Traditional software follows rules a programmer writes. If the temperature is above 30 degrees, turn on the air conditioning. If the email contains free money, mark it as spam. Every rule is explicit, hardcoded in advance.
Machine learning flips this. Instead of writing rules, you show the computer thousands of examples and let it figure out the rules on its own.
Show it 10,000 emails labeled spam and 10,000 labeled not spam. The computer finds patterns: certain words, certain senders, certain formatting tricks. It writes its own rules, and those rules are often better than anything a human could write by hand.

The first ten articles covered the physical stack: electricity, silicon, CPUs and GPUs, data centers, the internet, software, algorithms, and databases. This article is where the stack starts to do something that looks like thinking.
LEARNING TO THROW DARTS
Think of machine learning like learning to throw darts. You throw your first dart. It hits the wall two feet left of the board. You adjust.
The next dart hits the board but misses the bullseye by a foot. Adjust again. Throw again. After 1,000 throws, you’re consistently hitting near the center.
Nobody gave you explicit rules about arm angle, release point, or force. You learned by trying, observing the result, and adjusting.
That’s machine learning in four words: try, observe, adjust, repeat.
Traditional programming takes rules plus data and produces results. Machine learning takes data plus desired results and produces rules. One approach is explicit; the other learns. One breaks on edge cases; the other generalizes.
THE THREE TYPES OF LEARNING
Supervised Learning
You give the computer input-output pairs: this email is spam, this image is a cat, this house is worth $350,000. The computer learns to predict the output from the input.
Two main flavors: classification predicts categories (spam or not spam, benign or malignant, fraudulent or legitimate), while regression predicts numbers (what will this house sell for, how many units will we sell next quarter).
In both cases the process works the same. Give the model thousands of labeled examples, let it find patterns, then use those patterns to predict labels for new data.
Unsupervised Learning
Sometimes you don’t have labels. You just have data and want to find structure in it.
Clustering groups similar items together. Give an algorithm one million customer records and it might discover five distinct customer segments based on purchasing patterns, with no human defining what those segments should be. Think of it as the computer finding the natural grain of the data the way a geologist reads layers in rock.
Dimensionality reduction compresses data while preserving structure, making it easier to visualize and faster to process.
Reinforcement Learning
An agent takes actions in an environment and receives rewards or penalties. A chess-playing AI makes moves and receives feedback: win, lose, or draw. Over millions of games, it learns which moves lead to wins.
Reinforcement learning trained AlphaGo to beat world champions at Go and teaches robots to walk and grasp objects. It’s also part of how ChatGPT learned to be helpful, which Article 14 will cover in detail.
HOW MODELS ACTUALLY LEARN: THE BLINDFOLDED HIKER
Imagine you’re blindfolded on a hilly terrain, trying to find the lowest valley. You can’t see anything. But you can feel the ground under your feet.
So you feel which direction slopes downward most steeply, take a step in that direction, feel again, and repeat. Eventually the ground feels flat in every direction. You’ve found a valley.
This is gradient descent. The hiker is the model. The terrain represents all possible combinations of the model’s settings, which go by the name weights or parameters. The elevation is the loss function: a score measuring how badly the model’s predictions miss the correct answers.
Higher elevation means worse predictions. Valleys mean good predictions. The goal is to find the lowest valley.
The learning rate is the step size. Take steps that are too large and you sprint past the valley, bouncing back and forth on the slopes forever. Take steps that are too small and training takes weeks instead of hours.
Think of it as the difference between hiking confidently downhill and shuffling a millimeter at a time. Both get you there, but only one gets you there this century.
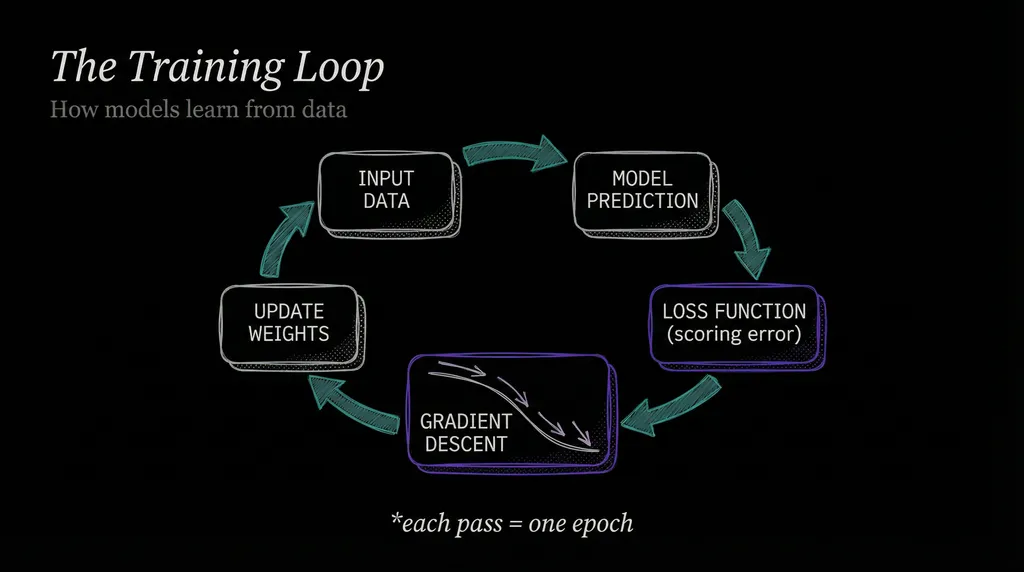
In Article 9, I described gradient descent briefly as part of the algorithms picture. Here’s the full training loop it powers.
First, feed the model an input: an email, an image, a data point. The model outputs a prediction with its current settings, which start out random.
The loss function scores how wrong the prediction was. Gradient descent then calculates which direction to nudge the settings to reduce that score.
The settings shift slightly in that direction, scaled by the learning rate. Then repeat with the next batch of data.
One pass through the entire training dataset goes by the name epoch. Models typically train for dozens to hundreds of epochs. By the end, the settings shift millions of times toward fewer errors.
THE HARDWARE CONNECTION
Why does any of this require the GPU infrastructure from Articles 4 and 5? Because gradient descent runs on matrix multiplication, and GPUs are purpose-built for matrix multiplication.
Think of a CPU as a single expert who handles one task at a time with great precision. A GPU is more like a stadium full of workers, each doing one simple calculation simultaneously. For matrix multiplication specifically, a GPU can be hundreds of times faster than a CPU performing the same calculation sequentially.
That gap makes the difference between a training run that takes three days and one that takes 50 years.
Since 2012, compute used for the largest ML training runs has doubled roughly every 3.4 months. That’s over 300,000x growth in a decade. The GPU clusters from Article 5 exist almost entirely because of this demand.
A 10,000-GPU training cluster consumes 10 to 15 megawatts, enough to power a small city’s worth of homes. The connection between the algorithm and the hardware is direct: better GPUs made better models possible, and better models demanded more GPUs.
REAL-WORLD ML IN ACTION
The most interesting ML examples from the last two years aren’t the ones you’d expect.
Google DeepMind’s GraphCast produces a 10-day global weather forecast in under one minute on a single chip. Traditional weather models run on supercomputers and take hours to produce less accurate results. GraphCast outperforms the industry-standard European model on 90% of 1,380 verification targets.
Its 2024 successor, GenCast, adds probabilistic forecasting. Instead of a single predicted temperature, you get the full range of possible outcomes. Weather forecasting had improved incrementally for decades; ML transformed it in a few years.
AlphaFold earned its creators the 2024 Nobel Prize in Chemistry. Its latest version, AlphaFold 3, predicts how proteins fold into three-dimensional shapes, with 50% better accuracy than previous methods for interactions between proteins and the small molecules that drugs contain.
Scientists have already used it to identify drugs that might work against Chagas disease, which infects 7 million people annually and has few treatment options. The protein folding problem sat unsolved for 50 years. ML solved it in less than a decade of serious effort.
Spam filters are the unglamorous example, but they illustrate scale. Gmail’s spam filter analyzes hundreds of features per email: sender reputation, word patterns, link analysis, formatting cues. Accuracy exceeds 99.9%, with no human-written rules defining what spam is.
Fraud detection runs in milliseconds. Banks train models on millions of transactions, both legitimate and fraudulent. The model learns to recognize patterns in locations, amounts, timing, and merchant types without anyone specifying what unusual means. Decisions often complete before a transaction does.
WHY DATA QUALITY TRUMPS EVERYTHING
Here’s the thing nobody mentions in the excitement about AI: building ML systems is mostly data work.
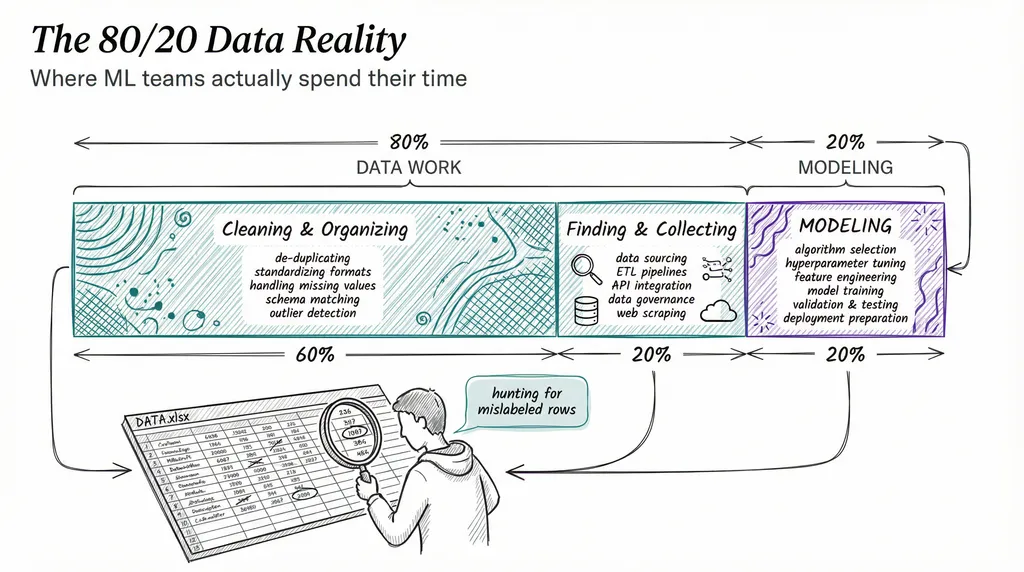
Data scientists spend roughly 80% of their time finding, cleaning, and organizing data. Only 20% goes to actual modeling. Within that 80%, about 60% goes to cleaning and organizing specifically.
If you’re picturing ML teams hunched over equations, the reality is closer to them hunting for mislabeled rows and missing values in spreadsheets.
Andrew Ng, who built ML systems at Google Brain and Baidu, ran experiments comparing model improvement against data improvement. For a steel defect detection task, improving the model produced no accuracy gains. Improving data quality boosted accuracy by 16 percentage points.
His conclusion: 50 thoughtfully curated, correctly labeled examples can outperform thousands of noisy ones.
Bad data creates bad models in predictable ways. Amazon built a hiring tool trained on historical resumes. Since a decade of historical hiring skewed male, the model learned that pattern and rated female applicants lower. Not because anyone programmed bias in, but because the bias lived in the data and the model learned the data faithfully.
Amazon scrapped the tool in 2018. Medical imaging models trained primarily on lighter-skinned patients show lower accuracy for darker-skinned patients. The pattern repeats: models reflect their training data, including its gaps and distortions.
The companies with the best AI often hold the best data, not the best algorithms. Algorithm improvements appear in papers and become available to everyone. Data advantages stay private and resist replication.
OVERFITTING: THE BIGGEST TRAP
Imagine a student who memorizes every answer in the practice exam but cannot solve new problems. That’s overfitting.
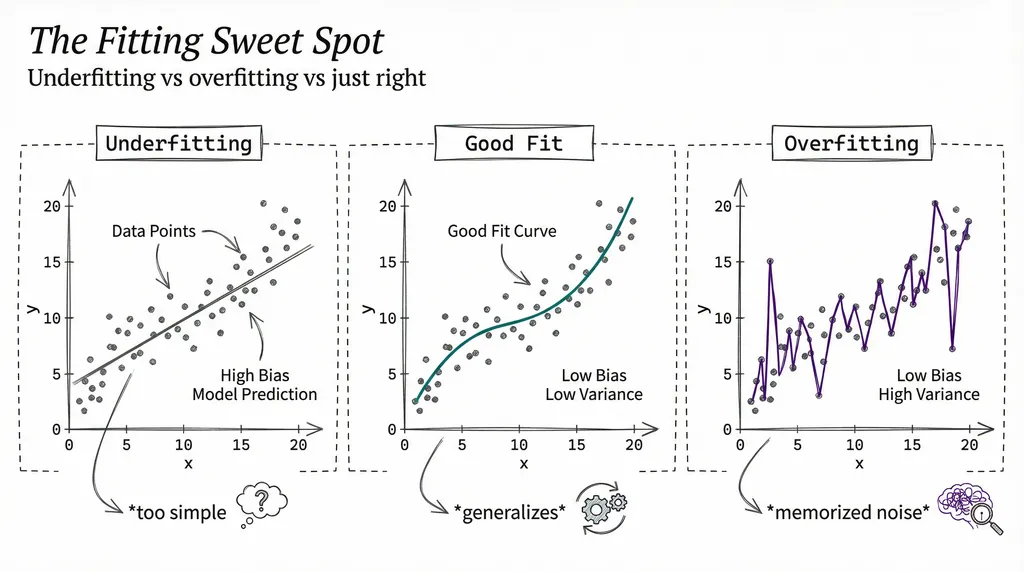
An overfitting model performs brilliantly on training data and terribly on new data. It memorized the training examples instead of learning general patterns. The telltale sign: 99% accuracy on training data, 60% on data the model has never seen before.
Three main defenses: First, the train/test split. You set aside 20% of data that the model never sees during training, then measure performance on that held-out test set. Second, regularization penalizes overly complex models and forces simpler patterns. Third, more data: with enough diverse examples, the model cannot memorize everything and must generalize.
The opposite problem is underfitting: the model is too simple to capture the real patterns. A straight line cannot fit a curved relationship. The fix is usually clear: use a more complex model or train for more epochs.
The art of ML is finding the sweet spot between these two failure modes: complex enough to learn real patterns, simple enough to generalize.
WHAT ML IS NOT
A few corrections worth making explicitly, because the misconceptions shape a lot of confused thinking about AI.
ML models do not understand anything. They identify statistical patterns in numbers. When a model correctly labels a photo of a cat, it found that certain pixel patterns correlate with the label cat in its training data. There’s no understanding of what a cat is, no concept of furriness or meowing or hunting mice.
This sounds philosophical, but it has practical consequences. Models fail in ways that would never fool a human, because humans use understanding while models use pattern matching.
More data isn’t always better. Biased data at scale amplifies bias, not accuracy. Noisy data at scale teaches the model to fit the noise. Fifty carefully curated examples can outperform ten thousand sloppy ones, as Ng’s experiments showed.
Models also degrade over time. The real world changes: consumer behavior shifts, new fraud patterns emerge, language evolves. A model trained on 2022 data makes worse predictions in 2026 because the underlying patterns have drifted. Engineers call this concept drift.
It’s one of the main reasons production ML systems require ongoing monitoring and retraining. A model isn’t a finished product. It’s a snapshot of patterns that existed in data up to a certain point.
WHY THIS MATTERS
Machine learning changed software from do exactly what I say to figure out what I mean from examples. That shift has real consequences for how you interact with technology.
Every recommendation, search result, and spam filter you encounter comes from an ML model. When a product recommendation seems eerily accurate, that’s not telepathy: it’s a model that found your behavior pattern in a dataset of millions of similar users.
When a spam filter blocks a legitimate email, that’s overfitting or concept drift, not malice.
If you build software, ML is becoming a standard component. Knowing when to use it (pattern recognition in messy, high-dimensional data) versus traditional code (clear rules, deterministic logic) is increasingly a core judgment call rather than a specialty skill.
And if you think about fairness, understanding that models reflect their training data lets you ask the right questions: what data did this train on, who labeled it, and what patterns might it have inherited?
WHAT’S NEXT
Machine learning is the general principle: computers learn from data. The specific architecture that made modern AI what it is today is the neural network, layers of interconnected mathematical functions that learn arbitrarily complex patterns from raw inputs like images and text.
In Article 12, we’ll look at neural networks. How do artificial neurons work? What makes deep learning deep? And how did one particular architecture, the transformer, change everything?
T.
REFERENCES
-
Google DeepMind: GraphCast AI Model for Weather Forecasting - DeepMind’s announcement of GraphCast, which produces 10-day global forecasts in under one minute and outperforms ECMWF HRES on 90% of verification targets
-
MIT Sloan: Why It’s Time for Data-Centric Artificial Intelligence - Andrew Ng’s case for prioritizing data quality over model complexity, including the steel defect study showing 16% accuracy gains from better data
-
DeepMind: AlphaFold Five Years of Impact - Overview of AlphaFold’s development and real-world applications, including drug repurposing for neglected diseases and the 2024 Nobel Prize in Chemistry
-
IBM: What Is Gradient Descent - Clear technical explanation of gradient descent, loss functions, and learning rates
-
IBM: Why GPUs for Deep Learning - How GPU parallel cores outperform CPUs for the matrix operations that drive ML training
-
Epoch AI: Can AI Scaling Continue Through 2030 - Analysis of compute growth trends: 3.4-month doubling time since 2012, over 300,000x total growth