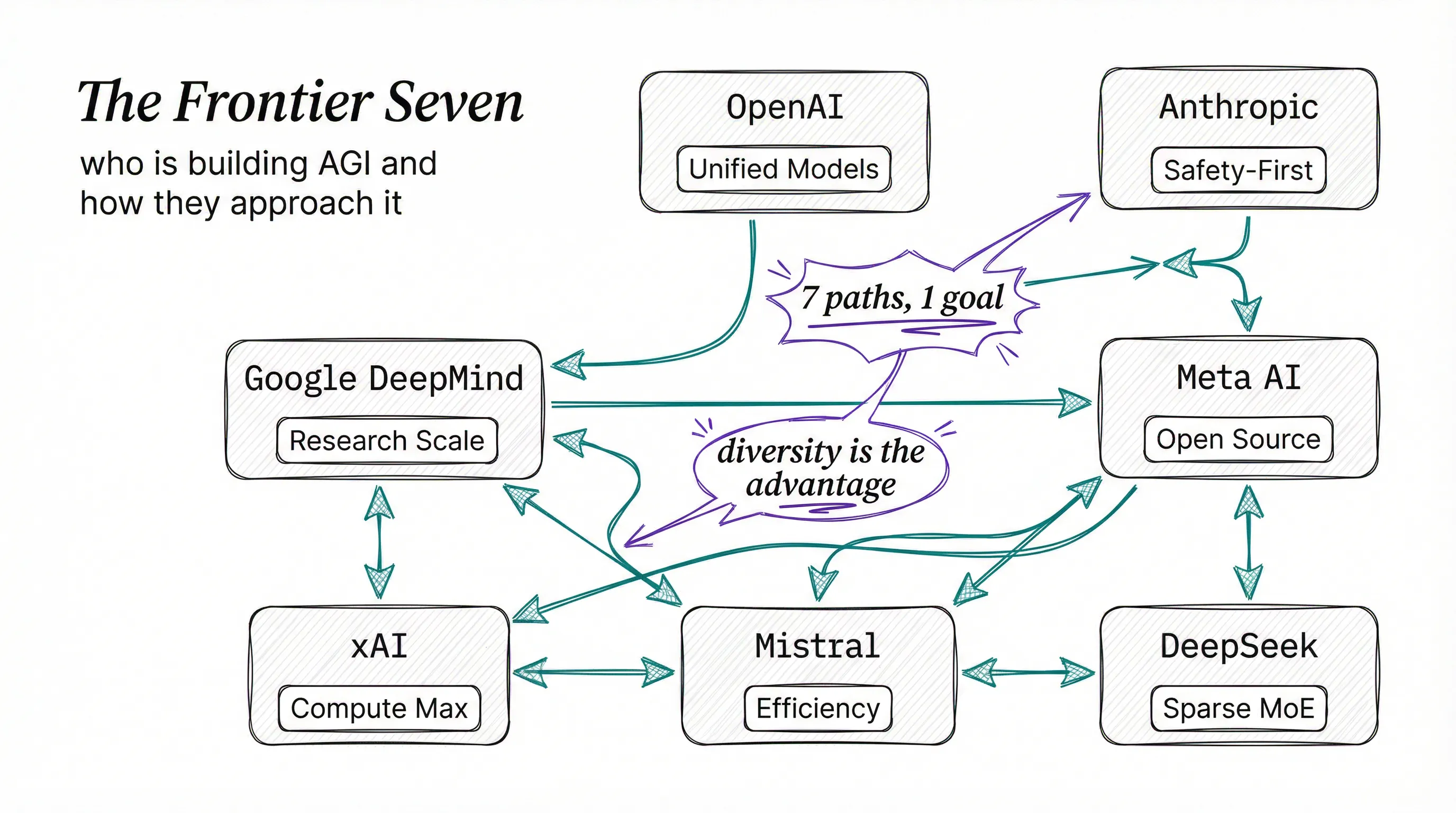
Seven companies are spending billions of dollars, burning through megawatts of electricity, and hiring the best researchers on Earth to build the most powerful AI systems ever created. Each one has a different theory about how to get there.
Some prioritize scale. Others bet on architecture. A few believe safety is the path forward, not an obstacle to it.
This is who they are and what they’re doing right now.

THE RACE.
A year ago, the frontier model scene looked manageable. A handful of players traded benchmark leads every few months. In 2025 and early 2026, the race became something else entirely.
Model releases now happen in waves. A new state-of-the-art benchmark result lasts weeks, not months. Training clusters have grown from thousands of GPUs to hundreds of thousands, and the capital requirements have ballooned into the tens of billions.
What strikes me most isn’t the speed, it’s that each lab has developed a genuinely distinct philosophy about how intelligence should be built. The models coming out of OpenAI look nothing like what Anthropic produces, which looks nothing like what DeepSeek ships. Same goal, radically different paths, and honestly? That’s the most exciting part.
OPENAI: THE INCUMBENT.
OpenAI remains the company everyone else measures themselves against, and they’ve been busy. In April 2025, they released o3 and o4-mini, reasoning-focused models that think before they respond.
These were the first OpenAI reasoning models that could combine every tool in ChatGPT at once: web search, Python execution, image generation, file analysis.
The o3 model made 20% fewer major errors than o1 on difficult real-world tasks, with particular strength in programming and consulting scenarios. The o4-mini variant optimized for speed and cost while still posting the best benchmarked scores on AIME 2024 and 2025 math competitions.
Then in August 2025, GPT-5 arrived and unified everything. Rather than maintaining separate model families for reasoning and general use, GPT-5 merged them into a single architecture, replacing GPT-4o, o3, o4-mini, and earlier variants as the default for signed-in users.
The benchmarks were staggering: near-95% on AIME 2025 without tools, 75% on SWE-bench Verified, 88% on Aider Polyglot. By early 2026, the model had iterated to GPT-5 point 2 with extended thinking and multiple size variants.
OpenAI’s strategy is clear: unify everything into one model that can do it all. Reasoning, multimodal understanding, tool use, code generation, one system. It’s brute-force integration, and so far it’s working.
ANTHROPIC: THE SAFETY-FIRST BUILDER.
Anthropic believes you build the most capable models precisely because you take safety seriously, not in spite of it. Founded by former OpenAI researchers Dario and Daniela Amodei, Anthropic developed Constitutional AI as its core training methodology.
Instead of relying solely on human feedback to steer behavior, they train models against a written constitution of principles, letting the AI self-improve within guardrails.
In January 2026, Anthropic published a new constitution for Claude, shifting from rule-based to reason-based alignment. Instead of telling the model “don’t do X,” the constitution explains why certain behaviors matter and establishes a four-tier priority hierarchy: safety, ethics, compliance, helpfulness.
The models have been exceptional. Claude Opus 4.5, released November 2025, cut tool calling errors and build errors by 50 to 75 percent.
Opus 4.6 followed in February 2026 as the world’s best model for coding, enterprise agents, and professional work.
METR estimated its task-completion time horizon at 14 hours and 30 minutes, meaning it can work autonomously on complex problems for over half a day. In one experiment, 16 Opus 4.6 agents wrote a C compiler in Rust from scratch that could compile the Linux kernel. That experiment cost nearly $20,000, which tells you something about both the model’s capability and the economics of frontier AI.
Sonnet 4.6, also released February 2026, brought a first: a Sonnet model preferred over the previous generation’s Opus in coding evaluations. Anthropic also introduced “Infinite Chats” to eliminate context window limits, with 1M token context windows across both model lines.
Anthropic’s safety research is the most underrated part of the story. Their constitutional classifiers defend against universal jailbreaks with only a 0.38% increase in refusal rates. Safety doesn’t come at the cost of usefulness here, and that’s a compelling argument that responsible development and frontier capability aren’t opposites.
GOOGLE DEEPMIND: THE RESEARCH POWERHOUSE.
If any organization has the raw research firepower to reach AGI, it’s Google DeepMind. They have the compute, the talent (absorbing both the original DeepMind and Google Brain teams), and the distribution. Every Google product is a deployment channel, and their Gemini model family reflects that advantage.
Gemini 2.5 Pro leads both the WebDev Arena and LMArena leaderboards by significant margins. The Deep Think reasoning mode achieved gold-medal standard at the International Mathematical Olympiad. A subsequent release hit Bronze-level on the 2025 IMO benchmark while being faster and more practical for daily use.
That tradeoff tells you a lot about Google’s priorities: they care about peak performance, but they care more about usable performance.
Google’s Flash lineup targets efficiency. Flash serves as the workhorse for speed and low cost, while Flash-Lite offers the lowest latency in the family. At Google I/O 2025, Flash became the default model, a signal that Google sees the frontier not just in raw intelligence but in making intelligence cheap and fast enough to embed everywhere.
By March 2026, Google had moved to Gemini 3.1 Flash Lite for developers, with Gemini 3.1 Pro Preview in the pipeline. They’re also pushing into native audio output, advanced security safeguards against prompt injection, and Project Mariner’s computer use capabilities.
Google’s unique advantage is breadth. AlphaFold changed biology. Gemini powers search, Gmail, Docs, and Android. No other lab can deploy a model to two billion users overnight.
META AI: THE OPEN-SOURCE GAMBIT.
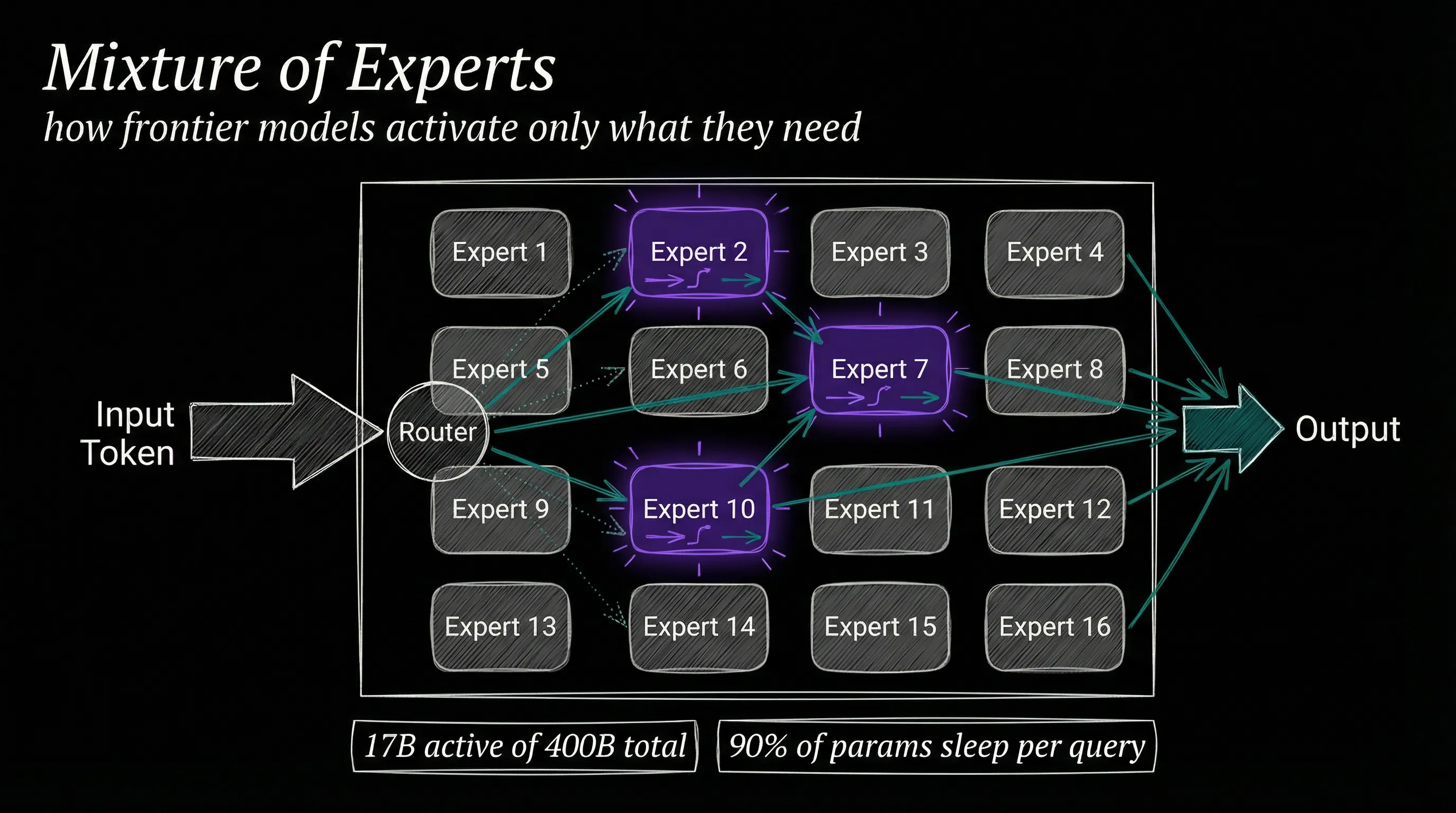
Meta’s strategy is the most interesting bet at the table. I say that as someone who has watched plenty of companies try to compete by giving things away for free. With Llama 4, released April 2025, Meta shipped the first open-weight natively multimodal models using a mixture-of-experts architecture.
Scout runs 17 billion active parameters with 16 experts (109B total) and supports a 10 million token context window. Maverick uses 17 billion active parameters with 128 experts (400B total) and a 1 million token context window.
Read those numbers again. A 10 million token context window on an open model, like loading the entire American tax code into memory at once.
Meta announced but hasn’t released Behemoth, a 288 billion active parameter model with roughly 2 trillion total parameters that was still training at launch.
Why give this away? Because Meta doesn’t sell AI models. It sells advertising. Every developer who builds on Llama instead of paying OpenAI or Google strengthens Meta’s ecosystem.
Every company that deploys Llama on-premises rather than using a cloud API is one more reason the AI layer stays commoditized while Meta’s data advantage compounds.
The open-source approach has another effect: it makes everyone else’s moat shallower. If a free model achieves 90% of GPT-5’s capability, the pricing pressure on closed-source providers gets enormous fast.
XAI: THE COMPUTE MAXIMALIST.
Elon Musk’s xAI takes the most straightforward approach to the AGI race: throw unprecedented compute at the problem. In February 2025, xAI released Grok 3, a 3-trillion parameter mixture-of-experts model trained on 12.8 trillion tokens. It surpassed DeepSeek-V3 and GPT-4o in mathematics, science, and coding benchmarks at launch.
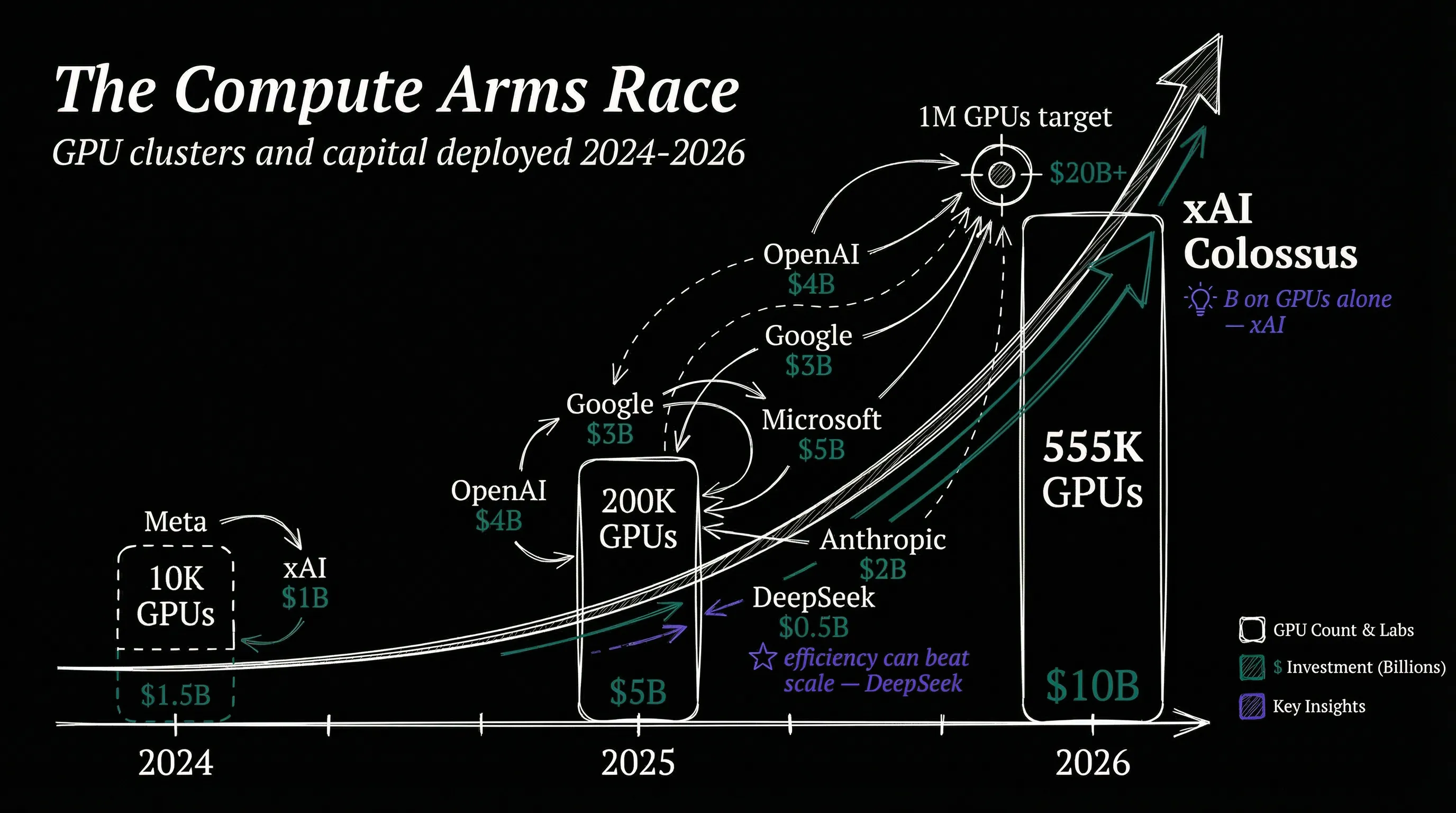
But the real story is the infrastructure. Colossus, xAI’s training cluster in Memphis, Tennessee, started with 100,000 Nvidia GPUs built in 122 days. By early 2025 it doubled to 200,000. By January 2026, Musk announced expansion to 555,000 GPUs at 2 gigawatts total capacity, purchased for approximately $18 billion.
A third facility nicknamed “MACROHARDRR” (I’m not making this up) targets 1 million GPUs by late 2026.
The models progressed fast: Grok 3 in February 2025, then iterations through Grok 4.1, with Grok 5 slated for early 2026 featuring a rumored 6-trillion parameter architecture. Musk has claimed a 10% probability that Grok 5 represents the world’s first AGI, which is either bold or delusional depending on your priors.
xAI’s thesis is simple: intelligence scales with compute, and whoever has the most compute wins. It’s an expensive hypothesis to test. Eighteen billion on GPUs alone is the kind of bet that either looks visionary or catastrophically wasteful in hindsight. I know which way I’m leaning, but I’ve been wrong before.
MISTRAL: EUROPE’S CONTENDER.
Mistral AI has quietly become the most important AI company in Europe and possibly the most efficient frontier lab per dollar spent. In December 2025, they released the Mistral 3 family: three dense models (3B, 8B, and 14B parameters) plus Mistral Large 3.
Large 3 is their first mixture-of-experts model since the original Mixtral, with 41 billion active and 675 billion total parameters. They trained it from scratch on 3,000 of Nvidia’s H200 GPUs, and it achieves parity with the best open-weight instruction-tuned models while excelling at multilingual conversations and image understanding.
The Ministral 3 series targets edge and local deployment with base, instruct, and reasoning variants. Devstral 2 and Devstral Small 2 (24B parameters) focus on coding, claiming better performance than Qwen 3 Coder Flash at 30B.
Having raised 11.7 billion euros, Mistral operates within Europe’s regulatory environment and has turned transparency into a feature rather than a constraint. Their models punch above their parameter count, which matters when your competitors outspend you ten to one on training runs.
DEEPSEEK: THE EFFICIENCY REVOLUTION.
No discussion of frontier AI in 2025 is complete without DeepSeek. The Chinese lab sent shockwaves through the industry in January 2025 when it released a frontier reasoning model that nearly matched America’s best closed models at a fraction of the cost.
The implication landed hard: maybe you didn’t need $100 billion and a million GPUs to build competitive AI.
DeepSeek’s approach relies on sparse mixture-of-experts architectures that activate only a fraction of total parameters per token, delivering strong performance with far less compute. Their V4 model, expected in early March 2026, reportedly reaches a trillion parameters total while targeting 1 million token context length, optimized for coding and long-context software engineering.
The geopolitical angle is hard to ignore. DeepSeek built V4 in collaboration with Chinese chipmakers Huawei and Cambricon, explicitly reducing reliance on U.S.-made semiconductors.
Since DeepSeek’s R1 release, Alibaba, Tencent, Moonshot AI, and Zhipu AI have all accelerated their own model development. China’s AI ecosystem is not waiting for permission.
DeepSeek proved something that Silicon Valley didn’t want to hear: efficiency can beat scale. You don’t need the biggest cluster if you have the smartest architecture. That insight has influenced every lab’s research agenda, whether they admit it or not.
THE PATTERNS.
Step back and a few themes emerge.
First, mixture-of-experts has won the architecture debate. OpenAI, Meta, xAI, Mistral, and DeepSeek all ship MoE models. Activating only a fraction of a model’s total parameters per query turns out to be the key to making massive models economically viable.
Second, reasoning models are becoming the norm. OpenAI’s o-series, Google’s Deep Think, and various chain-of-thought approaches have shown that models which think before responding produce dramatically better results on hard problems.
Third, context windows have exploded. A year ago, 128K tokens felt generous. Now Meta offers 10 million, several labs support 1 million, and the trend keeps pushing upward. Longer context means models can work with entire codebases, full document sets, and sustained multi-hour tasks.
Fourth, the cost curve bends downward. DeepSeek showed efficiency matters. Mistral showed you can compete without Google-scale budgets. Even OpenAI and Google ship smaller, cheaper model variants alongside their flagships.
WHERE THIS GOES.
Seven labs. Hundreds of billions of dollars. Thousands of the world’s best researchers. Each pursuing a slightly different theory of intelligence.
Some of these companies will merge, pivot, or fail. This funding level is not sustainable forever. But the diversity of approaches is good news.
If there’s only one path to general intelligence, having seven well-funded teams exploring different routes maximizes the chance someone finds it. And if there are multiple paths, we might end up with fundamentally different kinds of intelligent systems, each with their own strengths.
The race to AGI is not a single sprint. It’s seven different marathons being run simultaneously, on seven different courses, with seven different finish lines. The only thing the runners agree on is that they’re heading somewhere no one has been before.
T.
References
-
Introducing OpenAI o3 and o4-mini - OpenAI’s April 2025 announcement of their reasoning-focused models with multimodal tool use capabilities and benchmark results across math and coding tasks.
-
Introducing GPT-5 - OpenAI’s August 2025 release of GPT-5, unifying reasoning and general-purpose capabilities into a single model with state-of-the-art performance across math, coding, and multimodal understanding.
-
Claude Model Overview - Anthropic’s documentation on their February 2026 model releases, covering autonomous task capabilities and context windows.
-
Google I/O 2025: Gemini Updates from DeepMind - Google’s overview of Gemini Pro performance, Deep Think reasoning, and the Flash model family.
-
The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal AI Innovation - Meta’s April 2025 announcement of Llama 4 Scout and Maverick, the first open-weight multimodal mixture-of-experts models with up to 10M token context windows.
-
xAI Colossus Hits 2 GW: 555,000 GPUs - Technical analysis of xAI’s expansion of the Colossus supercomputer to 555,000 GPUs at 2 gigawatts, the largest single-site AI training installation in the world.
-
Introducing Mistral 3 - Mistral AI’s December 2025 release of the Mistral 3 family including Large 3 (675B total MoE parameters) and the Ministral 3 series for edge deployment.
-
DeepSeek’s Release of an Open-Weight Frontier AI Model - IISS analysis of DeepSeek’s impact on the frontier AI scene, including the efficiency implications and geopolitical dimensions of Chinese AI development.


