecture, widely cited as the best accessible explanation available.
- BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018) - The encoder-only transformer that redefined benchmarks across nearly every NLP task within a year of the original paper.
- Language Models are Few-Shot Learners (Brown et al., 2020) - The GPT-3 paper demonstrating how scaling a decoder-only transformer produced emergent capabilities at 175 billion parameters.