Most “let’s fine-tune the model” instincts are wrong. The first time a team hits a wall with a generic LLM, the same reflex kicks in: train it on our data, then everything will work. Six weeks and a GPU bill later, they end up with a slightly worse version of what a better prompt would have given them in an afternoon.
So when is fine-tuning the right answer? This article is about what LoRA actually does to make it cheap, and why most fine-tune questions are really prompt or retrieval questions wearing a costume. The story is shorter than people expect, and the practical takeaway fits in one sentence.
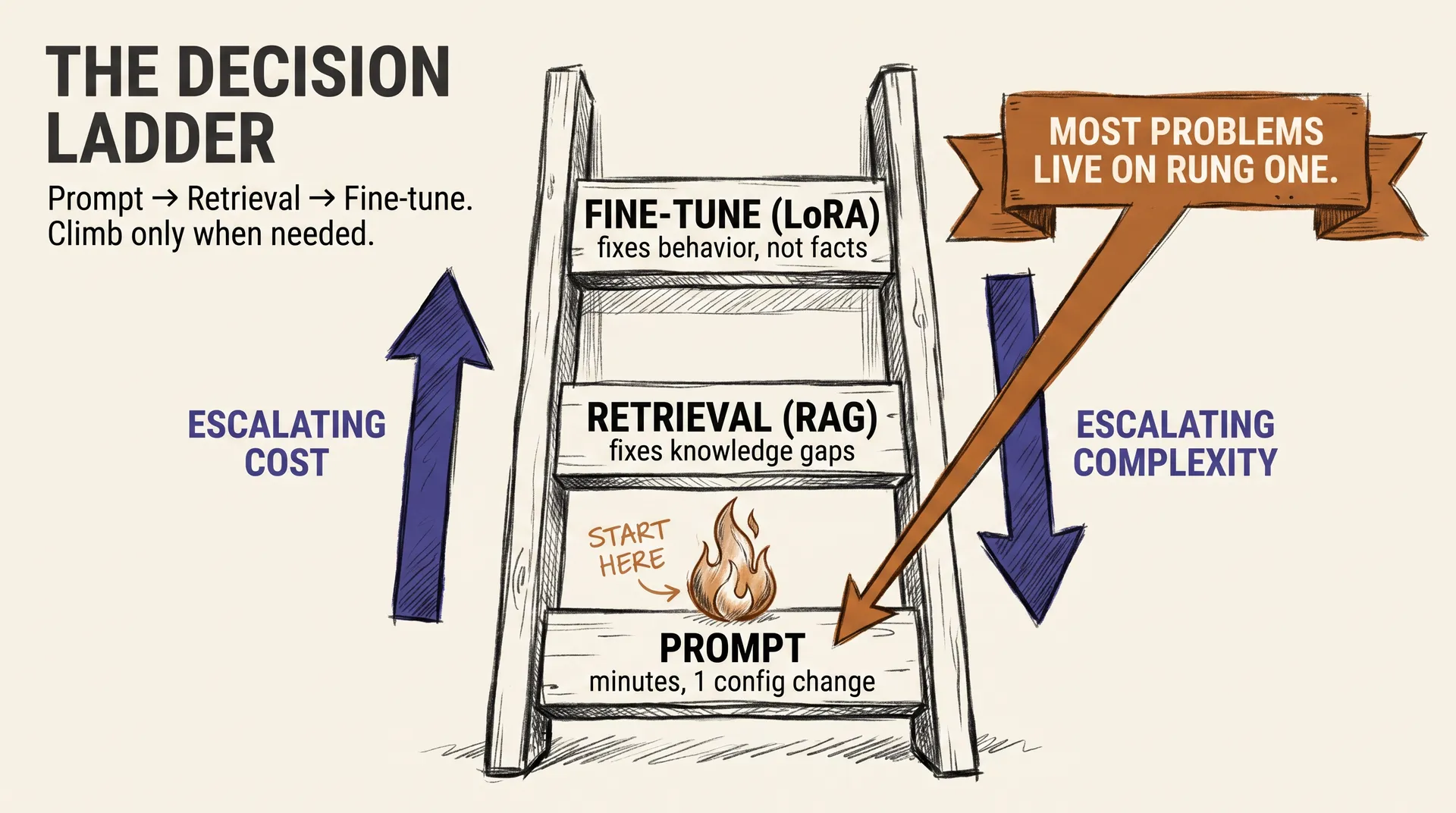
THE DECISION LADDER
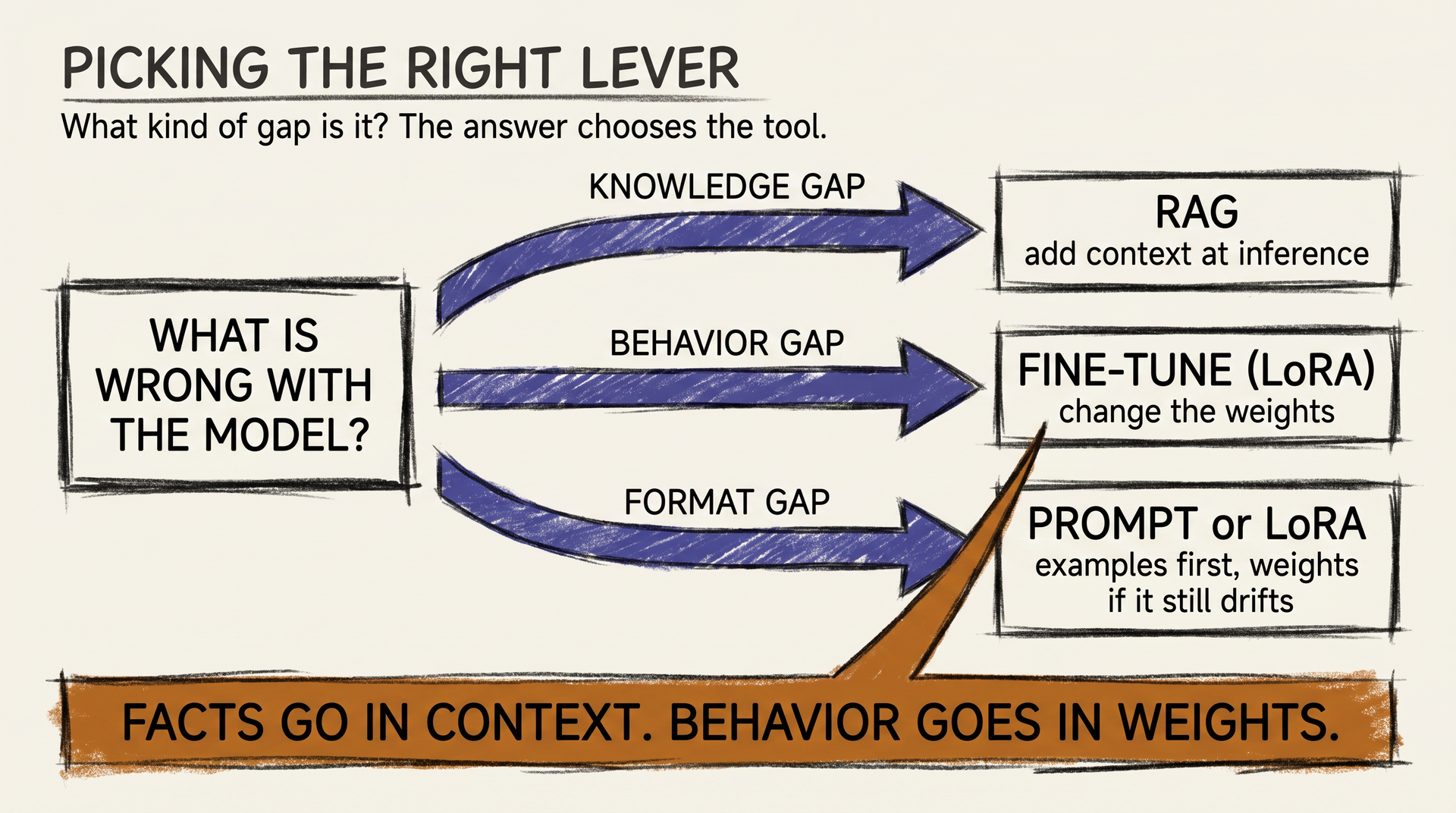
Before touching weights, walk the ladder. Think of it like a thermostat: you do not rewire the house when the room feels cold, you turn the dial first.
THE PROMPT RUNG. The cheapest, fastest lever. You change the system prompt, add a few examples, restructure the request.
If the model behaves well after a careful prompt rewrite, you are done. The cost is minutes; the deploy is one config change.
The prompt rung does most of the heavy lifting in production. The previous article on prompting and RAG covers this in depth, and the honest answer is that ninety percent of “our LLM is dumb” complaints I hear could be fixed there.
THE RETRIEVAL RUNG. The model is fluent but ignorant of your facts. Your product manual, your customer history, your codebase. Retrieval-augmented generation hands the relevant chunks to the model at inference time.
The model knows English; you supply the dictionary for your domain. RAG fixes a knowledge problem, not a behavior problem. Confusing the two is, in my experience, the single most common mistake in this space.
THE FINE-TUNE RUNG. The model knows the facts and reads the prompt fine, but its behavior is still wrong.
It refuses things you want it to do. It writes in a tone that does not match your brand. It produces JSON that drifts from your schema half the time.
These are not knowledge gaps. They are habits. And habits live in the weights.
The one-sentence rule, and the only thing most readers need to remember from this article: fine-tune when behavior needs to change, not when facts do.
WHAT LORA ACTUALLY DOES
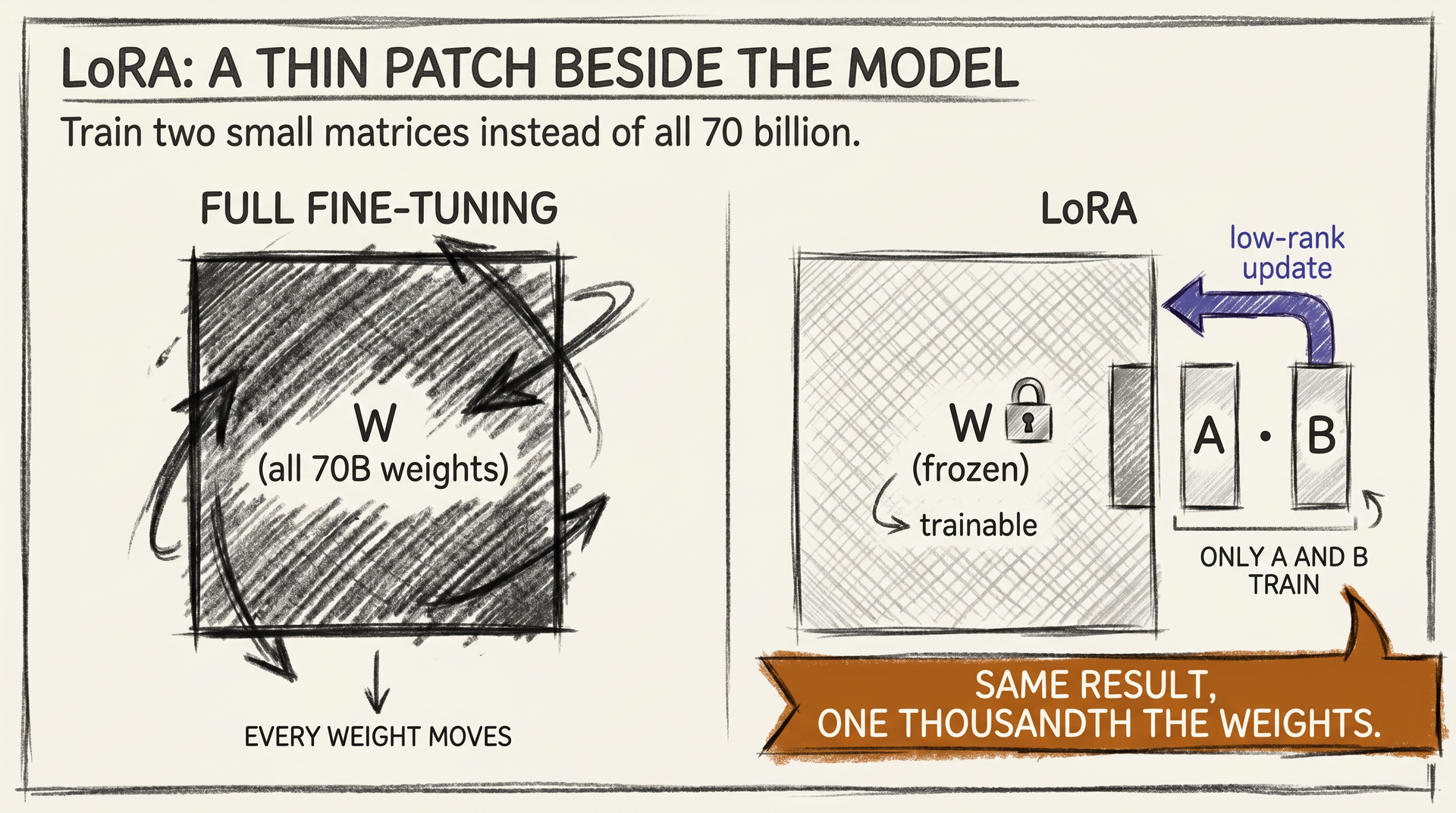
A 70B model has 70 billion weights. Full fine-tuning means nudging every one of them. That demands huge GPUs, takes days, and produces a new 140 GB checkpoint that is now incompatible with everything else you ship. For most teams, that is a non-starter.
LoRA, which stands for Low-Rank Adaptation, is the elegant workaround. Instead of touching the original weights, you freeze them and train two small matrices that get added on top.
Multiplying the two matrices gives you a low-rank update, a thin patch sitting on the side of each layer. The base model never changes; the patch learns your task. Think of it the way an electrician treats an old house: nobody rewires the walls, so you add a thin extension behind the trim and route the new circuit through that.
The numbers are absurd in the best way. A LoRA adapter for a 7B model is often around 20 MB. For a 70B model, somewhere between 100 and 400 MB depending on rank. A single base model can host dozens of adapters, each fluent in a different specialty, and you slot them on or off at inference time the way a router slots a config file.
The mental picture I find useful is sticky notes on a textbook. Full fine-tuning rewrites the textbook. LoRA leaves the textbook alone and adds yellow tags that say use this voice here, refuse that there. The textbook still teaches everything it taught before, but in your office it reads itself differently.
QLORA AND THE LAPTOP MOMENT
LoRA was 2021. QLoRA, the 2023 paper by Tim Dettmers, was the moment fine-tuning escaped the data center.
QLoRA combines two tricks. First, load the base model in 4-bit precision instead of 16-bit. That alone shrinks a 70B model from around 140 GB to under 40 GB of VRAM.
Then train LoRA adapters on top of that quantized base. The base stays frozen and tiny in memory; only the adapter actually learns. It is a clever swap, like brewing strong coffee from less ground by simply running the water hotter.
The practical headline is that a 7B model can be fine-tuned on a single consumer 24 GB GPU in a few hours, for the cost of an evening of electricity. A 70B model fits on a single workstation with one or two professional cards. The work that needed a cluster in 2022 needs a desk in 2026, and that is not a marketing line; it is the actual reason fine-tuning went mainstream.
This is also why every serious local-model toolchain (Axolotl, Unsloth, the Hugging Face PEFT library) ships QLoRA as the default path. Full fine-tuning is now the exotic choice, reserved for teams who really do need to move every weight.
WHEN FINE-TUNE ACTUALLY WINS
After all that, the situations where LoRA is the right tool are narrow.
It wins when output format must be exact. A model that emits structured data half-correctly is worse than one that emits it consistently, the same way an unreliable train is worse than no train at all. A small LoRA on a few hundred well-formed examples will lock the schema in tighter than any prompt instruction.
It wins for style and voice. If you want a chatbot to sound like your support team and not like a model, a LoRA trained on your past tickets does in one pass what a 4000-token system prompt does badly. Honestly, this is the case where I find the cost easiest to justify.
It wins for refusal behavior in domains where you cannot trust the generic safety training. Medical, legal, security tooling. The alignment article on this site covers why this lives at the training layer, not the prompt layer.
And it wins when you have a clean dataset, ideally a few thousand high-quality examples. Without that, fine-tuning will faithfully learn whatever noise is in your data. The result will be confidently worse than the base, which is the worst kind of failure mode in this field.
It loses when the real problem is missing facts (use RAG), when you have fewer than a few hundred examples (use few-shot prompting), or when you cannot articulate in one sentence what new behavior you want.
THE NUMBERS YOU CAN ACT ON
For a working reader in 2026, the cheat sheet looks roughly like this. A 7B model with QLoRA on a 24 GB consumer GPU takes two to six hours and costs about the price of a nice dinner if you rent the GPU. A 13B model on the same card is overnight. A 70B QLoRA on dual professional cards is a weekend.
Full fine-tuning of a 70B is still a serious cluster job, and almost nobody outside a frontier lab should attempt it. Pretraining the same model from zero (covered in AI training, how models get smart) is a different order of magnitude entirely, measured in tens of millions of dollars and weeks of compute.
The toolchains have converged. Unsloth is the speed leader for single-GPU runs. Axolotl is the YAML-driven workhorse for production teams.
The PEFT library from Hugging Face is the lowest-level option and gives you the most control. All three speak the same LoRA and QLoRA primitives underneath, which means picking between them is like picking between hammers in the same toolbox.
THE TEST
The honest test for any fine-tuning project is one question. Could a better prompt or a smarter retrieval pipeline get me eighty percent of the way?
If the answer is yes, do that first. If the answer is no, write down the specific behavior you want and how you will measure it, gather a few hundred examples, and try a QLoRA run. You will know within an afternoon whether the change is real. The worst outcome is that you confirm what was already true and move on.
Fine-tuning is a power tool. Like every power tool, it is most useful in the hands of someone who has already tried the screwdriver.
T.
References
- LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021) - The original LoRA paper. Introduces the low-rank update trick that made adapter-based fine-tuning the default.
- QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al., 2023) - The paper that combined 4-bit quantization with LoRA adapters and put 70B fine-tuning on a single workstation.
- Hugging Face PEFT Library - The reference implementation of LoRA, QLoRA, and related parameter-efficient fine-tuning methods.
- Unsloth - The fastest single-GPU LoRA and QLoRA trainer in 2026, with kernels tuned for consumer hardware.
- Axolotl - The YAML-driven fine-tuning framework most production teams use to manage LoRA training runs at scale.