Posts
All the articles I've posted.
-
 ai2 min read
ai2 min readAI Digest W26: Securing the Agents
AI security ran the week, from DeepMind's agent control roadmap to prompt injection as role confusion, while GLM-5.2 narrowed the open versus closed gap.
-
 ai2 min read
ai2 min readAI Digest W25: When the Government Pulls a Model
The US government forced Anthropic to suspend its strongest models, while open weights from MiniMax and Ai2 pushed capability the other way.
-
 ai2 min read
ai2 min readAI Digest W24: Going Public, Holding Back
OpenAI files for its IPO, Anthropic ships Claude Fable 5 with new safety brakes, Apple rebuilds Siri on Gemini, and agents reshape software.
-
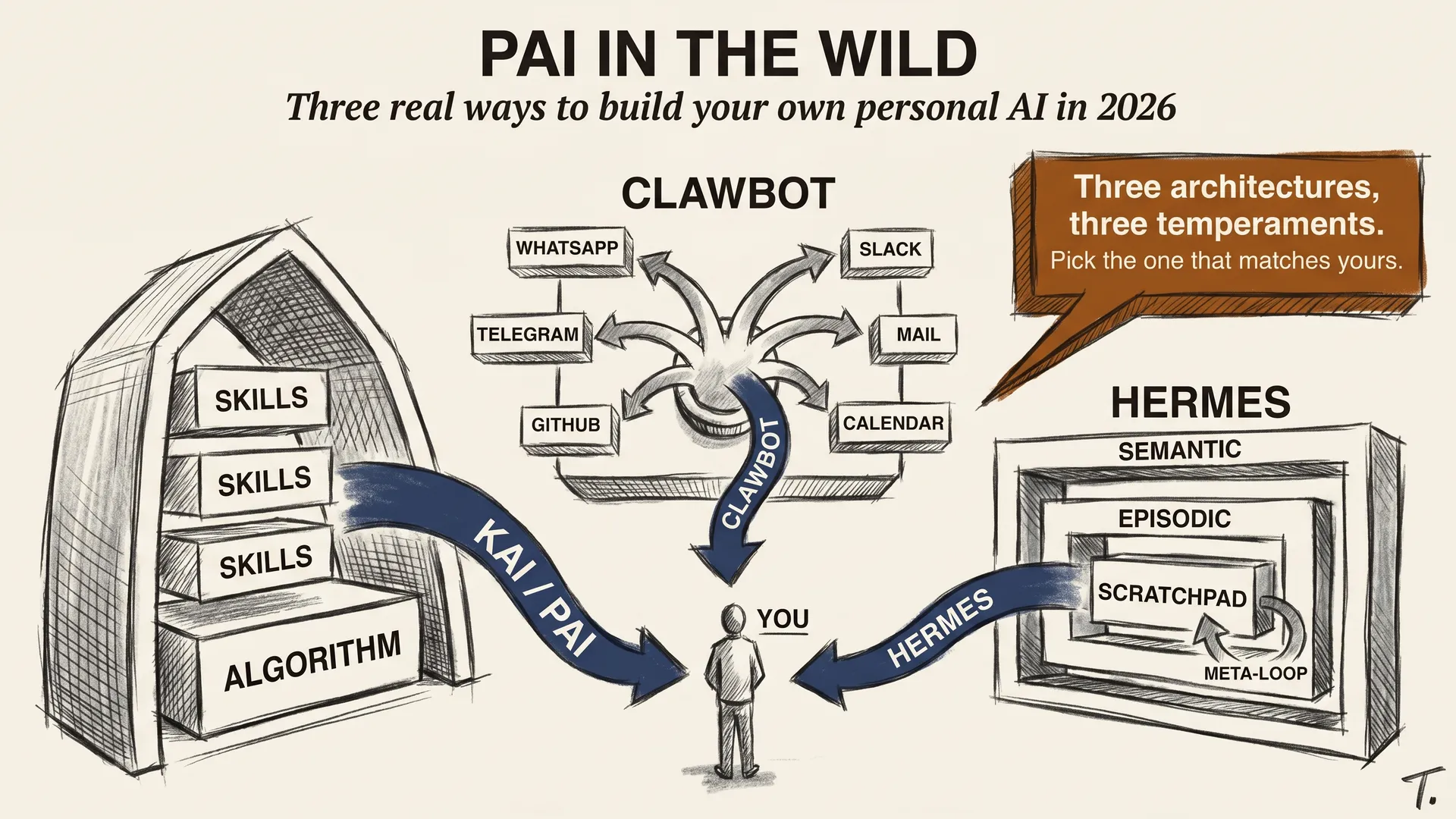 llm-concepts8 min read
llm-concepts8 min readPAI in the Wild: Three Ways to Build Your Own
Three real 2026 options for building a personal AI: Kai (the framework I use), Clawbot (integrations-first), and Hermes (self-improving).
-
 ai2 min read
ai2 min readAI Digest W23: The Coding Gold Rush
Claude Opus 4.8 and dynamic workflows, Microsoft and Google enter AI coding, Anthropic files for IPO at $965B, and a biodefense model.
-
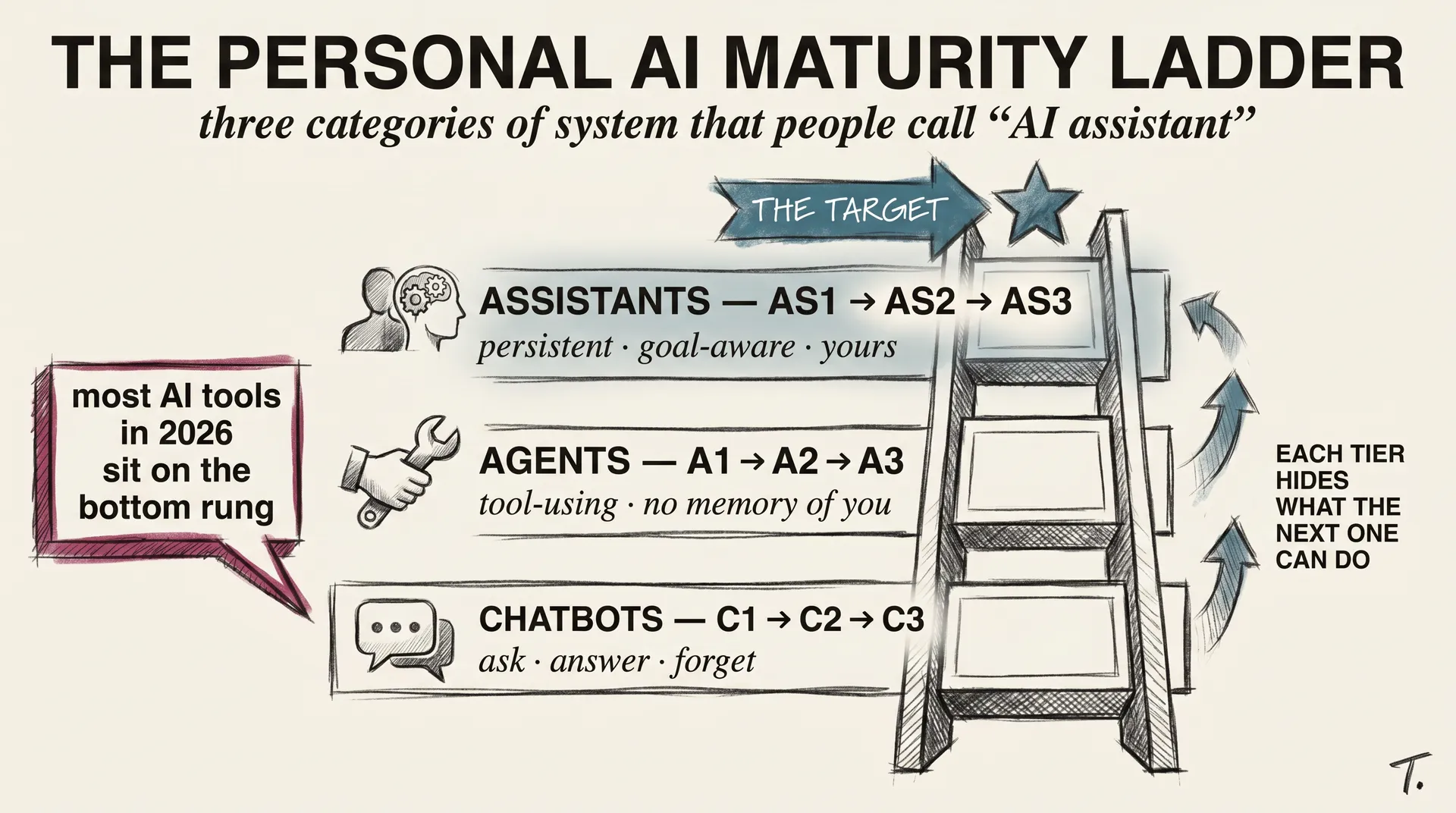 llm-concepts8 min read
llm-concepts8 min readPersonal AI Infrastructure: The Climb From Chatbot to Assistant
Most AI tools today are chatbots in a costume. The real ladder has three tiers, and 2026 finally made the top one buildable at home.
-
 ai2 min read
ai2 min readAI Digest W22: Compute Cash and Side Effects
Anthropic pays SpaceX $1.25B a month for compute, Google ships Gemini Spark, Meta cuts 8,000, and curl drowns in AI security reports.
-
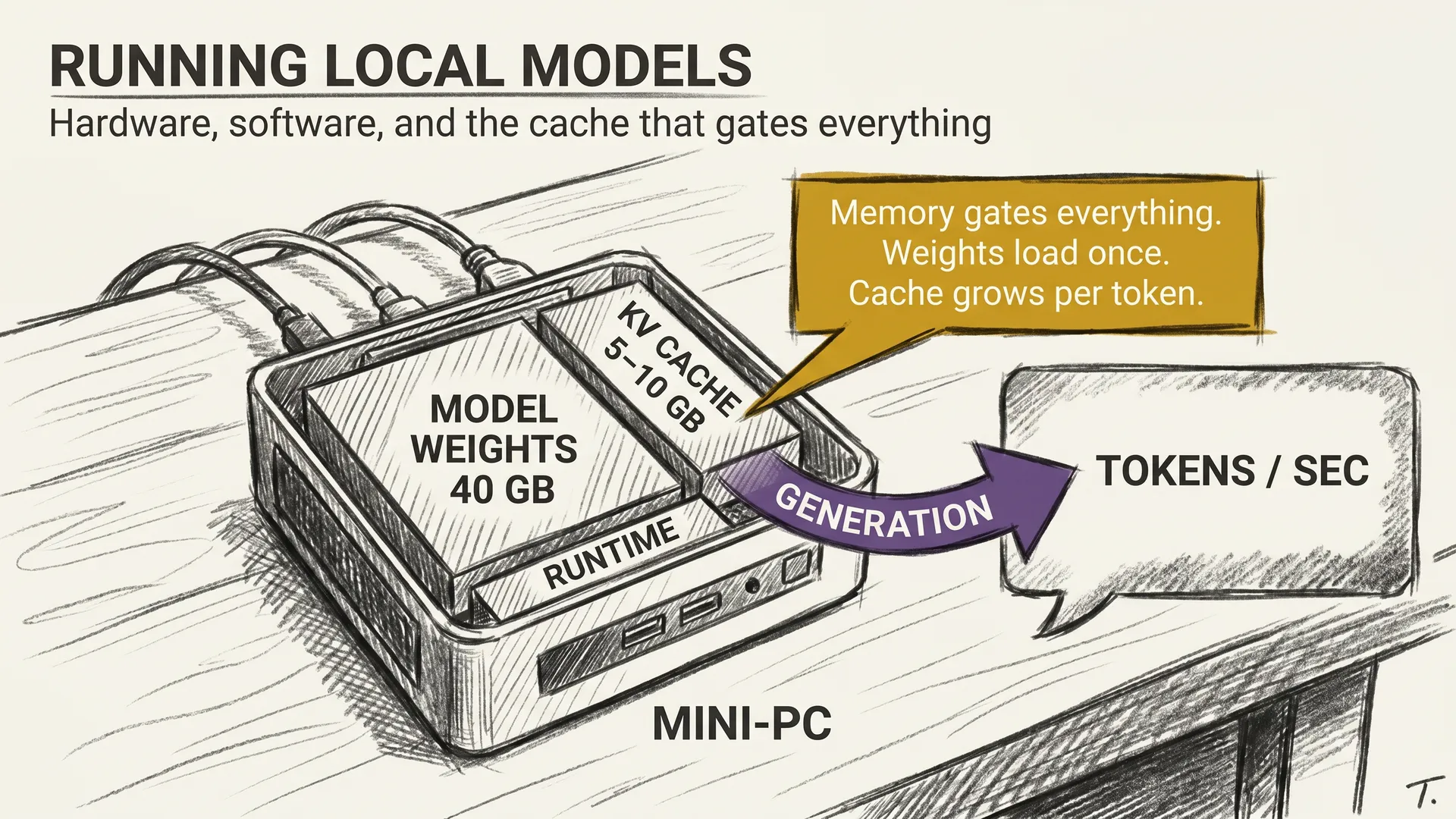 llm-concepts8 min read
llm-concepts8 min readRunning Local Models: What It Actually Takes
Quantization shrank the model down to 40 GB. Now what hardware, what software, and what setup actually run a 70B model at home in 2026?
-
 ai2 min read
ai2 min readAI Digest W20: Compute Crunch and Big Checks
OpenAI says it may need more money for compute, Anthropic locks in 5GW with Amazon and writes a check with Gates, and GPT-5.5 lies less.