You type a question into ChatGPT, hit enter, and words start appearing on screen as if someone is typing back to you. Coherent sentences. Structured arguments. Sometimes even jokes.

The whole experience feels like talking to something that understands you, and that feeling is exactly what makes these systems so fascinating and so misunderstood. In the previous article, Neural Networks: How AI Mimics the Brain, we built the foundation: layers of simple math learning patterns from data. Now we are going to take those ideas and scale them up by several orders of magnitude, because that is exactly what a large language model does.
The jump from a basic neural network to a modern LLM is like going from a hand-drawn map to a real-time satellite view of Earth. Same underlying principle. Wildly different capability. So how does a large language model actually work, and how does it produce text that sounds like a human wrote it?
THE SCALE OF IT ALL.
The word large is doing serious work in large language model. These models contain billions of parameters, the internal numbers that training adjusts over time. Early language models had millions; GPT-3 had 175 billion; current frontier models top a trillion.
Think of each parameter as a tiny dial on a mixing board with a billion channels. Training tweaks each dial through exposure to enormous amounts of text until the board collectively captures how language behaves. That sheer number of dials, combined with the volume of training data, is what separates an LLM from the autocomplete on your phone.
Here is the wild part. Scaling up parameters and training data produces capabilities that simply do not exist at smaller sizes: reasoning across multiple steps, translating between languages the model barely saw during training, solving math problems by working through them sequentially. Researchers call these emergent capabilities because nobody explicitly programmed them in. They showed up once the models got big enough, like how water does not become a wave until you have enough of it.
TURNING WORDS INTO NUMBERS.
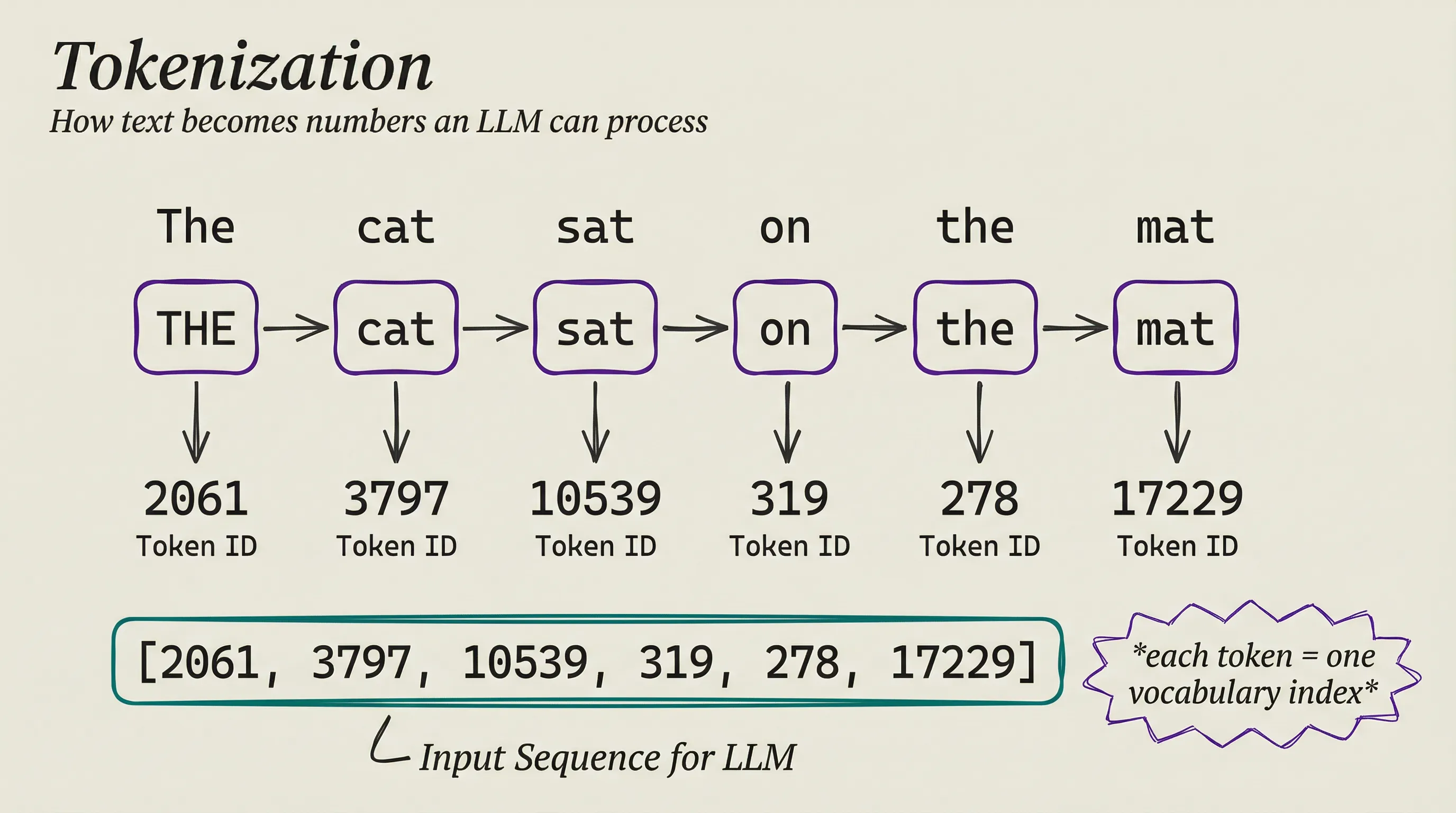
A neural network cannot read English. It lives in the world of numbers. So the first thing an LLM does is convert your text into numbers through a process called tokenization.
The model does not work with whole words or individual letters. Instead, it breaks text into tokens, chunks somewhere in between. Common words like the or and get their own token. Less common words get split into pieces: unhappiness might become three tokens, roughly un, happi, and ness.
Most modern LLMs use a method called byte-pair encoding, which builds a vocabulary by repeatedly merging the most frequent pairs of characters in training data. The result is a vocabulary of roughly 50,000 to 100,000 tokens that can represent virtually any text in any language. Your sentence becomes a sequence of token IDs. Just numbers in a list.
GIVING TOKENS MEANING.
Having token IDs is a start, but the number 4,827 does not inherently mean anything. This is where embeddings come in.
Each token gets mapped to a high-dimensional vector, a list of hundreds or thousands of numbers that represent its meaning in a kind of mathematical space. Words with similar meanings end up close together. King and queen sit near each other, dog and cat sit near each other, and dog and democracy sit far apart.
Here is my favorite example: the vector for king minus man plus woman produces a vector close to queen. Through pure pattern recognition on text, the model develops something that looks a lot like an understanding of analogies. I think that is genuinely impressive, even after years of working with these systems. Every token in your input gets converted to one of these vectors, and from that point forward, the model is doing math on meaning.
THE TRANSFORMER: ATTENTION IS ALL YOU NEED.
This is the architectural breakthrough that made modern LLMs possible. Before 2017, language models processed text one word at a time, left to right. Painfully slow. Hard to capture long-range relationships.
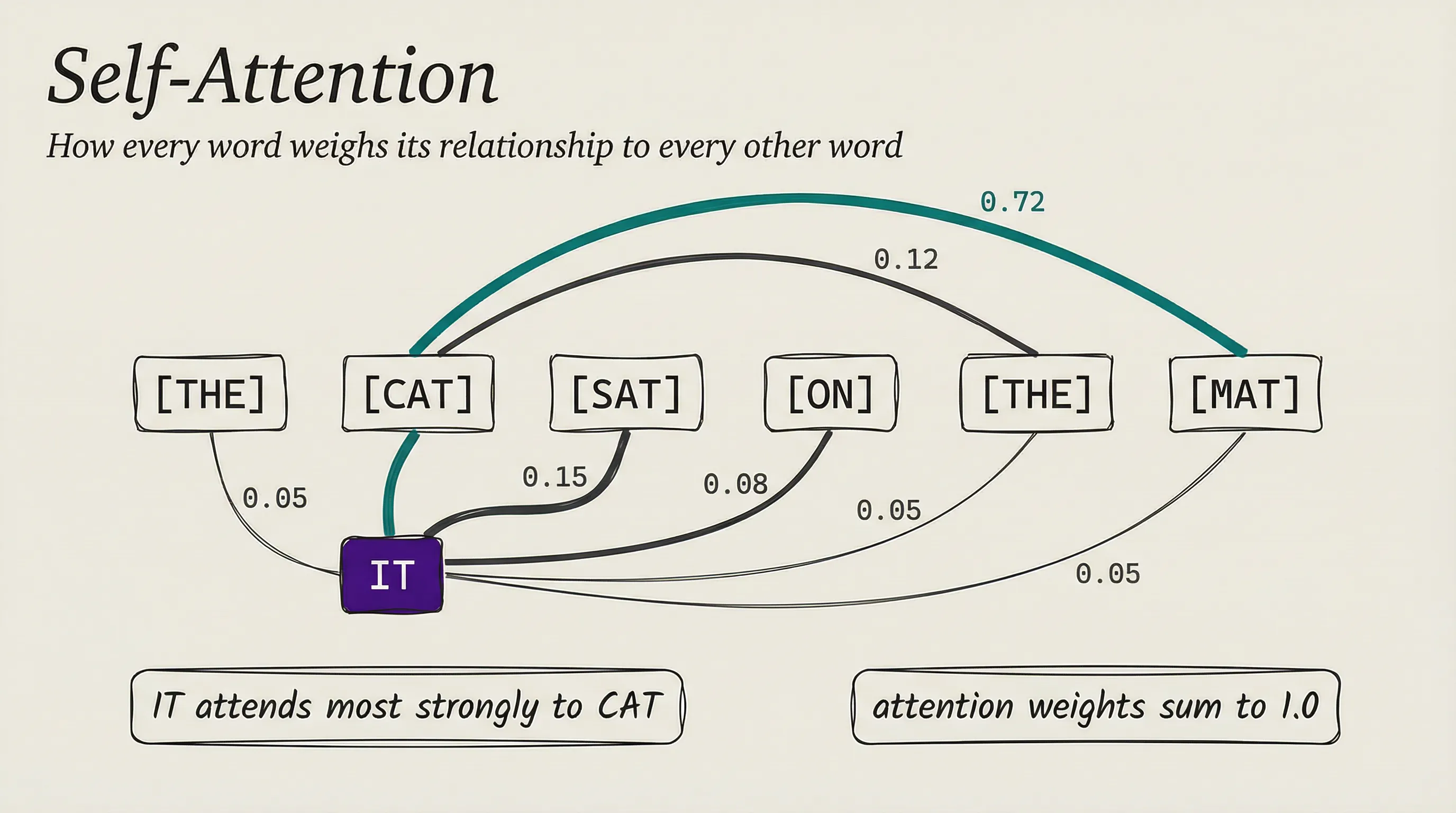
The transformer architecture, introduced in a now-famous research paper, threw that approach out entirely. Instead of reading sequentially, a transformer looks at all the tokens in the input at once and figures out which ones are most relevant to each other. We call this mechanism self-attention.
Think about it this way. Read the sentence The cat sat on the mat because it felt sleepy. When you hit the word it, your brain instantly connects it back to cat, not mat. You do not even think about it.
Self-attention does the same thing, but mathematically: it computes scores that determine how much each token should attend to every other token.
For each token, the model computes three things: a query representing what it is looking for, a key representing what it contains, and a value representing the information it carries. It then compares every token’s query against every other token’s key to produce attention weights. The result is that each token gets a new representation informed by every relevant token in the sequence.
The model runs multiple attention heads in parallel, so different heads can track different types of relationships simultaneously. One head might focus on grammatical structure, another on semantic meaning, another on positional proximity. It is like having several readers go through the same text, each looking for something different, then combining their notes.
PREDICTING THE NEXT TOKEN.
Here is the part that surprises most people. The core task of an LLM during training is almost embarrassingly simple: given a sequence of tokens, predict the next one. That is it.
The model reads billions of pages of text from the internet, books, code, and conversations. For each position in each piece of text, it tries to guess what comes next. When it guesses wrong, it adjusts its parameters slightly. Over trillions of these tiny adjustments, it gets extraordinarily good at prediction.
But here is the thing that took me a while to fully appreciate. To predict the next word accurately across text as diverse as Shakespeare, Python code, legal contracts, and Reddit threads, the model has to develop internal representations of grammar, facts, reasoning patterns, tone, and style. Prediction is the training objective. Understanding is the side effect.
When you use an LLM, it generates text one token at a time, each time picking the most promising candidate for what comes next, then feeding that prediction back as input for the following token. Its own output becomes its input for the next step. The snake eats its own tail, one word at a time.
FROM RAW MODEL TO HELPFUL ASSISTANT.
A model that just predicts the next token is powerful but not particularly useful as a conversational tool. It might complete your sentence with something factually wrong, offensive, or just bizarre, because it learned from the entire internet. Let’s be honest, the internet is not exactly a paragon of quality information.
The first stage is pre-training: the model reads massive amounts of text and learns to predict tokens. This gives it broad knowledge and language ability, but no sense of what a good answer looks like. The second stage is fine-tuning: trainers feed the model curated examples of helpful, high-quality conversations, teaching it the format and style of being an assistant.
The third stage is reinforcement learning from human feedback, or RLHF. Human evaluators rank different model outputs from best to worst, and those rankings train a separate reward model that scores how good a response is. The LLM then gets optimized to produce responses that score highly on this reward model.
RLHF is the step that transforms a raw text-prediction engine into something that feels genuinely helpful. It is also the most philosophically interesting step, because you are teaching the model human values through example rather than explicit rules.
TEMPERATURE AND THE ART OF RANDOMNESS.
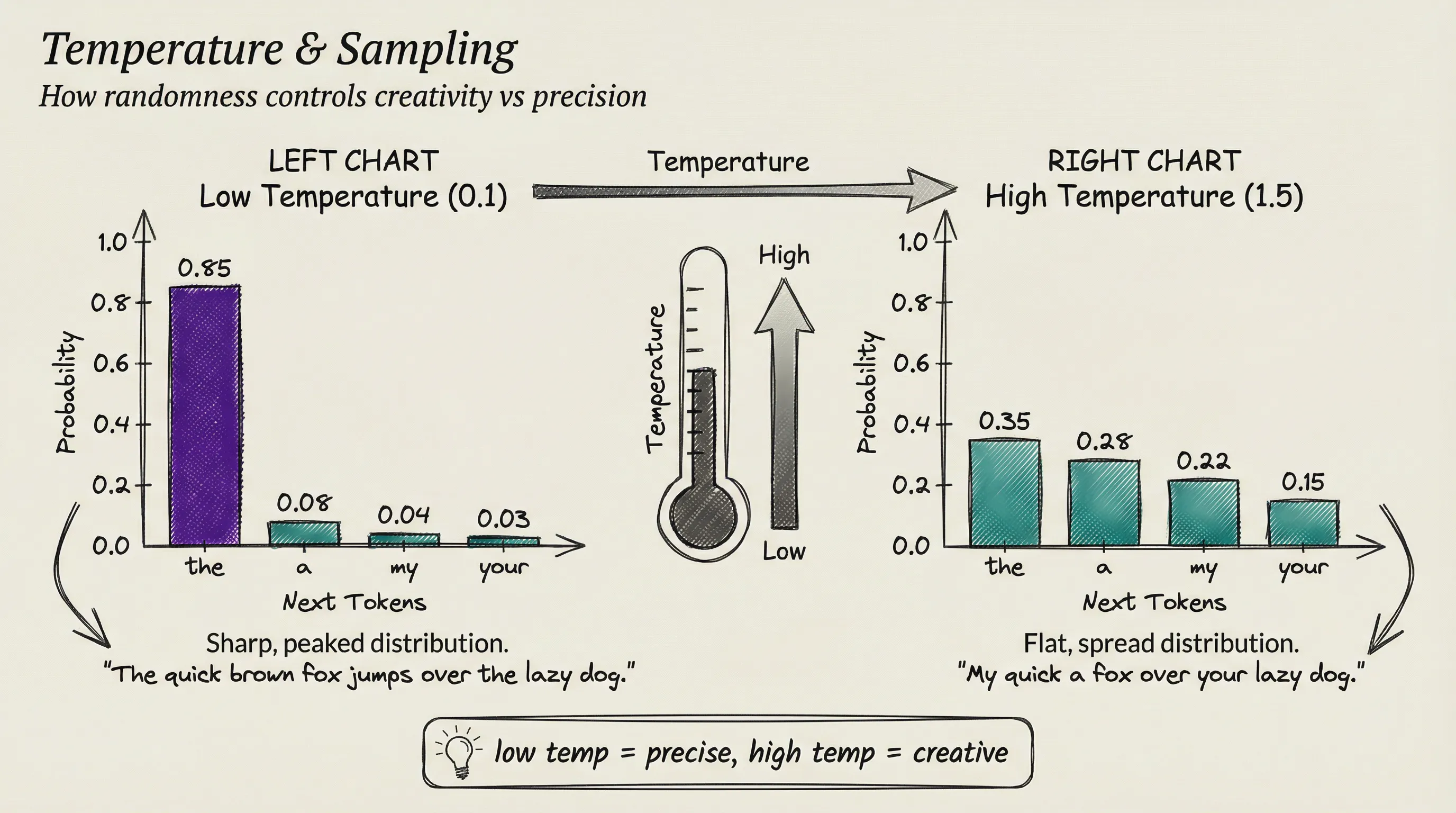
When the model predicts the next token, it does not just pick the single most likely one. It produces a probability distribution over its entire vocabulary: the word the might have a 15% chance of being next, a might have 8%, my might have 3%, and so on across tens of thousands of possibilities.
A setting called temperature controls how the model samples from this distribution. At low temperature, the model almost always picks the highest-probability token, producing safe, predictable text. At higher temperatures, it reaches for lower-probability tokens more often, producing more creative output but risking incoherence.
Imagine a cautious writer who always picks the safe word versus a poet who sometimes grabs the unexpected one. Temperature is the dial between them.
There are also techniques like top-k sampling, which only considers the top K most likely tokens, and nucleus sampling, which only considers tokens above a cumulative probability threshold. These controls are why the same prompt can produce different responses each time you ask. The model is not being inconsistent; it is sampling from a distribution, and temperature decides how adventurous that sampling gets.
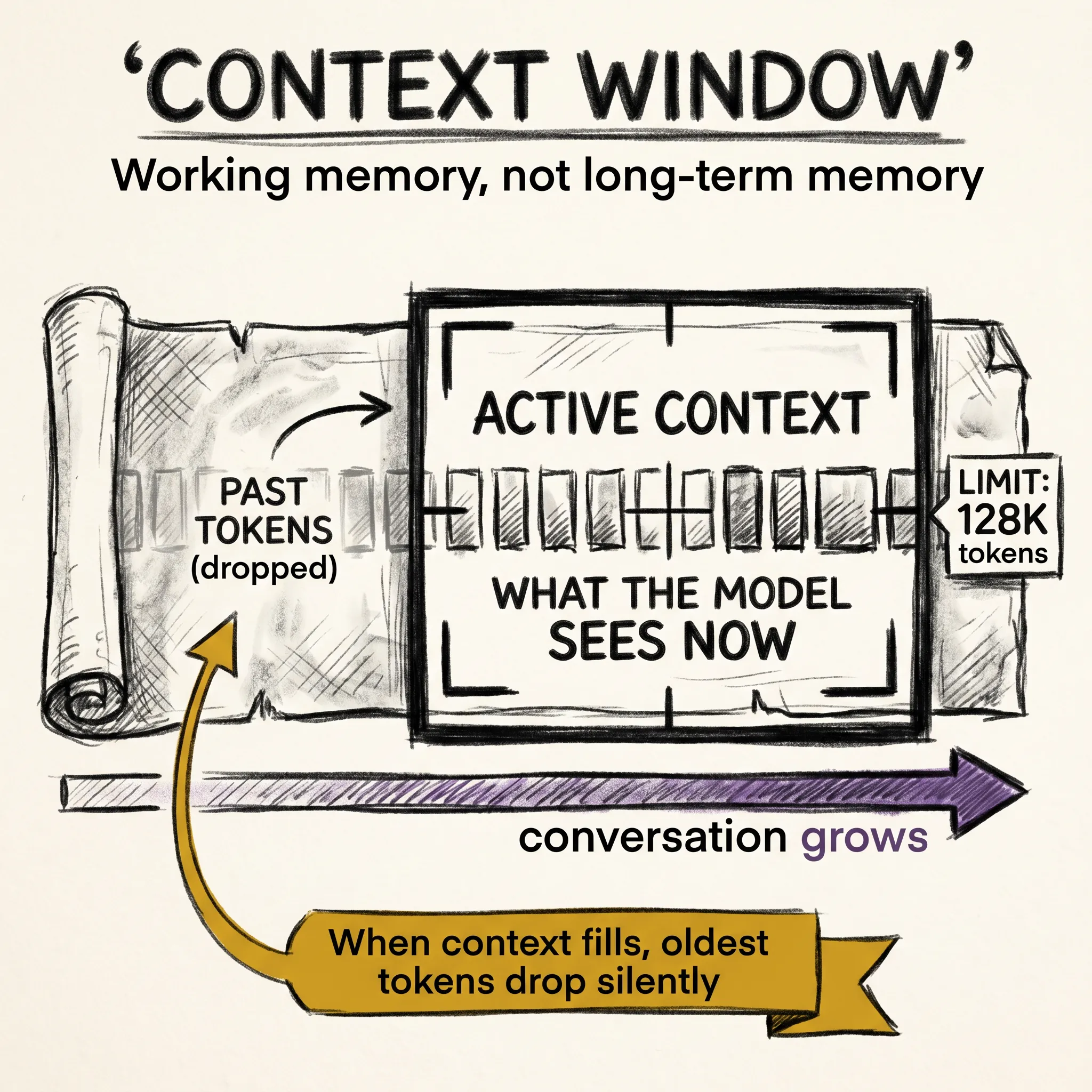
THE CONTEXT WINDOW: WHAT AN LLM CAN SEE.
Every LLM has a limit on how much text it can consider at once, called the context window, measured in tokens. Early models had context windows of a few thousand tokens, maybe a couple pages of text. Modern models have pushed this dramatically: some handle 128,000 tokens, others go up to one or two million.
But bigger is not automatically better. There is a meaningful difference between a model’s maximum context window and its effective context window, the amount of text it can actually use well. Models tend to pay the most attention to the beginning and end of their context, sometimes losing track of information buried in the middle. It is like reading a long book in one sitting: you remember the opening and the ending, but the details from chapter seven get hazy.
The context window also explains why LLMs forget things in long conversations. Once the conversation exceeds the window, the earliest parts get dropped. The model is not choosing to forget. It literally cannot see that text anymore.
WHAT THIS ALL ADDS UP TO.
You type a question. That text gets split into tokens, converted to embedding vectors, processed through dozens of transformer layers where self-attention figures out how every piece relates to every other piece, and finally the model produces a probability distribution over what token should come next. It picks one, appends it, and repeats.
Each token takes into account everything that came before it, up to the limit of the context window. The result is coherent, contextually appropriate text, all produced by a system whose entire training objective was: predict the next token.
That is how a large language model works. Not magic, not true understanding in the way humans experience it, but a pattern-matching engine of extraordinary sophistication. One that has consumed more text than any human could read in a thousand lifetimes, and yet its core operation is humblingly simple: guess the next word, adjust, repeat. In the next article, we will look at how these models are showing up in the real world, the ecosystems growing around them, and what happens when this technology reaches millions of people.
T.
References
-
Attention Is All You Need, Vaswani 2017 - The original transformer paper introducing the self-attention architecture behind all modern LLMs.
-
RLHF 101, CMU ML Blog - Walkthrough of reinforcement learning from human feedback for aligning language models.
-
The Illustrated Transformer, Jay Alammar - One of the best visual explanations of how the transformer architecture and attention mechanism work.
-
Understanding Byte Pair Encoding in Large Language Models, Vizuara - A clear explanation of BPE tokenization and how modern LLMs convert text into numerical tokens.
-
LLMs with Largest Context Windows, Codingscape - A comparison of context window sizes across frontier models, including effective versus maximum context length.
-
Neural Networks: How AI Mimics the Brain - The previous article in this series covering neural network fundamentals.