In the previous article, “AI Training: How Models Get Smart,” we explored how neural networks learn through gradient descent, backpropagation, and reinforcement learning from human feedback. Training is the hard part, right? You gather petabytes of data, burn through thousands of GPUs for months, and eventually produce a model that knows things.
But here is the question nobody talks about enough: what happens when you actually need to use it?
WHAT INFERENCE ACTUALLY IS.
Training teaches the model. Inference is the model doing its job. Every time you ask Claude a question, every time Gemini summarizes your email, every time Llama autocompletes a sentence on your laptop: that is inference. If training is the education, inference is the career.
Think of training as culinary school. Years of study, practice, failure, learning. Inference is opening night at the restaurant and every night after.
The chef is not learning anymore. The chef is cooking, and the kitchen better keep up.
Orders come in continuously, each one needs to come out fast and consistent, and the restaurant needs to stay profitable. Sound familiar? That is the exact same pressure hitting every AI company on earth right now.
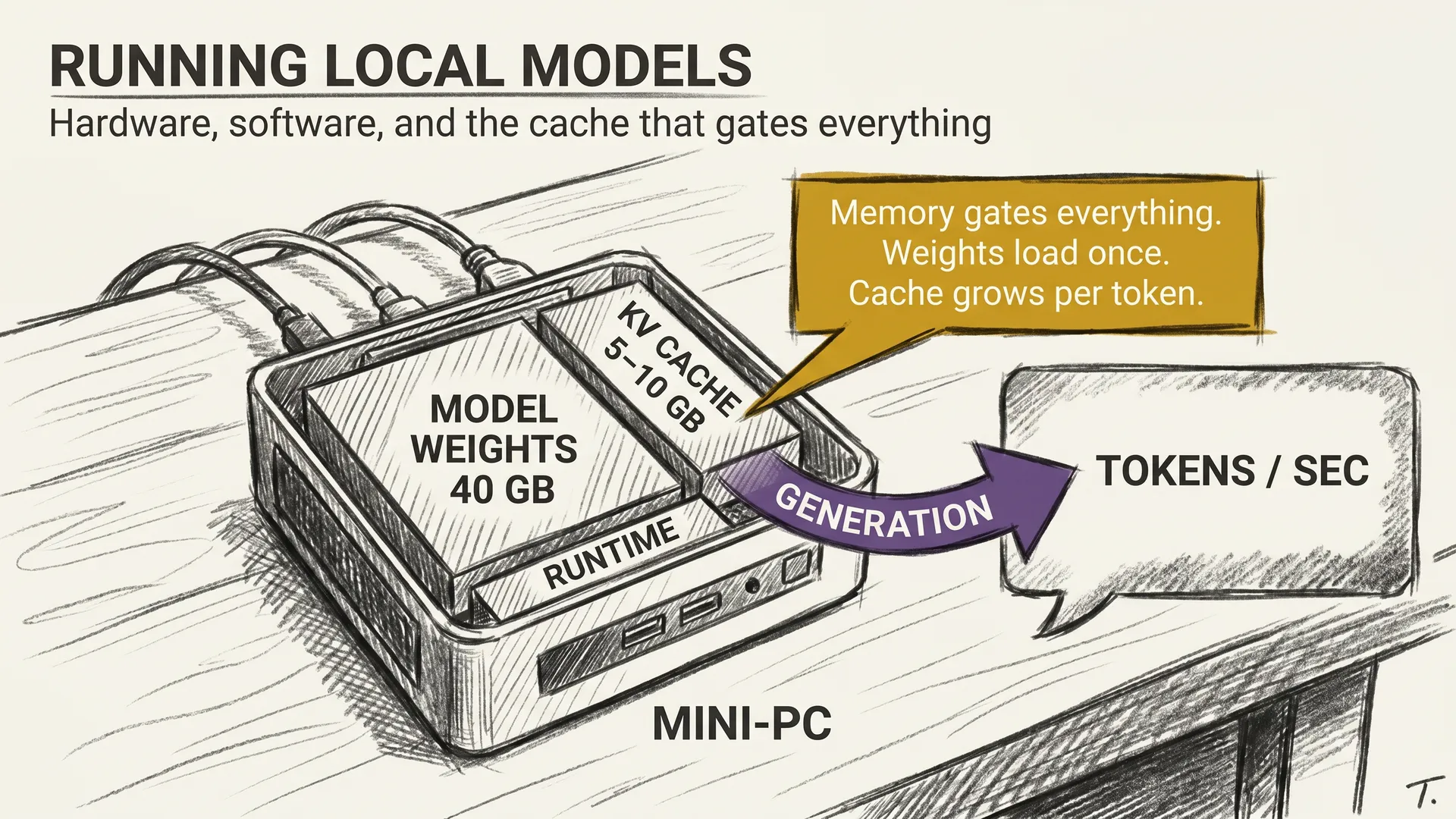
A trained model sits as a file on disk, a collection of billions of numerical weights frozen in place. Inference loads those weights into GPU memory and runs a forward pass, pushing input data through the network to produce output.
During training, the model adjusts weights after every batch. During inference, the weights never change. This distinction matters because it completely changes the engineering problem: training optimizes for learning speed, inference optimizes for serving speed and cost per query. Same model, totally different game.
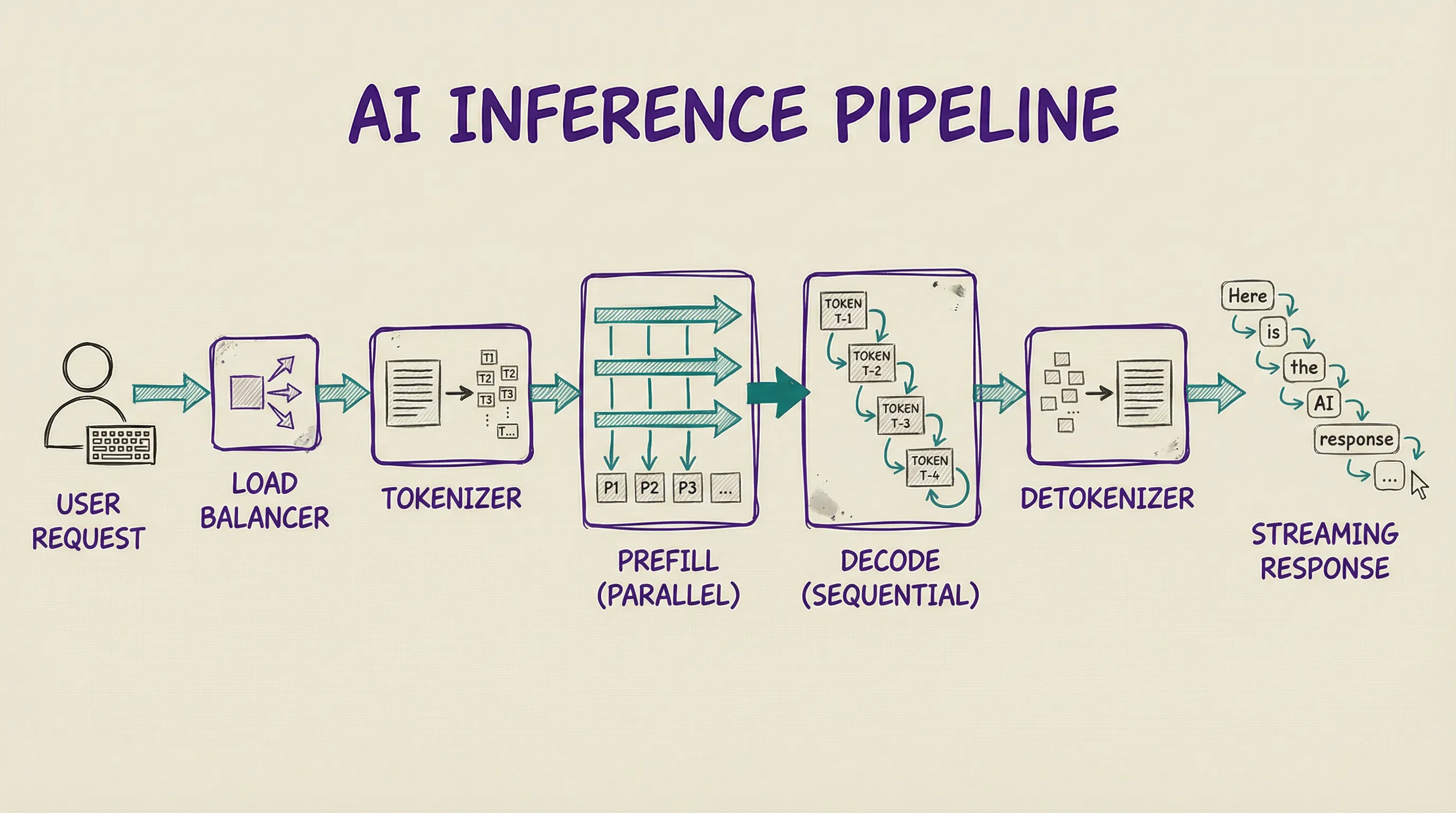
THE INFERENCE PIPELINE.
When you send a message to Claude or Gemini or Mistral, the request follows a specific path. A load balancer receives your HTTPS request and routes it to an available GPU server. A tokenizer then converts your text into token IDs that the model understands.
Next comes the prefill phase, which processes all your input tokens in parallel through a single forward pass. A 1,000-token prompt takes roughly the same time as a 500-token prompt because the transformer handles them simultaneously.
I genuinely love this part of the architecture. It is one of the rare moments where “bigger” does not automatically mean “slower.”
After prefill, the decode phase begins, and this is where things slow down. The model generates output tokens one at a time, each requiring its own forward pass. A detokenizer converts the output back to text, and tokens stream to your browser as they appear.
This is why AI responses look like someone typing them out in real time. Each token takes 30 to 100 milliseconds to generate. The prefill phase runs parallel and fast, the decode phase runs sequential and slow. It is like a sprinter who finishes the 100-meter dash, then has to walk a marathon.
MAKING INFERENCE FAST.
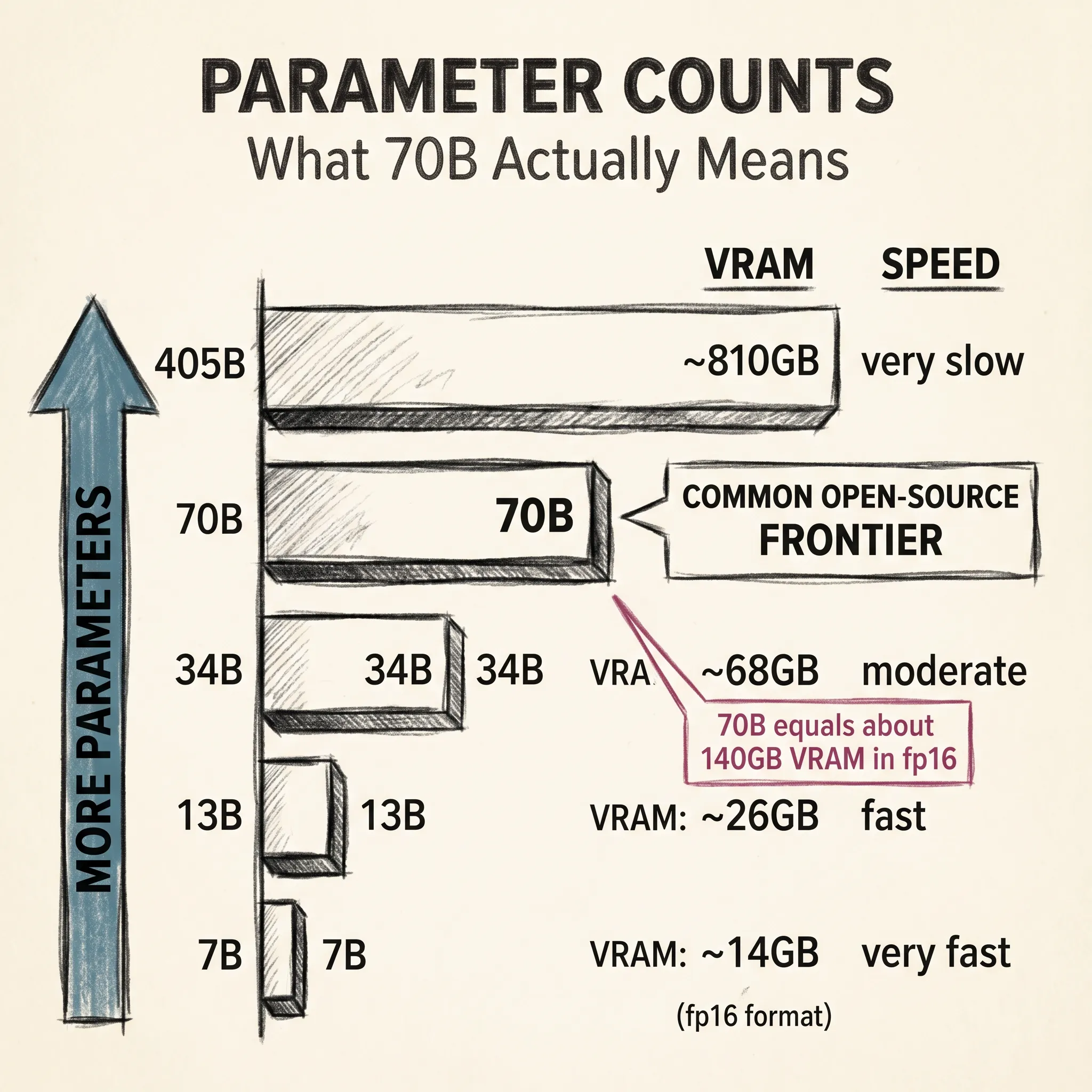
Raw model inference is brutally expensive for production. A 70-billion parameter model at full 16-bit precision needs 140 GB of GPU memory just to hold the weights. That is nearly two entire H100 GPUs doing nothing but storing numbers. Several techniques make large-scale serving practical.
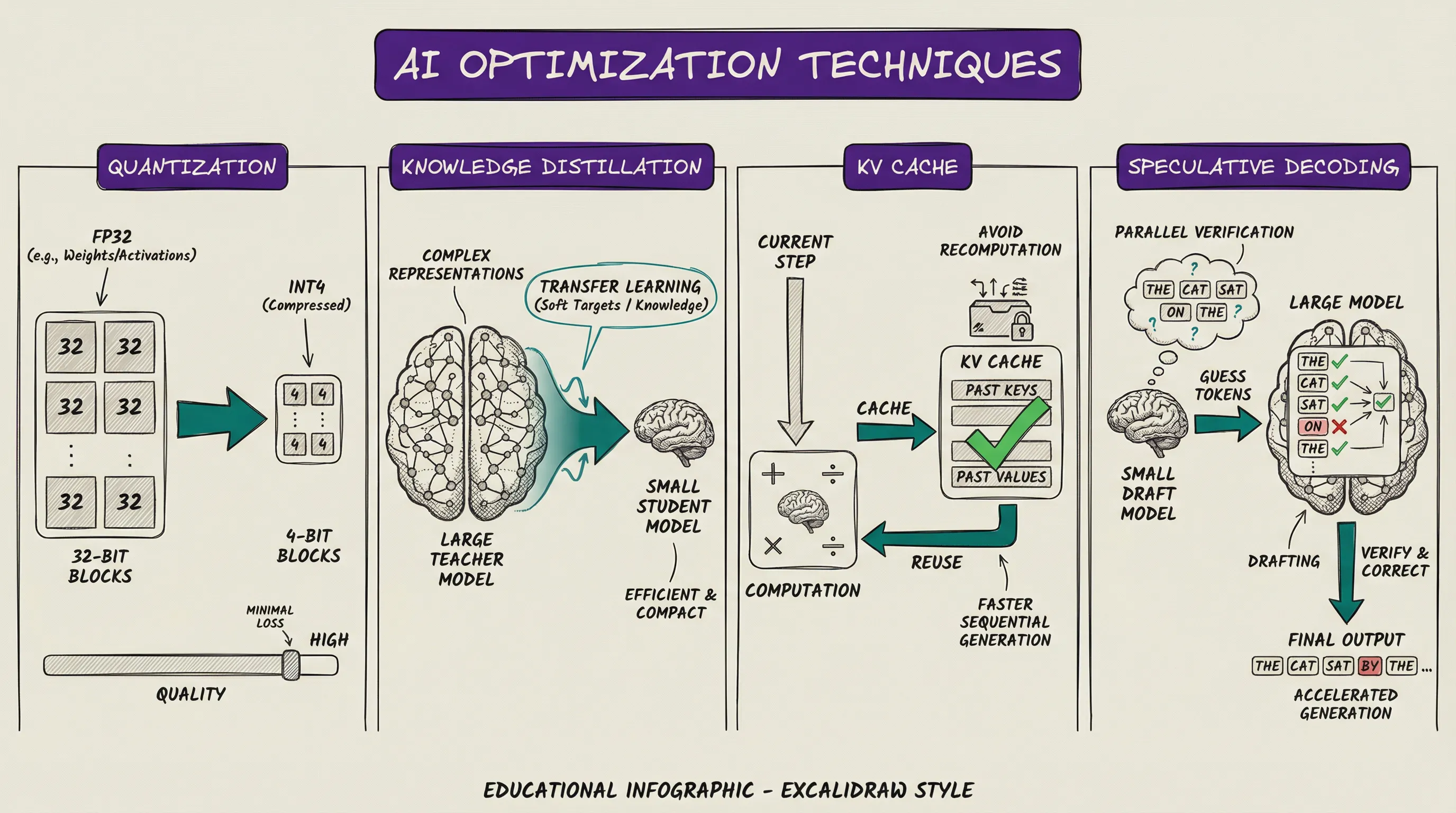
Quantization reduces the numerical precision of model weights. Training uses 32-bit or 16-bit floating-point numbers, but quantization converts those to 8-bit or even 4-bit integers. Think of it like compressing a high-resolution photo: you lose a little detail, but the file shrinks dramatically.
A 70B model drops from 140 GB to 70 GB at 8-bit, or 35 GB at 4-bit. The quality loss at 8-bit typically lands around 1 to 2 percent. This is why you can run a quantized Llama 3 70B on a single consumer GPU instead of a multi-GPU server.
Knowledge distillation trains a smaller student model to mimic a larger teacher model. The student learns from the teacher’s outputs rather than from raw training data. Anthropic’s Claude Haiku, Google’s Gemini Flash, and Meta’s smaller Llama variants all follow this philosophy: trade some capability for dramatically lower inference cost. It is the engineering equivalent of hiring a capable junior who watched the senior for a year.
The KV cache stores intermediate computation results during token generation. Without it, generating the 100th token recomputes attention across all 100 previous tokens from scratch. With the cache, only the new token’s attention needs computing, cutting computation by 10x to 100x for long responses.
The trade-off is memory. For large models with long context windows, the KV cache can consume more GPU memory than the model weights themselves. You save compute but pay in RAM. Every optimization in this field is a trade-off like that.
Speculative decoding uses a small, fast draft model to guess several tokens ahead, then the large model verifies them in a single forward pass. If the draft model gets three out of four tokens right, you generate four tokens in the time it normally takes to generate two.
Most tokens in natural language are predictable. “The capital of France is” does not require a 400-billion parameter brain. The draft model handles the easy ones while the large model focuses on the hard calls.
SCALING TO BILLIONS.
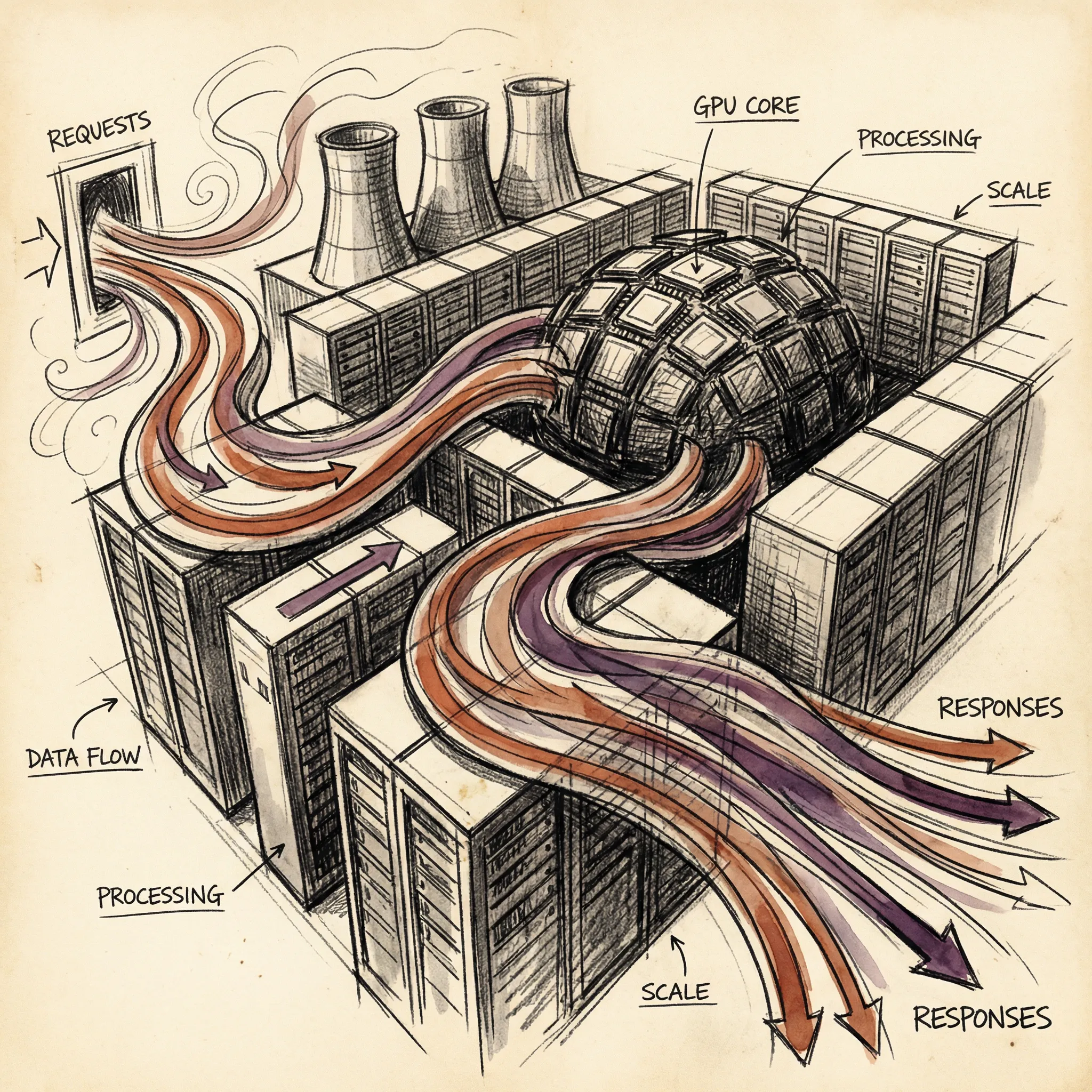
Serving one user is straightforward. Serving billions of daily queries across Claude, Gemini, GPT-4, Llama-based services, and dozens of other models? That requires infrastructure that would make a traditional web engineer sweat.
Continuous batching groups multiple requests together on the same GPU. Instead of processing one request at a time, the server handles 32 or 64 simultaneously. Think of it as a grill cook working 20 burgers at once instead of flipping one, waiting, then starting the next.
New requests join the active batch as they arrive, and finished requests leave without stalling the others. The GPU stays maximally utilized, which is critical because idle GPU time is just money burning.
Load balancers distribute traffic across thousands of GPU servers in multiple data centers. They route based on server capacity, geographic proximity, model version, and customer priority. It is air traffic control for math.
Frontier models do not fit on a single GPU. A 400-billion parameter model at 16-bit precision needs over 800 GB of memory, but a single H100 has 80 GB. You cannot cheat physics.
Tensor parallelism splits layers across multiple GPUs. Pipeline parallelism splits the model by layer groups.
A single inference server for a frontier model might use 8 H100s connected by NVLink, and thousands of these servers handle the full user base. The coordination involved is staggering.
EDGE INFERENCE VS CLOUD INFERENCE.
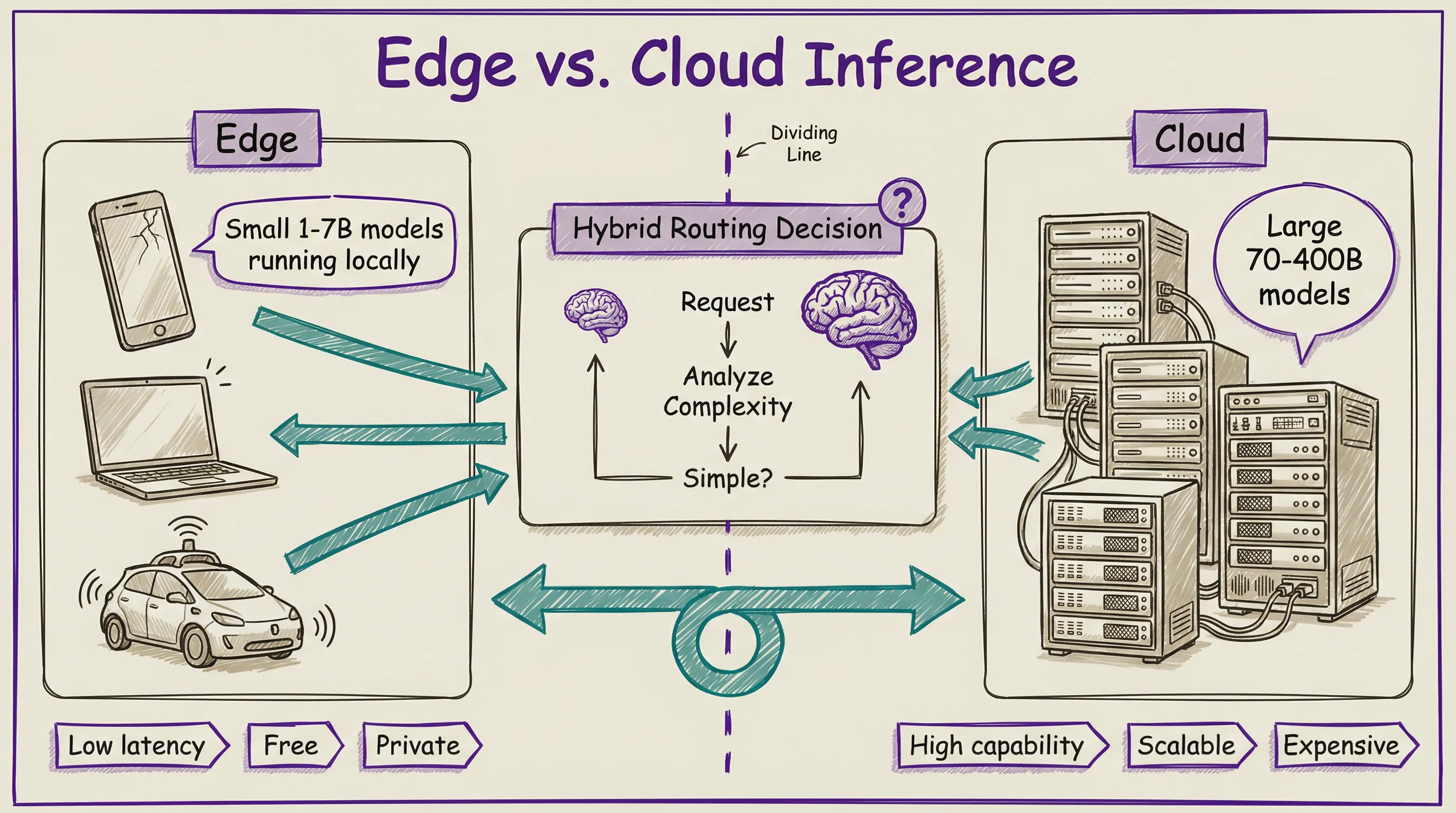
Not all inference happens in data centers. Edge inference runs models directly on user devices: phones, laptops, cars, IoT sensors. The appeal is obvious: zero network latency, zero cloud cost, total privacy.
Apple’s Neural Engine handles Siri, photo processing, and predictive text locally on your iPhone. Google runs Gemini Nano on Pixel phones for summarization and smart replies. Meta has optimized Llama for mobile deployment.
Your phone is already an AI inference machine, and you might not even realize it.
No internet required, no cloud bill, no round trip to some data center in Virginia. The limitation is equally obvious: edge devices have limited compute and memory, so they run small models in the 1 to 7 billion parameter range.
The trend is hybrid. Simple tasks run locally for speed and privacy. Complex tasks route to the cloud for power.
Your phone decides which path to take, and you probably never notice the handoff. It is like having a local mechanic for oil changes and a specialist shop for engine rebuilds.
THE ECONOMICS OF INFERENCE.
Here is the number that matters most: inference accounts for roughly 80 percent of all AI computation. Training gets the headlines. Inference gets the electricity bill. Let that sink in.
Output tokens cost 4 to 5 times more than input tokens across every major provider. Why? Output requires sequential generation while input processes in parallel.
The slow part costs more. Always does.
This cost structure drives real product decisions. Free tiers use smaller, cheaper models. Prompt engineering reduces token count, directly cutting cost. Response caching stores answers for common queries so the model does not recompute them.
I find the economics genuinely fascinating because they explain every AI product quirk you encounter. Why does your free-tier chatbot feel slower during peak hours? The inference servers hit capacity, and your request waits in a queue.
Why do companies offer multiple model sizes? Because the smallest model that meets quality requirements is the most profitable to serve.
And why is local AI growing so fast? A quantized 7B model on your laptop costs zero per query after download. That is a pricing strategy no cloud provider can beat.
The companies that win the inference efficiency race will win the AI market. Training a great model is table stakes. Serving it to billions of people at a sustainable cost is the actual business.
WHAT COMES NEXT.
We have now covered the full AI stack: machine learning in Article 11, neural networks in Article 12, LLMs in Article 13, training in Article 14, and inference here. You understand how AI works from first principles, from electricity to a running model serving real users. That is not a small thing.
Next up: “The Frontier Labs: Who Is Building AGI.” We will look at the companies behind all of this, their strategies, their resources, and what their competition means for the future.
T.
References
-
vLLM: Easy, Fast, and Cheap LLM Serving - Open-source inference engine with continuous batching and PagedAttention for high-throughput serving.
-
GPTQ: Accurate Post-Training Quantization (Frantar et al, 2022) - Compressing large models to lower precision with minimal quality loss
-
Speculative Decoding (Leviathan et al, 2022) - The draft-then-verify approach that accelerates autoregressive generation
-
PagedAttention for LLM Serving (Kwon et al, 2023) - KV cache memory management powering modern inference servers