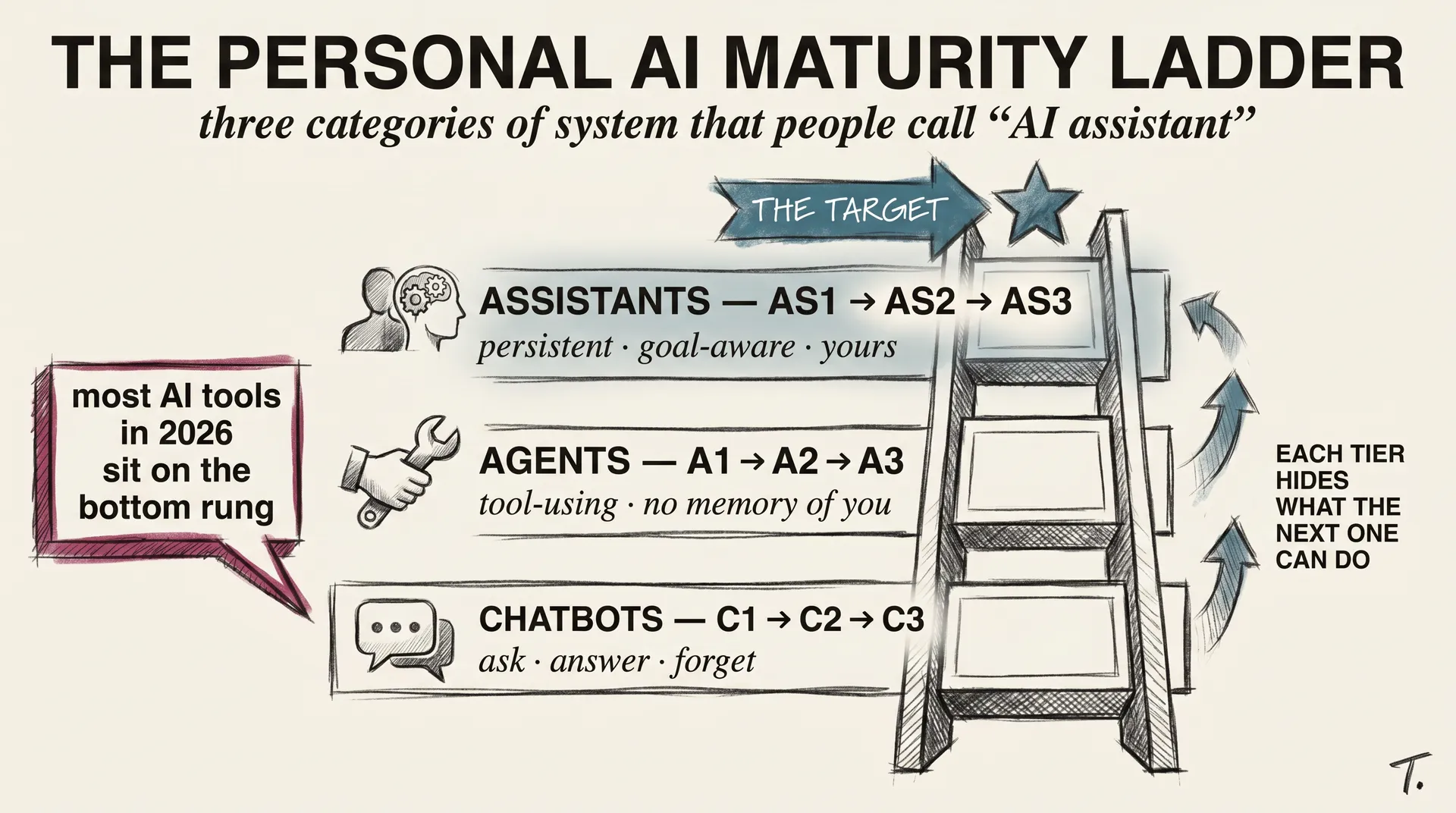
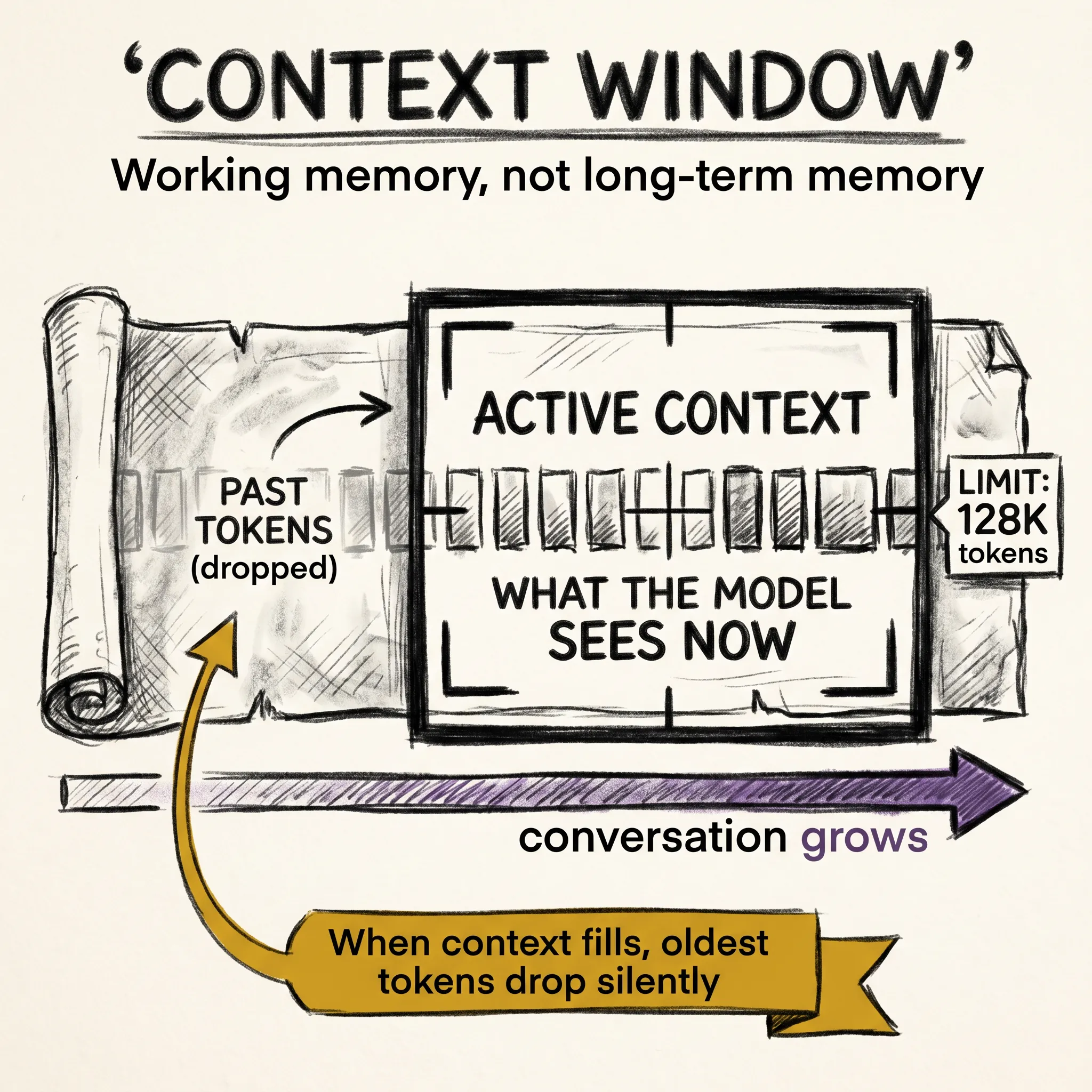
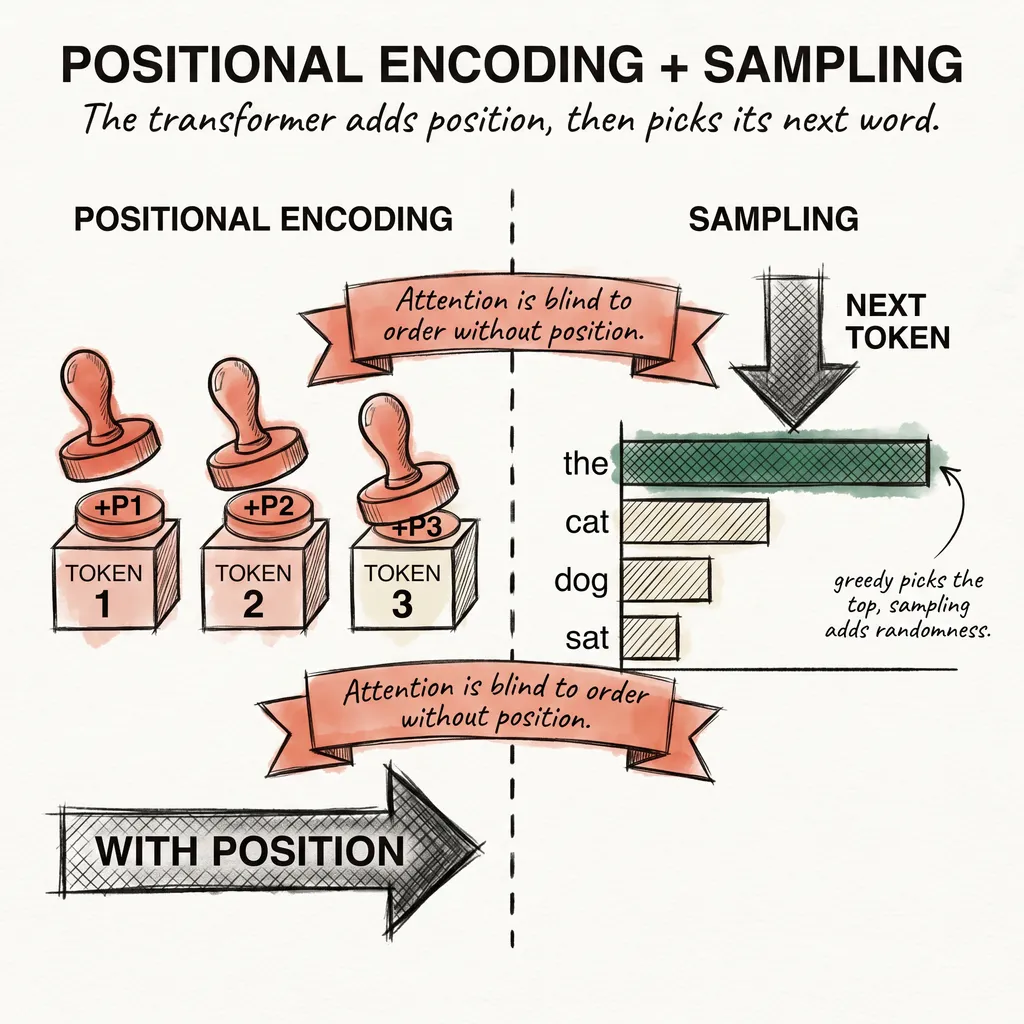
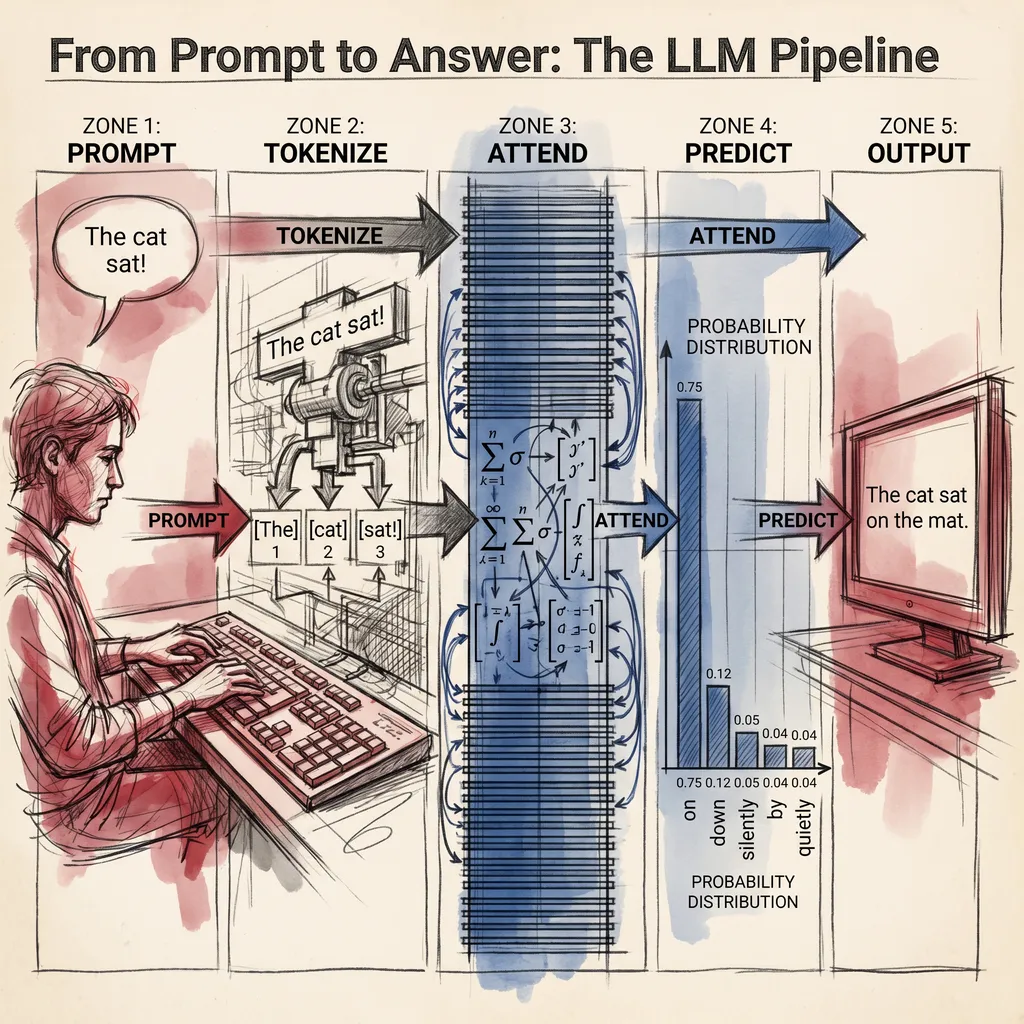
You opened ChatGPT, Claude, or Gemini, typed a question, and got back a paragraph that read like a person wrote it. If that still feels like magic to you, you are not alone. Most people who use these tools every day have no idea what is happening between the typing and the answer.
This series is the part where the magic stops being magic.
Is an LLM just a very fancy parrot, repeating back pieces of its training data in new combinations? Or can it somehow think, and say things about ideas it has never seen before?
Are these systems an example of intelligence, or only the result of a very large pile of math? The answers are not obvious yet. But by the end of the series, I am pretty sure they will be.
WHY I AM WRITING ANOTHER SERIES
I already wrote one long series about AI. From Electricity to AI covered twenty articles, starting with electrons and ending with the frontier labs. It worked.
But when I reread it, I saw something obvious. The LLM parts deserved their own series.
LLMs are moving too fast to be one chapter inside a bigger book. In the last twelve months we got reasoning models that think before they answer. Mixture of Experts architectures broke the old rules about what parameter counts even mean.
MCP arrived as a standard for how models talk to your tools. The 2026 model field has no single winner, which is new.
The first series could not cover these properly without losing its wider arc. So here is the second series. Narrower scope, faster pace, same voice, same signature at the end.
There is also something I noticed in the first series that I want to fix. I covered the big ideas but skipped the practical layer.
How do you actually read a benchmark? How do you pick between a 7B and a 70B model? How do you run your own model on a mini-PC sitting under your desk?
Those questions have concrete answers. I want this series to give them.
WHAT YOU GET
Every article here answers one concrete question that a curious reader would actually ask. The questions are things like: why do models sometimes think 9.11 is larger than 9.9; what does 70B actually cost; when is it worth burning ten times the tokens to let a model think for longer.
The question is the spine of each article. If a paragraph does not push toward the question, it gets cut.
Articles run fifteen hundred to two thousand words each, shorter than the first series on purpose. Read one with your morning coffee and walk away with a single clear idea.
Read one article, learn one thing. That is the deal.
I have a rule for myself with this series. No abstract preambles. No in the evolving world of artificial intelligence openers.
The first paragraph of every article will hook a concrete reader with a concrete problem. If it does not, I rewrite it.
HOW THIS IS DIFFERENT FROM THE FIRST SERIES
From Electricity to AI was broad. It started at voltage and silicon, moved through data centers, networks, processors, and operating systems, and only then got to machine learning and AI. Those twenty articles were a tour of the whole stack that makes AI possible.
Think of the first series like a city map: every street, every district, the full picture. This series is a floor plan of one building. More detail, much smaller scope.

We assume you know that computers run on electricity. We assume you have used ChatGPT, Claude, or Gemini. We assume you know, roughly, that something called a neural network sits behind the chat window. Our job is to open the black box labeled LLM and show you the parts inside.
Some articles will overlap with the first series. Tokens, attention, transformers, context windows, parameters, inference. The first series covered these at moderate depth.
This series covers them again, from a different angle. Instead of asking what is attention, we ask what actually happens between your prompt and the answer. Instead of asking what is a parameter, we ask what does 70B actually mean for speed, cost, and capability.
Each overlapping article links back to its twin in the first series for readers who want the broader context.
The new material is where this series earns its keep. Mixture of Experts, modern alignment with DPO and Constitutional AI, reasoning models, the 2026 model field, benchmarks and how we measure intelligence, quantization, running local models, and Personal AI Infrastructure.
None of those got the treatment they deserved the first time around.
THE MAP
The series runs across five acts plus a short history prologue. Here is the shape of it.
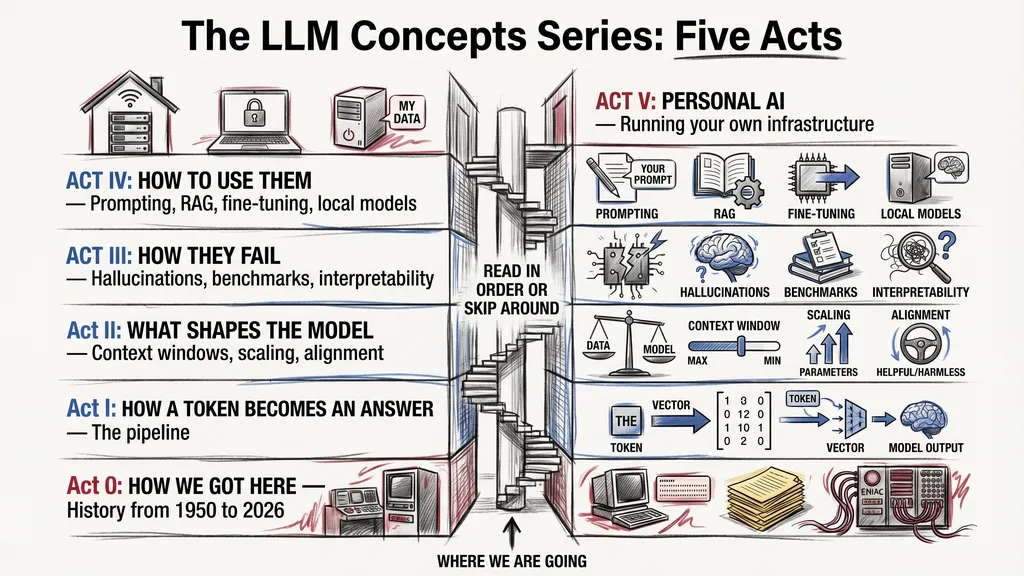
ACT 0. HOW WE GOT HERE. Five articles on the path from the 2017 Transformer paper to the 2026 model lineup, and on the people who matter. If you want to know why a 2017 paper with eight authors keeps getting cited in every announcement since, this is where to look.
ACT I. HOW A TOKEN BECOMES AN ANSWER. Five articles on the pipeline from your prompt to the model’s reply, covering tokens, embeddings, attention, positional encoding, and sampling. Think of this act like opening the hood of a car you have been driving for a year without ever looking inside.
ACT II. WHAT SHAPES THE MODEL. Eight articles on the design choices that decide what a model can and cannot do: context windows, parameter counts, scaling laws, Mixture of Experts, modern alignment, reasoning models, multimodality, and the 2026 model lineup. This is the densest act, and also the one that will age the fastest, which is exactly why I am shipping it first.
ACT III. HOW THEY FAIL AND HOW WE MEASURE THEM. Three articles on the unglamorous side: hallucinations and jailbreaks, benchmarks and the games labs play with them, and interpretability with its honest limits.
ACT IV. HOW TO SHAPE, RUN, AND NAVIGATE. Five articles on the working reader’s toolkit. Prompting and RAG, tool use and MCP, fine-tuning with LoRA, quantization, and running your own model on hardware you own.
ACT V. PERSONAL AI INFRASTRUCTURE. Two closing articles on the shift from using other people’s chatbots to running your own AI. I think this is the direction that matters most for the next five years, and it is where the series pays off.
Twenty-seven articles total. You can read them in order or skip around. The site indexes the whole series at /series/llm-concepts, and every article links to its prerequisites and its follow-ons.
THE HARDER QUESTIONS BEHIND IT ALL
The technical content is the spine, but I want to be honest about what is really interesting. A lot of what you hear about LLMs in 2026 arrives as certainty, in both directions.
People on one side say these are just stochastic parrots, statistical autocomplete with good PR. People on the other side say we are one or two releases away from artificial general intelligence.
Both of those positions are louder than the evidence supports.
The actual questions are harder and more interesting. When a model answers something it has never literally seen in its training data, what is that? When it reasons through a math problem it has never been shown, is that thinking, or just a very rich pattern-matcher dressed up in new clothes? When it refuses a request, is that a real value, or a trained surface behavior on top of a completely amoral prediction engine?
I will keep coming back to these questions across the series, with a little more evidence each time.
My honest position, for the record: I think LLMs are genuinely more than parrots, and genuinely less than intelligent agents (still) in the way humans are. Most of the interesting argument is about exactly where on that line the current models sit, and that line keeps moving. I would rather give you the tools to think about it than give you my conclusion and move on.
WHO THIS IS FOR
The target reader is someone who uses these tools and wants to know how they work. Not a researcher. Not a student starting from zero on computers. Someone in the middle.
If you have written a few prompts, wondered why the model gave a weird answer, thought about running a local model but never actually did it, and want to understand the field well enough to read announcements without getting fooled, this is for you.
If you are a specialist already, you will find some articles too introductory. That is fine. The cross-connections matrix at the start of each article tells you whether you can skip it. Use it.
Honestly, I am also writing this for myself. The best way I know to learn something is to explain it to someone else. Twenty-seven articles will force me to actually understand Mixture of Experts instead of pretending I do.
Yes, AI is helping me write this series. New reality. But here I am, proving I am behind the keyboard driving this series: “intentionally eorroresdf statemenent none llm would ever do” :P
WHAT IS COMING NEXT
This is the first article. The next covers a short history of machines that read, from the 1950 Turing paper to the moment just before Transformers arrived in 2017.
After that, one article at a time.
I am writing it short on purpose. The 2026 AI world will look materially different in six months. A three-month series ships while the content is still accurate. A six-month one ships half of it into a field that has already moved on without us.
One last note, about tone. The focus here is knowledge, not my views. But occasionally I will share how I see something, gently, when it helps frame the topic. Not often.
That is the series. The next article is a short history of machines that read. After that, we get into the details.
T.
References
- Attention Is All You Need (Vaswani et al., 2017) - The 2017 Google Brain paper that introduced the Transformer architecture and kicked off the modern LLM era.
- From Electricity to AI series - The broader companion series on this blog covering the physical and software foundations under AI.
- On the Dangers of Stochastic Parrots (Bender et al., 2021) - The paper that popularised the stochastic parrot framing referenced in the Harder Questions section.
- Personal AI Infrastructure (Daniel Miessler) - The thesis that this series ends on, covering why running your own AI is a posture and not a product.
- Chinchilla scaling laws (Hoffmann et al., 2022) - The compute-optimal training paper that reshaped how we think about model size versus training data, covered in Act II.