Tag: inference
All the articles with the tag "inference".
-
 llm-concepts8 min read
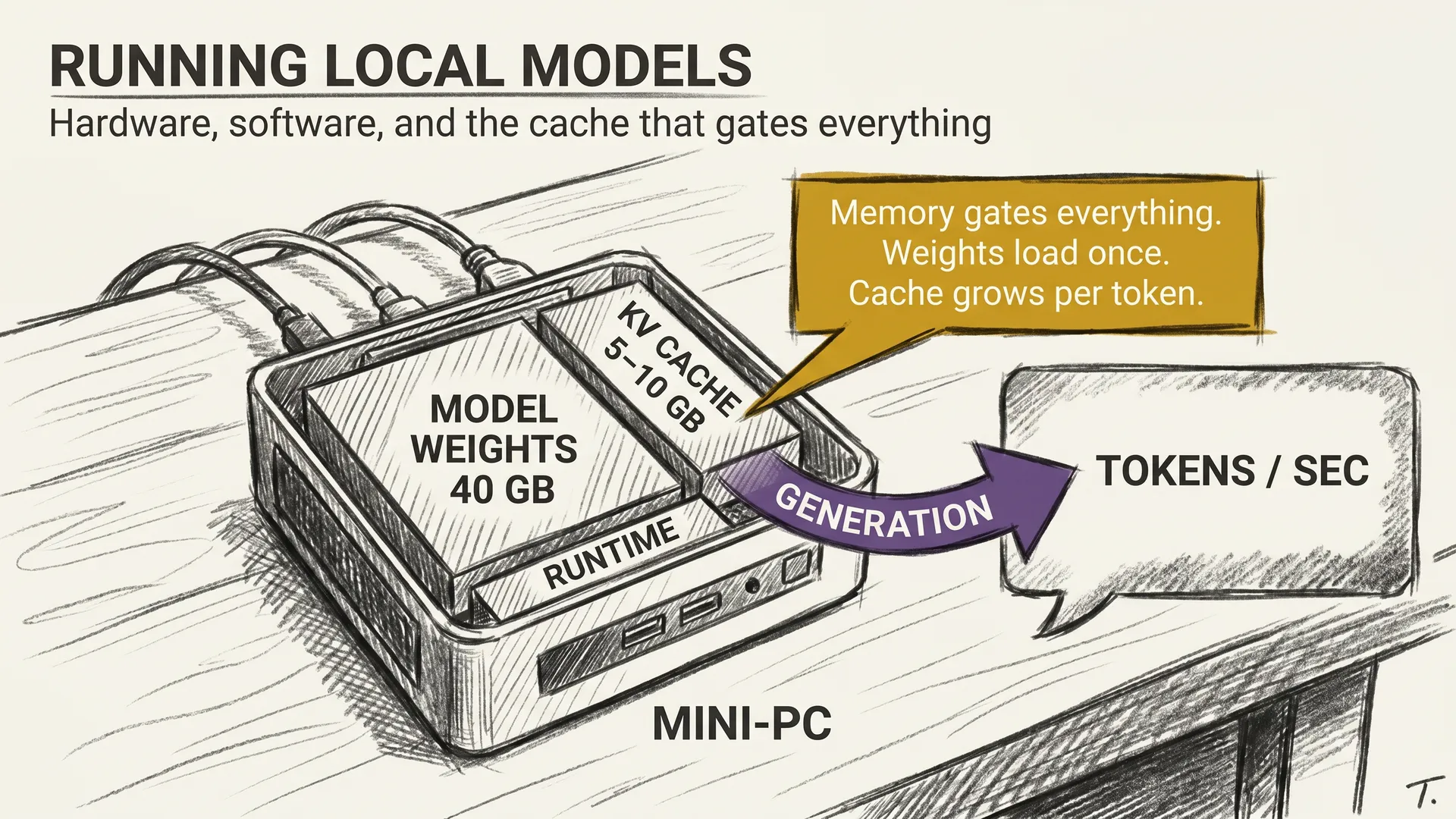
llm-concepts8 min readRunning Local Models: What It Actually Takes
Quantization shrank the model down to 40 GB. Now what hardware, what software, and what setup actually run a 70B model at home in 2026?
-
 llm-concepts7 min read
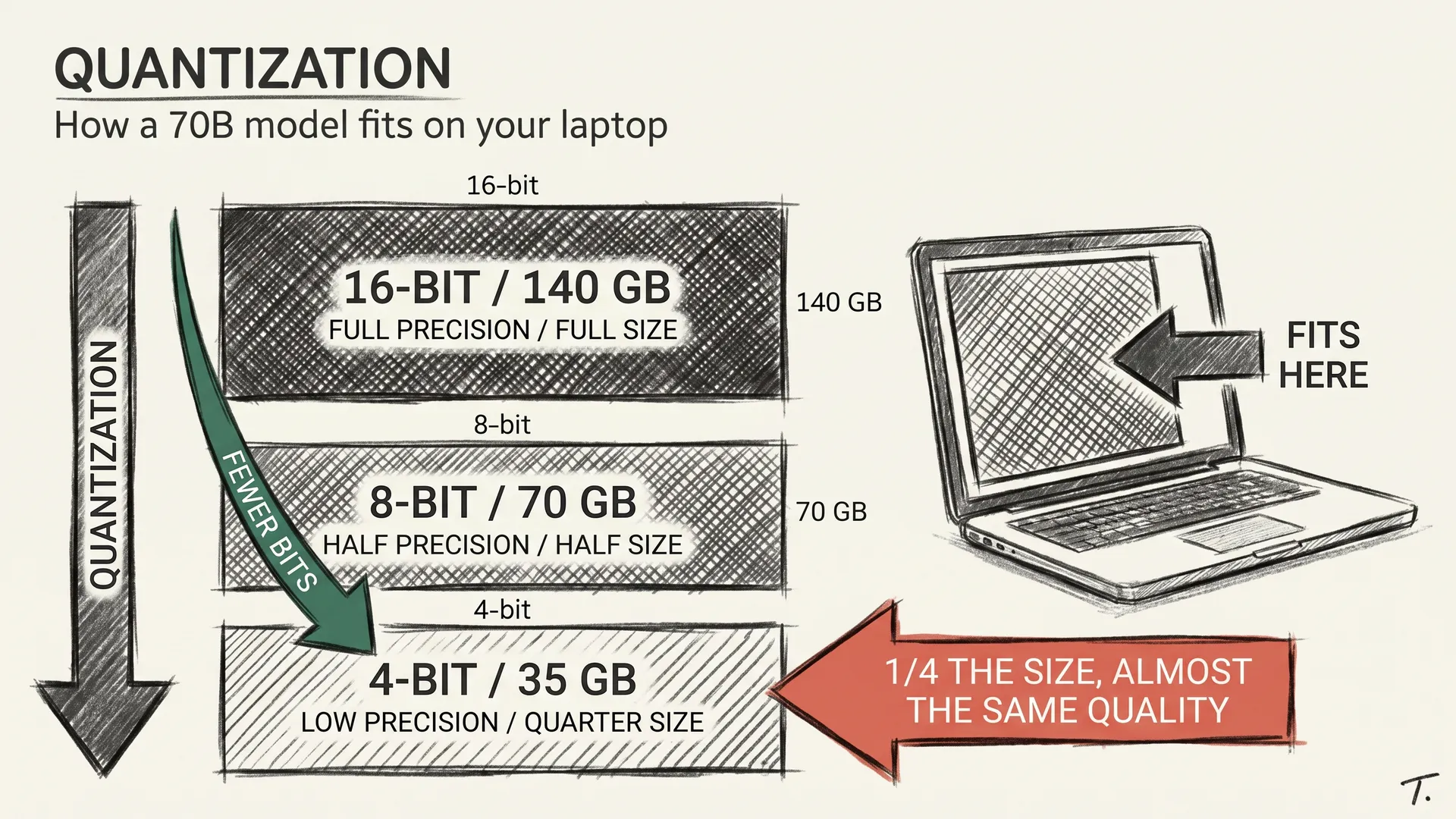
llm-concepts7 min readQuantization: How a 70B Model Fits on Your Laptop
Quantization shrinks a 70B model from 140 GB to 20 GB with almost no quality loss. What it actually does, and why the trick works.
-
 ai8 min read
ai8 min readAI Inference and Scaling: From Training to Serving Billions
How trained AI models serve billions of requests through inference optimization, scaling infrastructure, and cost engineering.